Table of contents
Preamble
After cardinality feedback testing in 11gR2 I wanted to test the re-branded version in 12cR1 called Statistics Feedback and see, as well, SQL Plan directives (SPD). My simple example has also allowed me to see Dynamic Statistics and Adaptive Plans in action.
Those three new 12cR1 features are part of a more wider feature called Adaptive Query optimization, this Oracle corporation figure is well summarizing these features:
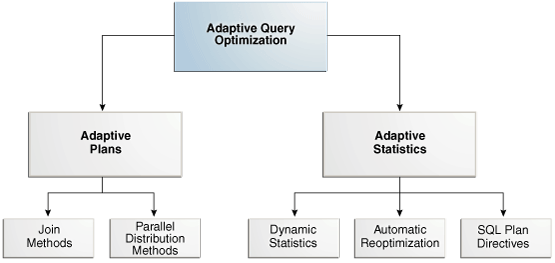
Adaptive Plans:
An adaptive plan enables the optimizer to defer the final plan decision for a statement until execution time. The ability of the optimizer to adapt a plan, based on information learned during execution, can greatly improve query performance.
Dynamic Statistics:
By default, when optimizer statistics are missing, stale, or insufficient, the database automatically gathers dynamic statistics during a parse. The database uses recursive SQL to scan a small random sample of table blocks.
Dynamic statistics can supplement statistics such as table and index block counts, table and join cardinalities (estimated number of rows), join column statistics, and GROUP BY statistics. This information helps the optimizer improve plans by making better estimates for predicate selectivity.
SQL Plan Directives:
A SQL plan directive is additional information and instructions that the optimizer can use to generate a more optimal plan. For example, a SQL plan directive can instruct the optimizer to record a missing extension.
Adaptive Plans can online change a bad plan while it is executing (!!). So Cost Based Optimizer (CBO) is not only learning from its mistakes for second run but can change currently running first execution. Dynamic Statistics is an extension of dynamic sampling and is an improvement to also gather statistics on more complex operations. SQL Plan Directives is stored information for further SQL statements like wrongly estimated cardinality or extended statistics, so for example if a cursor obtained with statistics feedback aged out from shared pool then next parsing will benefit from SQL Plan Directives.
Testing has been done on Oracle Enterprise Edition 12cR1 (12.1.0.2) running on Red Hat Enterprise Linux Server release 6.3 (Santiago).
Adaptive Query Optimization configuration
I have been struggling using only the test table I used when testing cardinality feedback but failed to produce an explain plan that was using statistics feedback so decided to duplicate my test table and added an auto-increment column to join it:
DROP TABLE test1; CREATE TABLE test1(id NUMBER, id1 NUMBER, id2 NUMBER,descr VARCHAR2(100)) NOLOGGING TABLESPACE move_data; DECLARE i NUMBER; nbrows NUMBER; BEGIN i:=1; nbrows:=100000; LOOP EXIT WHEN i>nbrows; IF (MOD(i,20000) = 0) THEN INSERT INTO test1 VALUES(i,4,ROUND(dbms_random.VALUE(1,nbrows)),RPAD('A',100,'A')); ELSE INSERT INTO test1 VALUES(i,MOD(i,4),ROUND(dbms_random.VALUE(1,nbrows)),RPAD('A',100,'A')); END IF; i:=i+1; END LOOP; COMMIT; END; / |
Then I add a primary key (index) and gather statistics with no histograms:
ALTER TABLE test1 ADD CONSTRAINT test1_pk PRIMARY KEY(id) TABLESPACE move_data; EXEC dbms_stats.gather_table_stats('yjaquier', 'test1'); |
Then I just copy this test1 table and create a test2 table (again with a primary key and no histogram):
CREATE TABLE test2 AS SELECT * FROM test1 nologging TABLESPACE move_data; ALTER TABLE test2 ADD CONSTRAINT test2_pk PRIMARY KEY(id) TABLESPACE move_data; EXEC dbms_stats.gather_table_stats('yjaquier', 'test2'); |
Adaptive Query Optimization testing
The query I use is a join between my two equivalent tables using the same trick I have used for Cardinality Feedback (statement in lowercase). This more complex statement has also allows me to see new other features (the /* Yannick */ comment is here to help me to find cursor in library cache):
select /* Yannick */ sum(test1.id2), sum(test2.id2) from test1, test2 where test1.id1 = 4 and test1.id2 >= 5000 and test2.id = test1.id and test2.id1 = 4 and test2.id2 > 5000;
As stated in Database SQL Tuning guide to see Adaptive Query Optimization features in action you need to have:
OPTIMIZER_FEATURES_ENABLE >= 12.1.0.1 OPTIMIZER_ADAPTIVE_REPORTING_ONLY = false (default).
To prepare my environment I use:
sql> ALTER SYSTEM flush shared_pool; SYSTEM altered. sql> ALTER SYSTEM flush shared_pool; SYSTEM altered. sql> SET lines 200 pages 200 TIMING ON sql> col sql_text FOR a90 sql> col plan_table_output FOR a180 sql> ALTER SESSION SET statistics_level=ALL; SESSION altered. |
After first execution we can see that parsed cursor is candidate for reoptimization:
SQL> SELECT sql_id,child_number,sql_text,is_reoptimizable,is_resolved_adaptive_plan FROM v$sql WHERE sql_text LIKE 'select /* Yannick */%'; SQL_ID CHILD_NUMBER SQL_TEXT I I ------------- ------------ ------------------------------------------------------------------------------------------ - - dmqvqjznn256h 0 SELECT /* Yannick */ SUM(test1.id2), SUM(test2.id2) FROM test1, test2 WHERE test1.id1 = 4 Y Y AND test1.id2 >= 5000 AND test2.id = test1.id AND test2.id1 = 4 AND test2.id2 > 5000 SQL> SELECT sql_id,child_number,use_feedback_stats,reason FROM V$SQL_SHARED_CURSOR WHERE sql_id IN (SELECT sql_id FROM v$sql WHERE sql_text LIKE 'select /* Yannick */%'); SQL_ID CHILD_NUMBER U REASON ------------- ------------ - -------------------------------------------------------------------------------- 14awfgwjyar63 0 Y |
The package to manage SQL Plan Directives (SPD) is DBMS_SPD and to be able to see them in dictionary table you may need to flush them from SGA memory to disk with (DBMS_SPD can also drop existing directives with DROP_SQL_PLAN_DIRECTIVE):
SQL> EXEC dbms_spd.FLUSH_SQL_PLAN_DIRECTIVE; PL/SQL PROCEDURE successfully completed. |
You can see them with:
SQL> col directive_id FOR 99999999999999999999 SQL> col OBJECT_NAME FOR a10 SQL> col SUBOBJECT_NAME FOR a10 SQL> SELECT directive_id,object_name,subobject_name,object_type FROM DBA_SQL_PLAN_DIR_OBJECTS WHERE owner='YJAQUIER' ORDER BY directive_id,object_name,subobject_name; DIRECTIVE_ID OBJECT_NAM SUBOBJECT_ OBJECT --------------------- ---------- ---------- ------ 6178000259363216461 TEST2 ID1 COLUMN 6178000259363216461 TEST2 ID2 COLUMN 6178000259363216461 TEST2 TABLE 6377965752638656671 TEST1 ID COLUMN 6377965752638656671 TEST1 TABLE SQL> SELECT directive_id,TYPE,enabled,state,reason FROM dba_sql_plan_directives WHERE directive_id IN (SELECT directive_id FROM DBA_SQL_PLAN_DIR_OBJECTS WHERE owner='YJAQUIER') ORDER BY directive_id; DIRECTIVE_ID TYPE ENA STATE REASON --------------------- ---------------- --- ---------- ------------------------------------ 6178000259363216461 DYNAMIC_SAMPLING YES USABLE SINGLE TABLE CARDINALITY MISESTIMATE 6377965752638656671 DYNAMIC_SAMPLING YES USABLE SINGLE TABLE CARDINALITY MISESTIMATE |
It gives below explain plan:
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id=>'14awfgwjyar63', cursor_child_no=>'0', format=> 'all adaptive allstats')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 14awfgwjyar63, child NUMBER 0 ------------------------------------- SELECT /* Yannick */ SUM(test1.id2), SUM(test2.id2) FROM test1, test2 WHERE test1.id1 = 4 AND test1.id2 >= 5000 AND test2.id = test1.id AND test2.id1 = 4 AND test2.id2 > 5000 PLAN hash VALUE: 620841792 --------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-ROWS |E-Bytes| COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | --------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 940 (100)| | 1 |00:00:00.01 | 1672 | | 1 | SORT AGGREGATE | | 1 | 1 | 26 | | | 1 |00:00:00.01 | 1672 | |- * 2 | HASH JOIN | | 1 | 19000 | 482K| 940 (1)| 00:00:01 | 5 |00:00:00.01 | 1672 | | 3 | NESTED LOOPS | | 1 | 19000 | 482K| 940 (1)| 00:00:01 | 5 |00:00:00.01 | 1672 | | 4 | NESTED LOOPS | | 1 | | | | | 5 |00:00:00.01 | 1667 | |- 5 | STATISTICS COLLECTOR | | 1 | | | | | 5 |00:00:00.01 | 1660 | | * 6 | TABLE ACCESS FULL | TEST2 | 1 | 19001 | 241K| 461 (1)| 00:00:01 | 5 |00:00:00.01 | 1660 | | * 7 | INDEX UNIQUE SCAN | TEST1_PK | 5 | | | | | 5 |00:00:00.01 | 7 | | * 8 | TABLE ACCESS BY INDEX ROWID| TEST1 | 5 | 1 | 13 | 478 (1)| 00:00:01 | 5 |00:00:00.01 | 5 | |- * 9 | TABLE ACCESS FULL | TEST1 | 0 | 19001 | 241K| 478 (1)| 00:00:01 | 0 |00:00:00.01 | 0 | --------------------------------------------------------------------------------------------------------------------------------------- . . . Note ----- - this IS an adaptive PLAN (ROWS marked '-' are inactive) |
So here we see that CBO started with a Hash Join of a Full Table Scan (FTS) of my two tables and then switch to a Nested Loop on a FTS on test2 and a Primary Key access on test1. We can also notice the STATISTICS COLLECTOR step that is gathering additional statistics to help COB chose a better plan.
If I execute a second time the query:
SQL> SELECT sql_id,child_number,use_feedback_stats,reason FROM V$SQL_SHARED_CURSOR WHERE sql_id IN (SELECT sql_id FROM v$sql WHERE sql_text LIKE 'select /* Yannick */%'); SQL_ID CHILD_NUMBER U REASON ------------- ------------ - -------------------------------------------------------------------------------- 14awfgwjyar63 0 Y <ChildNode><ChildNumber>0</ChildNumber><ID>49</ID><reason>Auto Reoptimization Mi 14awfgwjyar63 1 N |
With below explain plan:
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id=>'14awfgwjyar63', cursor_child_no=>'1', format=> 'all adaptive allstats')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 14awfgwjyar63, child NUMBER 1 ------------------------------------- SELECT /* Yannick */ SUM(test1.id2), SUM(test2.id2) FROM test1, test2 WHERE test1.id1 = 4 AND test1.id2 >= 5000 AND test2.id = test1.id AND test2.id1 = 4 AND test2.id2 > 5000 PLAN hash VALUE: 620841792 ------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-ROWS |E-Bytes| COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | ------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 466 (100)| | 1 |00:00:00.01 | 1672 | | 1 | SORT AGGREGATE | | 1 | 1 | 26 | | | 1 |00:00:00.01 | 1672 | | 2 | NESTED LOOPS | | 1 | 1 | 26 | 466 (1)| 00:00:01 | 5 |00:00:00.01 | 1672 | | 3 | NESTED LOOPS | | 1 | 5 | 26 | 466 (1)| 00:00:01 | 5 |00:00:00.01 | 1667 | |* 4 | TABLE ACCESS FULL | TEST2 | 1 | 5 | 65 | 461 (1)| 00:00:01 | 5 |00:00:00.01 | 1660 | |* 5 | INDEX UNIQUE SCAN | TEST1_PK | 5 | 1 | | 0 (0)| | 5 |00:00:00.01 | 7 | |* 6 | TABLE ACCESS BY INDEX ROWID| TEST1 | 5 | 1 | 13 | 1 (0)| 00:00:01 | 5 |00:00:00.01 | 5 | ------------------------------------------------------------------------------------------------------------------------------------ . . . Note ----- - STATISTICS feedback used FOR this statement |
If for any reason cursor is aged out (which you can simulate by flushing the shared pool), then cursor after first execution is no more candidate for reoptimization, thanks to SQL Plan Directives (adaptive plan is still used):
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id=>'14awfgwjyar63', cursor_child_no=>'0', format=> 'all adaptive allstats')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ SQL_ID 14awfgwjyar63, child NUMBER 0 ------------------------------------- SELECT /* Yannick */ SUM(test1.id2), SUM(test2.id2) FROM test1, test2 WHERE test1.id1 = 4 AND test1.id2 >= 5000 AND test2.id = test1.id AND test2.id1 = 4 AND test2.id2 > 5000 PLAN hash VALUE: 620841792 --------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-ROWS |E-Bytes| COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | --------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 465 (100)| | 1 |00:00:00.01 | 1672 | | 1 | SORT AGGREGATE | | 1 | 1 | 26 | | | 1 |00:00:00.01 | 1672 | |- * 2 | HASH JOIN | | 1 | 2 | 52 | 465 (1)| 00:00:01 | 5 |00:00:00.01 | 1672 | | 3 | NESTED LOOPS | | 1 | 2 | 52 | 465 (1)| 00:00:01 | 5 |00:00:00.01 | 1672 | | 4 | NESTED LOOPS | | 1 | 4 | 52 | 465 (1)| 00:00:01 | 5 |00:00:00.01 | 1667 | |- 5 | STATISTICS COLLECTOR | | 1 | | | | | 5 |00:00:00.01 | 1660 | | * 6 | TABLE ACCESS FULL | TEST2 | 1 | 4 | 52 | 461 (1)| 00:00:01 | 5 |00:00:00.01 | 1660 | | * 7 | INDEX UNIQUE SCAN | TEST1_PK | 5 | 1 | | 0 (0)| | 5 |00:00:00.01 | 7 | | * 8 | TABLE ACCESS BY INDEX ROWID| TEST1 | 5 | 1 | 13 | 1 (0)| 00:00:01 | 5 |00:00:00.01 | 5 | |- * 9 | TABLE ACCESS FULL | TEST1 | 0 | 1 | 13 | 1 (0)| 00:00:01 | 0 |00:00:00.01 | 0 | --------------------------------------------------------------------------------------------------------------------------------------- . . . Note ----- - dynamic STATISTICS used: dynamic sampling (LEVEL=2) - this IS an adaptive PLAN (ROWS marked '-' are inactive) - 2 SQL PLAN Directives used FOR this statement |



 hidden feature hands-on")
")