Table of contents
Preamble
We have seen in previous post how to create a shared storage for our Kubernetes nodes. Now let’s see what we need to create in k8s and how to use this persistent storage to create a stateful container.
Persistent Volume creation
I have spent quite a lot of time on this subject and digging a bit on Internet I have realized that it is apparently a tricky subject for lots of people.
Taking the list of available type of Persistent Volume (PV) I have realized that almost nothing can take into consideration the clustered file system I have created with OCFS2:
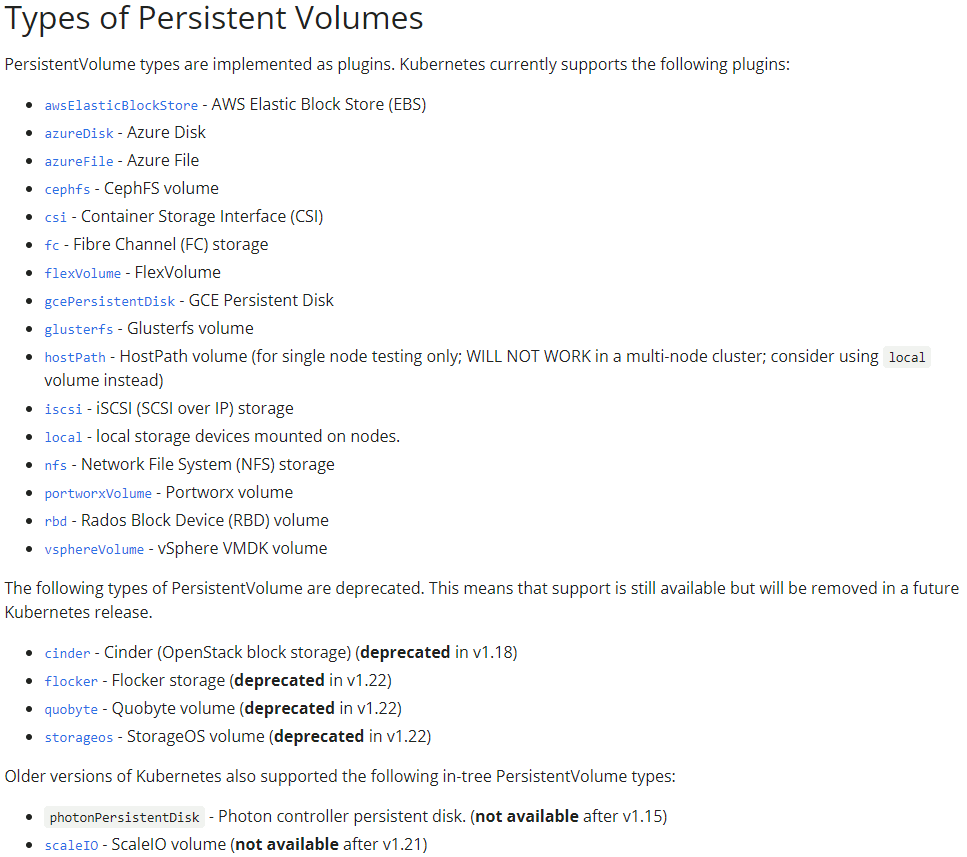
The only option would be to use local for local storage but my shared storage is a bit more advanced because I do not loose it when the node is down and it is accessible from all Kubernetes cluster nodes.
In a more real life scenario you may consider fiber channel (FC) coming from SAN, iSCSI or even Container Storage Interface (CSI) with the right plugin. For sure one of the easiest if you have it in your company (all companies have more or less) is a NFS mount point. I will probably come back on his story later as my knowledge will increase about it…
Inspired by the official documentation I have the below yaml file (pv.yaml):
apiVersion: v1 kind: PersistentVolume metadata: name: postgres-pv-volume spec: capacity: storage: 1Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete storageClassName: local-storage local: path: /mnt/shared/postgres nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - server2.domain.com |
Load the definition with:
[root@server1 ~]# kubectl create -f pv.yaml persistentvolume/postgres-pv-volume created [root@server1 ~]# kubectl get pv -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE postgres-pv-volume 1Gi RWO Delete Available local-storage 3s Filesystem |
As my “local” storage is not really local, to recall I have create an OCFS2 cluster FS storage on a shared disk between my k8s nodes, in one of my trial I have tried to allow all nodes in nodeSelectorTerms property to be able to access the persistent volume. But it ended with a failing pod and this error:
[root@server1 ~]# kubectl describe pod/postgres-59b594d497-76mnk Name: postgres-59b594d497-76mnk Namespace: default Priority: 0 Node: <none> Labels: app=postgres pod-template-hash=59b594d497 Annotations: <none> Status: Pending IP: IPs: <none> Controlled By: ReplicaSet/postgres-59b594d497 Containers: postgres: Image: postgres:latest Port: <none> Host Port: <none> Args: -c port=5433 Environment: POSTGRES_PASSWORD: secure_password POSTGRES_DB: testdb Mounts: /var/lib/postgresql/datal from postgres-pv-claim (rw) /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-njzgf (ro) Conditions: Type Status PodScheduled False Volumes: postgres-pv-claim: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) ClaimName: postgres-pv-claim ReadOnly: false kube-api-access-njzgf: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 3s (x17 over 16m) default-scheduler 0/2 nodes are available: 2 node(s) had volume node affinity conflict. |
Persistent Volume Claim creation
To allow the pod to request physical storage you have to create a Persistent Volume Claim. To do this I have created below file (pvc.yaml):
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: postgres-pv-claim spec: storageClassName: local-storage accessModes: - ReadWriteOnce resources: requests: storage: 100Mi |
Load the definition with:
[root@server1 ~]# kubectl apply -f pvc.yaml persistentvolumeclaim/postgres-pv-claim created [root@server1 ~]# kubectl get pvc -o wide NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE postgres-pv-claim Bound postgres-pv-volume 1Gi RWO local-storage 5s Filesystem |
PostgreSQL stateful deployment creation
To redeploy the PostgreSQL deployment using the persistent volume claim I have modified my yaml file to have something like:
apiVersion: apps/v1 kind: Deployment metadata: name: postgres namespace: default spec: replicas: 1 selector: matchLabels: app: postgres template: metadata: labels: app: postgres spec: containers: - image: postgres:latest name: postgres args: ["-c", "port=5433"] env: - name: POSTGRES_PASSWORD value: secure_password - name: POSTGRES_DB value: testdb volumeMounts: - mountPath: "/var/lib/postgresql/data" name: postgres-pv-claim restartPolicy: Always schedulerName: default-scheduler volumes: - name: postgres-pv-claim persistentVolumeClaim: claimName: postgres-pv-claim |
One beginner error I have done is to use the root mount point of my shared storage that obviously contains the lost+found directory. As such the PostgreSQL inintdb tool is not able to create the PostgreSQL database directory complaining the folder is not empty:
[root@server1 ~]# kubectl logs postgres-54d7bbfd6c-kxqhh The files belonging to this database system will be owned by user "postgres". This user must also own the server process. The database cluster will be initialized with locale "en_US.utf8". The default database encoding has accordingly been set to "UTF8". The default text search configuration will be set to "english". Data page checksums are disabled. initdb: error: directory "/var/lib/postgresql/data" exists but is not empty It contains a lost+found directory, perhaps due to it being a mount point. Using a mount point directly as the data directory is not recommended. Create a subdirectory under the mount point. |
Load this new deployment applying the yaml file with:
[root@server1 ~]# kubectl apply -f ~yjaquier/postgres.yaml |
The pod should be re-deployed and when the pod is running:
[root@server1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE httpd-757fb56c8d-7cdj5 1/1 Running 4 (2d18h ago) 6d23h nginx-6799fc88d8-xg5kd 1/1 Running 4 (2d18h ago) 7d postgres-54d7bbfd6c-jzmk2 1/1 Running 0 66s |
You should already see something created in /mnt/shared/postgres which is a good sign:
[root@server1 ~]# ll /mnt/shared/postgres/ total 78 drwx------ 6 systemd-coredump input 1848 Oct 21 12:50 base drwx------ 2 systemd-coredump input 1848 Oct 21 12:51 global drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_commit_ts drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_dynshmem -rw------- 1 systemd-coredump input 4821 Oct 21 12:50 pg_hba.conf -rw------- 1 systemd-coredump input 1636 Oct 21 12:50 pg_ident.conf drwx------ 4 systemd-coredump input 1848 Oct 21 12:55 pg_logical drwx------ 4 systemd-coredump input 1848 Oct 21 12:50 pg_multixact drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_notify drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_replslot drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_serial drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_snapshots drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_stat drwx------ 2 systemd-coredump input 1848 Oct 21 12:58 pg_stat_tmp drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_subtrans drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_tblspc drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_twophase -rw------- 1 systemd-coredump input 3 Oct 21 12:50 PG_VERSION drwx------ 3 systemd-coredump input 1848 Oct 21 12:50 pg_wal drwx------ 2 systemd-coredump input 1848 Oct 21 12:50 pg_xact -rw------- 1 systemd-coredump input 88 Oct 21 12:50 postgresql.auto.conf -rw------- 1 systemd-coredump input 28835 Oct 21 12:50 postgresql.conf -rw------- 1 systemd-coredump input 53 Oct 21 12:50 postmaster.opts -rw------- 1 systemd-coredump input 94 Oct 21 12:50 postmaster.pid |
PostgreSQL stateful deployment testing
I connect to the PostgreSQL database of my stateful pod, create a new table and insert a row into it:
[root@server1 ~]# kubectl exec -it postgres-54d7bbfd6c-jzmk2 -- /bin/bash root@postgres-54d7bbfd6c-jzmk2:/# su - postgres postgres@postgres-54d7bbfd6c-jzmk2:~$ psql --port=5433 --dbname=testdb psql (14.0 (Debian 14.0-1.pgdg110+1)) Type "help" for help. testdb=# create table test01(id integer, descr varchar(20)); CREATE TABLE testdb=# insert into test01 values(1,'One'); INSERT 0 1 testdb=# select * from test01; id | descr ----+------- 1 | One (1 row) testdb=# |
Now let’s delete the pod to let Kubernetes schedule a new one:
[root@server1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE httpd-757fb56c8d-7cdj5 1/1 Running 4 (2d19h ago) 7d1h nginx-6799fc88d8-xg5kd 1/1 Running 4 (2d19h ago) 7d1h postgres-54d7bbfd6c-jzmk2 1/1 Running 0 74m [root@server1 ~]# kubectl delete pod postgres-54d7bbfd6c-jzmk2 pod "postgres-54d7bbfd6c-jzmk2" deleted |
After a brief period a new pod has replaced the one we deleted:
[root@server1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE httpd-757fb56c8d-7cdj5 1/1 Running 4 (2d20h ago) 7d1h nginx-6799fc88d8-xg5kd 1/1 Running 4 (2d20h ago) 7d1h postgres-54d7bbfd6c-jc6t7 1/1 Running 0 6s |
Now let’s see if our table is still there:
[root@server1 ~]# kubectl exec -it postgres-54d7bbfd6c-jc6t7 -- /bin/bash root@postgres-54d7bbfd6c-jc6t7:/# su - postgres postgres@postgres-54d7bbfd6c-jc6t7:~$ psql --port=5433 --dbname=testdb psql (14.0 (Debian 14.0-1.pgdg110+1)) Type "help" for help. testdb=# select * from test01; id | descr ----+------- 1 | One (1 row) testdb=# |
Hurrah !! My test table is still existing and we have not lost anything so really the deployment is stateful which is the targeted scenario in the case of a database !
Other Persistent Volumes plugins trials
OpenEBS
OpenEBS (https://github.com/openebs/openebs) self-claim to be the most widely deployed and easy to use open-source storage solution for Kubernetes. Promising on the paper…
Following the installation guide I have done:
[root@server1 ~]# kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml namespace/openebs created serviceaccount/openebs-maya-operator created clusterrole.rbac.authorization.k8s.io/openebs-maya-operator created clusterrolebinding.rbac.authorization.k8s.io/openebs-maya-operator created customresourcedefinition.apiextensions.k8s.io/blockdevices.openebs.io created customresourcedefinition.apiextensions.k8s.io/blockdeviceclaims.openebs.io created configmap/openebs-ndm-config created daemonset.apps/openebs-ndm created deployment.apps/openebs-ndm-operator created deployment.apps/openebs-ndm-cluster-exporter created service/openebs-ndm-cluster-exporter-service created daemonset.apps/openebs-ndm-node-exporter created service/openebs-ndm-node-exporter-service created deployment.apps/openebs-localpv-provisioner created storageclass.storage.k8s.io/openebs-hostpath created storageclass.storage.k8s.io/openebs-device created |
Get Storage classes with (kubectl api-resources for a list of K8s resources):
[root@server1 ~]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE openebs-device openebs.io/local Delete WaitForFirstConsumer false 83s openebs-hostpath openebs.io/local Delete WaitForFirstConsumer false 83s |
OpenEBs created pods:
[root@server1 ~]# kubectl get pods -n openebs NAME READY STATUS RESTARTS AGE openebs-localpv-provisioner-6756f57d65-5nbf9 1/1 Running 3 (38s ago) 3m21s openebs-ndm-cluster-exporter-5c985f8b77-zvgm9 1/1 Running 3 (29s ago) 3m22s openebs-ndm-lspxp 1/1 Running 0 3m22s openebs-ndm-node-exporter-qwr4s 1/1 Running 0 3m21s openebs-ndm-node-exporter-xrgdm 0/1 CrashLoopBackOff 2 (27s ago) 3m21s openebs-ndm-operator-9bdd87f58-t6nx5 0/1 Running 3 (22s ago) 3m22s openebs-ndm-p77wg 1/1 Running 0 3m22s |
I had issues with the OpenEBS pods, plenty are constantly crashing and I have not been able to solve it…
Container Storage Interface (CSI) open-local
As documentation state, Container Storage Interface (CSI) is a standard to expose storage to containers. Based on this generic specification you can find multiple drivers that will implement various storage technologies. From the list of CSI drivers one kept my attention for my fake attached shared disks: open-local.
To install open-local I add to install Helm:
[root@server1 ~]# curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 [root@server1 ~]# ll total 16000 -rw-------. 1 root root 1897 Dec 10 2019 anaconda-ks.cfg -rw-r--r-- 1 root root 145532 Jul 15 14:20 certifi-2021.5.30-py2.py3-none-any.whl -rw-r--r-- 1 root root 35525 Jul 15 14:20 charset_normalizer-2.0.2-py3-none-any.whl -rw-r--r-- 1 root root 99 Jul 29 14:26 dashboard-adminuser.yaml -rw-r--r-- 1 root root 270 Jul 29 14:29 dashboard-authorization-adminuser.yaml -rw-r--r-- 1 root root 11248 Oct 22 14:20 get_helm.sh -rwxr-xr-x 1 root root 187 Oct 21 16:40 getscsi -rw-r--r-- 1 root root 1566 Oct 14 16:34 httpd.yaml -rw-r--r-- 1 root root 59633 Jul 15 14:20 idna-3.2-py3-none-any.whl -rw-r--r-- 1 root root 15893915 Jul 7 23:56 minikube-latest.x86_64.rpm -rw-r--r-- 1 root root 216 Aug 2 16:08 nginx.yaml -rw-r--r-- 1 root root 62251 Jul 15 14:20 requests-2.26.0-py2.py3-none-any.whl -rw-r--r-- 1 root root 138494 Jul 15 14:20 urllib3-1.26.6-py2.py3-none-any.whl [root@server1 ~]# chmod 700 get_helm.sh [root@server1 ~]# ./get_helm.sh Downloading https://get.helm.sh/helm-v3.7.1-linux-amd64.tar.gz Verifying checksum... Done. Preparing to install helm into /usr/local/bin helm installed into /usr/local/bin/helm |
To be honest the English version of the open-local installation guide is not very easy to follow. It is not really written but you need a zip copy of the GitHub project that you unzip in a folder of your control node. The customize the ./heml/values.yaml file to match your storage:
[root@server1 helm]# ll total 8 -rw-r--r-- 1 root root 105 Oct 14 14:03 Chart.yaml drwxr-xr-x 2 root root 275 Oct 14 14:03 crds drwxr-xr-x 2 root root 275 Oct 14 14:03 templates -rw-r--r-- 1 root root 1201 Oct 14 14:03 values.yaml [root@server1 helm]# vi values.yaml [root@server1 helm]# grep device: values.yaml device: /dev/sdb [root@server1 open-local-main]# helm install open-local ./helm NAME: open-local LAST DEPLOYED: Fri Oct 22 14:37:25 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None |
If you want to add later additional storage to the values.yaml file you can then “upgrade” your open-local installation with:
[root@server1 open-local-main]# helm upgrade open-local ./helm Release "open-local" has been upgraded. Happy Helming! NAME: open-local LAST DEPLOYED: Fri Oct 22 15:53:56 2021 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None [root@server1 open-local-main]# helm list NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION open-local default 2 2021-10-22 15:53:56.56525654 +0200 CEST deployed open-local-v0.2.2 |
Installation wen well:
[root@server1 ~]# kubectl get po -nkube-system -l app=open-local -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES open-local-agent-6d5mz 3/3 Running 0 10m 192.168.56.102 server2.domain.com <none> <none> open-local-agent-kd49b 3/3 Running 0 10m 192.168.56.101 server1.domain.com <none> <none> open-local-csi-provisioner-59cd8644ff-sv42x 1/1 Running 0 10m 192.168.56.102 server2.domain.com <none> <none> open-local-csi-resizer-554f54b5b4-6mzvz 1/1 Running 0 10m 192.168.56.102 server2.domain.com <none> <none> open-local-csi-snapshotter-64dff4b689-pq8r4 1/1 Running 0 10m 192.168.56.102 server2.domain.com <none> <none> open-local-init-job--1-59cnq 0/1 Completed 0 10m 192.168.56.101 server1.domain.com <none> <none> open-local-init-job--1-84j9g 0/1 Completed 0 10m 192.168.56.101 server1.domain.com <none> <none> open-local-init-job--1-nh6nn 0/1 Completed 0 10m 192.168.56.101 server1.domain.com <none> <none> open-local-scheduler-extender-5d48bc465c-cj84l 1/1 Running 0 10m 192.168.56.101 server1.domain.com <none> <none> open-local-snapshot-controller-846c8f6578-qbqgx 1/1 Running 0 10m 192.168.56.102 server2.domain.com <none> <none> [root@server1 ~]# kubectl get nodelocalstorage NAME STATE PHASE AGENTUPDATEAT SCHEDULERUPDATEAT SCHEDULERUPDATESTATUS server1.domain.com DiskReady Running 6s 9m16s server2.domain.com DiskReady Running 20s 8m49s |
All storage classes well created:
[root@server1 ~]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE open-local-device-hdd local.csi.aliyun.com Delete WaitForFirstConsumer false 11m open-local-device-ssd local.csi.aliyun.com Delete WaitForFirstConsumer false 11m open-local-lvm local.csi.aliyun.com Delete WaitForFirstConsumer true 11m open-local-lvm-xfs local.csi.aliyun.com Delete WaitForFirstConsumer true 11m open-local-mountpoint-hdd local.csi.aliyun.com Delete WaitForFirstConsumer false 11m open-local-mountpoint-ssd local.csi.aliyun.com Delete WaitForFirstConsumer false 11m |
Before trying with my own PostgreSQL container I have tried the provided Nginx example, more particularly the block one available in example/device/sts-block.yaml of the GitHub project. But it didn’t work and the Persistent Volume has not been created:
[root@server1 ~]# kubectl get sts NAME READY AGE nginx-device 0/1 2d19h [root@server1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-device-0 0/1 Pending 0 2d19h [root@server1 ~]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE html-nginx-device-0 Pending open-local-device-hdd 2d19h [root@server1 ~]# kubectl get pv No resources found [root@server1 ~]# kubectl describe pvc html-nginx-device-0 Name: html-nginx-device-0 Namespace: default StorageClass: open-local-device-hdd Status: Pending Volume: Labels: app=nginx-device Annotations: volume.beta.kubernetes.io/storage-provisioner: local.csi.aliyun.com volume.kubernetes.io/selected-node: server2.domain.com Finalizers: [kubernetes.io/pvc-protection] Capacity: Access Modes: VolumeMode: Block Used By: nginx-device-0 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Provisioning 8m51s (x268 over 169m) local.csi.aliyun.com_server2.domain.com_aa0fd726-4fe8-46b0-9ab6-2e669a1b052f External provisioner is provisioning volume for claim "default/html-nginx-device-0" Normal ExternalProvisioning 4m26s (x636 over 169m) persistentvolume-controller waiting for a volume to be created, either by external provisioner "local.csi.aliyun.com" or manually created by system administrator Warning ProvisioningFailed 4m16s (x271 over 168m) local.csi.aliyun.com_server2.domain.com_aa0fd726-4fe8-46b0-9ab6-2e669a1b052f failed to provision volume with StorageClass "open-local-device-hdd": rpc error: code = DeadlineExceeded desc = context deadline exceeded |
References
- Storing data into Persistent Volumes on Kubernetes
- Beginners guide on Kubernetes volumes with examples





