In order to test a real life high availability scenario you might want to create an operating system cluster to simulate what you could have in production. Where I work the standard tool to manage OS cluster is Veritas Cluster Server (VCS). It’s a nice tool but its installation require a license key that is not easy to get to test the product.
A free alternative is anyway available and is called Pacemaker. In this blog post I will setup a completer cluster with a virtual IP address (192.168.56.99), a LVM volume group (vg01), a file system (/u01) and finally an Oracle database and its associated listener. The listener will obviously listen on the virtual IP address of the cluster.
For testing I have used two virtual machines running Oracle Linux Server release 7.2 64 bits and Oracle Enterprise edition 12cR2 (12.2.0.1.0) but any Oracle release can be used. The virtual servers are:
server2.domain.com using non routable IP address 192.168.56.102
server3.domain.com using non routable IP address 192.168.56.103
The command to control and manage Pacemaker is pcs.
Pacemaker installation
Install PCS that control and configure pacemaker and corosync with:
[root@server2 ~]# yum -y install pcs
[root@server2 ~]# yum -y install pcs
Pacemaker and corosync will be installed as well:
Dependencies Resolved
===========================================================================================================================================================================================================
Package Arch Version Repository Size
===========================================================================================================================================================================================================
Installing:
pcs x86_64 0.9.152-10.0.1.el7 ol7_latest 5.0 M
Installing for dependencies:
corosync x86_64 2.4.0-4.el7 ol7_latest 212 k
corosynclib x86_64 2.4.0-4.el7 ol7_latest 125 k
libqb x86_64 1.0-1.el7 ol7_latest 91 k
libtool-ltdl x86_64 2.4.2-22.el7_3 ol7_latest 48 k
libxslt x86_64 1.1.28-5.0.1.el7 ol7_latest 241 k
libyaml x86_64 0.1.4-11.el7_0 ol7_latest 54 k
nano x86_64 2.3.1-10.el7 ol7_latest 438 k
net-snmp-libs x86_64 1:5.7.2-24.el7_3.2 ol7_latest 747 k
pacemaker x86_64 1.1.15-11.el7 ol7_latest 441 k
pacemaker-cli x86_64 1.1.15-11.el7 ol7_latest 319 k
pacemaker-cluster-libs x86_64 1.1.15-11.el7 ol7_latest 95 k
pacemaker-libs x86_64 1.1.15-11.el7 ol7_latest 521 k
perl-TimeDate noarch 1:2.30-2.el7 ol7_latest 51 k
psmisc x86_64 22.20-11.el7 ol7_latest 140 k
python-backports x86_64 1.0-8.el7 ol7_latest 5.2 k
python-backports-ssl_match_hostname noarch 3.4.0.2-4.el7 ol7_latest 11 k
python-clufter x86_64 0.59.5-2.0.1.el7 ol7_latest 349 k
python-lxml x86_64 3.2.1-4.el7 ol7_latest 758 k
python-setuptools noarch 0.9.8-4.el7 ol7_latest 396 k
resource-agents x86_64 3.9.5-82.el7 ol7_latest 359 k
ruby x86_64 2.0.0.648-29.el7 ol7_latest 68 k
ruby-irb noarch 2.0.0.648-29.el7 ol7_latest 89 k
ruby-libs x86_64 2.0.0.648-29.el7 ol7_latest 2.8 M
rubygem-bigdecimal x86_64 1.2.0-29.el7 ol7_latest 80 k
rubygem-io-console x86_64 0.4.2-29.el7 ol7_latest 51 k
rubygem-json x86_64 1.7.7-29.el7 ol7_latest 76 k
rubygem-psych x86_64 2.0.0-29.el7 ol7_latest 78 k
rubygem-rdoc noarch 4.0.0-29.el7 ol7_latest 319 k
rubygems noarch 2.0.14.1-29.el7 ol7_latest 215 k
Transaction Summary
===========================================================================================================================================================================================================
Dependencies Resolved===========================================================================================================================================================================================================
Package Arch Version Repository Size
===========================================================================================================================================================================================================
Installing:
pcs x86_64 0.9.152-10.0.1.el7 ol7_latest 5.0 M
Installing for dependencies:
corosync x86_64 2.4.0-4.el7 ol7_latest 212 k
corosynclib x86_64 2.4.0-4.el7 ol7_latest 125 k
libqb x86_64 1.0-1.el7 ol7_latest 91 k
libtool-ltdl x86_64 2.4.2-22.el7_3 ol7_latest 48 k
libxslt x86_64 1.1.28-5.0.1.el7 ol7_latest 241 k
libyaml x86_64 0.1.4-11.el7_0 ol7_latest 54 k
nano x86_64 2.3.1-10.el7 ol7_latest 438 k
net-snmp-libs x86_64 1:5.7.2-24.el7_3.2 ol7_latest 747 k
pacemaker x86_64 1.1.15-11.el7 ol7_latest 441 k
pacemaker-cli x86_64 1.1.15-11.el7 ol7_latest 319 k
pacemaker-cluster-libs x86_64 1.1.15-11.el7 ol7_latest 95 k
pacemaker-libs x86_64 1.1.15-11.el7 ol7_latest 521 k
perl-TimeDate noarch 1:2.30-2.el7 ol7_latest 51 k
psmisc x86_64 22.20-11.el7 ol7_latest 140 k
python-backports x86_64 1.0-8.el7 ol7_latest 5.2 k
python-backports-ssl_match_hostname noarch 3.4.0.2-4.el7 ol7_latest 11 k
python-clufter x86_64 0.59.5-2.0.1.el7 ol7_latest 349 k
python-lxml x86_64 3.2.1-4.el7 ol7_latest 758 k
python-setuptools noarch 0.9.8-4.el7 ol7_latest 396 k
resource-agents x86_64 3.9.5-82.el7 ol7_latest 359 k
ruby x86_64 2.0.0.648-29.el7 ol7_latest 68 k
ruby-irb noarch 2.0.0.648-29.el7 ol7_latest 89 k
ruby-libs x86_64 2.0.0.648-29.el7 ol7_latest 2.8 M
rubygem-bigdecimal x86_64 1.2.0-29.el7 ol7_latest 80 k
rubygem-io-console x86_64 0.4.2-29.el7 ol7_latest 51 k
rubygem-json x86_64 1.7.7-29.el7 ol7_latest 76 k
rubygem-psych x86_64 2.0.0-29.el7 ol7_latest 78 k
rubygem-rdoc noarch 4.0.0-29.el7 ol7_latest 319 k
rubygems noarch 2.0.14.1-29.el7 ol7_latest 215 kTransaction Summary
===========================================================================================================================================================================================================
On all nodes:
[root@server2 ~]# systemctl start pcsd.service[root@server2 ~]# systemctl enable pcsd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
[root@server2 ~]# systemctl start pcsd.service
[root@server2 ~]# systemctl enable pcsd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/pcsd.service to /usr/lib/systemd/system/pcsd.service.
Change hacluster password on all nodes:
[root@server3 ~]# echo secure_password | passwd --stdin hacluster
Changing password for user hacluster.
passwd: all authentication tokens updated successfully.
[root@server3 ~]# echo secure_password | passwd --stdin hacluster
Changing password for user hacluster.
passwd: all authentication tokens updated successfully.
Create your cluster (cluster01) on your two nodes with:
[root@server2 ~]# pcs cluster setup --start --name cluster01 server2.domain.com server3.domain.com
Destroying cluster on nodes: server2.domain.com, server3.domain.com...
server2.domain.com: Stopping Cluster (pacemaker)...
server3.domain.com: Stopping Cluster (pacemaker)...
server2.domain.com: Successfully destroyed cluster
server3.domain.com: Successfully destroyed cluster
Sending cluster config files to the nodes...
server2.domain.com: Succeeded
server3.domain.com: Succeeded
Starting cluster on nodes: server2.domain.com, server3.domain.com...
server2.domain.com: Starting Cluster...
server3.domain.com: Starting Cluster...
Synchronizing pcsd certificates on nodes server2.domain.com, server3.domain.com...
server3.domain.com: Success
server2.domain.com: Success
Restarting pcsd on the nodes in order to reload the certificates...
server3.domain.com: Success
server2.domain.com: Success
[root@server2 ~]# pcs cluster setup --start --name cluster01 server2.domain.com server3.domain.com
Destroying cluster on nodes: server2.domain.com, server3.domain.com...
server2.domain.com: Stopping Cluster (pacemaker)...
server3.domain.com: Stopping Cluster (pacemaker)...
server2.domain.com: Successfully destroyed cluster
server3.domain.com: Successfully destroyed clusterSending cluster config files to the nodes...
server2.domain.com: Succeeded
server3.domain.com: SucceededStarting cluster on nodes: server2.domain.com, server3.domain.com...
server2.domain.com: Starting Cluster...
server3.domain.com: Starting Cluster...Synchronizing pcsd certificates on nodes server2.domain.com, server3.domain.com...
server3.domain.com: Success
server2.domain.com: SuccessRestarting pcsd on the nodes in order to reload the certificates...
server3.domain.com: Success
server2.domain.com: Success
Check it with:
[root@server2 ~]# pcs status
Cluster name: cluster01
WARNING: no stonith devices and stonith-enabled is not false
Stack: unknown
Current DC: NONE
Last updated: Wed Apr 1910:01:02 2017 Last change: Wed Apr 1910:00:472017 by hacluster via crmd on server2.domain.com
2 nodes and 0 resources configured
Node server2.domain.com: UNCLEAN (offline)
Node server3.domain.com: UNCLEAN (offline)
No resources
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
[root@server2 ~]# pcs status
Cluster name: cluster01
WARNING: no stonith devices and stonith-enabled is not false
Stack: unknown
Current DC: NONE
Last updated: Wed Apr 19 10:01:02 2017 Last change: Wed Apr 19 10:00:47 2017 by hacluster via crmd on server2.domain.com2 nodes and 0 resources configuredNode server2.domain.com: UNCLEAN (offline)
Node server3.domain.com: UNCLEAN (offline)No resourcesDaemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Notice the WARNING above about missing stonish device…
Enable cluster with:
[root@server2 ~]# pcs cluster enable --all
server2.domain.com: Cluster Enabled
server3.domain.com: Cluster Enabled
[root@server2 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1910:02:02 2017 Last change: Wed Apr 1910:01:08 2017 by hacluster via crmd on server2.domain.com
2 nodes and 0 resources configured
PCSD Status:
server2.domain.com: Online
server3.domain.com: Online
[root@server2 ~]# pcs cluster enable --all
server2.domain.com: Cluster Enabled
server3.domain.com: Cluster Enabled
[root@server2 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 10:02:02 2017 Last change: Wed Apr 19 10:01:08 2017 by hacluster via crmd on server2.domain.com
2 nodes and 0 resources configuredPCSD Status:
server2.domain.com: Online
server3.domain.com: Online
As documentation says:
STONITH is an acronym for “Shoot The Other Node In The Head” and it protects your data from being corrupted by rogue nodes or concurrent access.
This is also known as split brain, this simply allow multiple nodes to access same resource (like writing to a filesystem) at same time and simple goal is to avoid corruption… As the aim is to build something simple I will disable fencing with:
[root@server2 ~]# pcs property set stonith-enabled=false[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1910:02:532017 Last change: Wed Apr 1910:02:492017 by root via cibadmin on server2.domain.com
2 nodes and 0 resources configured
Online: [ server2.domain.com server3.domain.com ]
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs property set stonith-enabled=false
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 10:02:53 2017 Last change: Wed Apr 19 10:02:49 2017 by root via cibadmin on server2.domain.com2 nodes and 0 resources configuredOnline: [ server2.domain.com server3.domain.com ]No resourcesDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Pacemaker resources creation
To create a new resource you might want to know what are available ones in Pacemaker:
[root@server2 ~]# pcs resource list ocf:heartbeat
ocf:heartbeat:CTDB - CTDB Resource Agent
ocf:heartbeat:Delay - Waits for a defined timespan
ocf:heartbeat:Dummy - Example stateless resource agent
ocf:heartbeat:Filesystem - Manages filesystem mounts
ocf:heartbeat:IPaddr - Manages virtual IPv4 and IPv6 addresses (Linux specific version)
ocf:heartbeat:IPaddr2 - Manages virtual IPv4 and IPv6 addresses (Linux specific version)
ocf:heartbeat:IPsrcaddr - Manages the preferred source address for outgoing IP packets
ocf:heartbeat:LVM - Controls the availability of an LVM Volume Group
ocf:heartbeat:MailTo - Notifies recipients by email in the event of resource takeover
ocf:heartbeat:Route - Manages network routes
ocf:heartbeat:SendArp - Broadcasts unsolicited ARP announcements
ocf:heartbeat:Squid - Manages a Squid proxy server instance
ocf:heartbeat:VirtualDomain - Manages virtual domains through the libvirt virtualization framework
ocf:heartbeat:Xinetd - Manages a service of Xinetd
ocf:heartbeat:apache - Manages an Apache Web server instance
ocf:heartbeat:clvm - clvmd
ocf:heartbeat:conntrackd - This resource agent manages conntrackd
ocf:heartbeat:db2 - Resource Agent that manages an IBM DB2 LUW databases in Standard role as primitive or in HADR roles as master/slave configuration. Multiple partitions are supported.
ocf:heartbeat:dhcpd - Chrooted ISC DHCP server resource agent.
ocf:heartbeat:docker - Docker container resource agent.
ocf:heartbeat:ethmonitor - Monitors network interfaces
ocf:heartbeat:exportfs - Manages NFS exports
ocf:heartbeat:galera - Manages a galara instance
ocf:heartbeat:garbd - Manages a galera arbitrator instance
ocf:heartbeat:iSCSILogicalUnit - Manages iSCSI Logical Units (LUs)
ocf:heartbeat:iSCSITarget - iSCSI target export agent
ocf:heartbeat:iface-vlan - Manages VLAN network interfaces.
ocf:heartbeat:mysql - Manages a MySQL database instance
ocf:heartbeat:nagios - Nagios resource agent
ocf:heartbeat:named - Manages a named server
ocf:heartbeat:nfsnotify - sm-notify reboot notifications
ocf:heartbeat:nfsserver - Manages an NFS server
ocf:heartbeat:nginx - Manages an Nginx web/proxy server instance
ocf:heartbeat:oracle - Manages an Oracle Database instance
ocf:heartbeat:oralsnr - Manages an Oracle TNS listener
ocf:heartbeat:pgsql - Manages a PostgreSQL database instance
ocf:heartbeat:portblock - Block and unblocks access to TCP and UDP ports
ocf:heartbeat:postfix - Manages a highly available Postfix mail server instance
ocf:heartbeat:rabbitmq-cluster - rabbitmq clustered
ocf:heartbeat:redis - Redis server
ocf:heartbeat:rsyncd - Manages an rsync daemon
ocf:heartbeat:slapd - Manages a Stand-alone LDAP Daemon (slapd) instance
ocf:heartbeat:symlink - Manages a symbolic link
ocf:heartbeat:tomcat - Manages a Tomcat servlet environment instance
[root@server2 ~]# pcs resource list ocf:heartbeat
ocf:heartbeat:CTDB - CTDB Resource Agent
ocf:heartbeat:Delay - Waits for a defined timespan
ocf:heartbeat:Dummy - Example stateless resource agent
ocf:heartbeat:Filesystem - Manages filesystem mounts
ocf:heartbeat:IPaddr - Manages virtual IPv4 and IPv6 addresses (Linux specific version)
ocf:heartbeat:IPaddr2 - Manages virtual IPv4 and IPv6 addresses (Linux specific version)
ocf:heartbeat:IPsrcaddr - Manages the preferred source address for outgoing IP packets
ocf:heartbeat:LVM - Controls the availability of an LVM Volume Group
ocf:heartbeat:MailTo - Notifies recipients by email in the event of resource takeover
ocf:heartbeat:Route - Manages network routes
ocf:heartbeat:SendArp - Broadcasts unsolicited ARP announcements
ocf:heartbeat:Squid - Manages a Squid proxy server instance
ocf:heartbeat:VirtualDomain - Manages virtual domains through the libvirt virtualization framework
ocf:heartbeat:Xinetd - Manages a service of Xinetd
ocf:heartbeat:apache - Manages an Apache Web server instance
ocf:heartbeat:clvm - clvmd
ocf:heartbeat:conntrackd - This resource agent manages conntrackd
ocf:heartbeat:db2 - Resource Agent that manages an IBM DB2 LUW databases in Standard role as primitive or in HADR roles as master/slave configuration. Multiple partitions are supported.
ocf:heartbeat:dhcpd - Chrooted ISC DHCP server resource agent.
ocf:heartbeat:docker - Docker container resource agent.
ocf:heartbeat:ethmonitor - Monitors network interfaces
ocf:heartbeat:exportfs - Manages NFS exports
ocf:heartbeat:galera - Manages a galara instance
ocf:heartbeat:garbd - Manages a galera arbitrator instance
ocf:heartbeat:iSCSILogicalUnit - Manages iSCSI Logical Units (LUs)
ocf:heartbeat:iSCSITarget - iSCSI target export agent
ocf:heartbeat:iface-vlan - Manages VLAN network interfaces.
ocf:heartbeat:mysql - Manages a MySQL database instance
ocf:heartbeat:nagios - Nagios resource agent
ocf:heartbeat:named - Manages a named server
ocf:heartbeat:nfsnotify - sm-notify reboot notifications
ocf:heartbeat:nfsserver - Manages an NFS server
ocf:heartbeat:nginx - Manages an Nginx web/proxy server instance
ocf:heartbeat:oracle - Manages an Oracle Database instance
ocf:heartbeat:oralsnr - Manages an Oracle TNS listener
ocf:heartbeat:pgsql - Manages a PostgreSQL database instance
ocf:heartbeat:portblock - Block and unblocks access to TCP and UDP ports
ocf:heartbeat:postfix - Manages a highly available Postfix mail server instance
ocf:heartbeat:rabbitmq-cluster - rabbitmq clustered
ocf:heartbeat:redis - Redis server
ocf:heartbeat:rsyncd - Manages an rsync daemon
ocf:heartbeat:slapd - Manages a Stand-alone LDAP Daemon (slapd) instance
ocf:heartbeat:symlink - Manages a symbolic link
ocf:heartbeat:tomcat - Manages a Tomcat servlet environment instance
Virtual Ip address
Add resource, a virtual IP, to test your cluster. I have chosen to use the Host-only Virtualbox adapter as it is cluster nodes communication so eth0 on all my nodes. We have seen how to configure this with Oracle Enterprise Linux or Redhat:
[root@server2 ~]# pcs resource create virtualip IPaddr2 ip=192.168.56.99 cidr_netmask=24 nic=eth0 op monitor interval=10s[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1910:03:502017 Last change: Wed Apr 1910:03:362017 by root via cibadmin on server2.domain.com
2 nodes and 1 resource configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource create virtualip IPaddr2 ip=192.168.56.99 cidr_netmask=24 nic=eth0 op monitor interval=10s
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 10:03:50 2017 Last change: Wed Apr 19 10:03:36 2017 by root via cibadmin on server2.domain.com2 nodes and 1 resource configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
You can check at OS level it has been done with:
[root@server2 ~]# ping -c 1 192.168.56.99
PING 192.168.56.99 (192.168.56.99)56(84) bytes of data.
64 bytes from 192.168.56.99: icmp_seq=1ttl=64time=0.025 ms
--- 192.168.56.99 ping statistics ---1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.025/0.025/0.025/0.000 ms
[root@server2 ~]# ip addr show dev eth02: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:47:54:07 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.102/24 brd 192.168.56.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.56.99/24 brd 192.168.56.255 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe47:5407/64 scope link
valid_lft forever preferred_lft forever
[root@server2 ~]# ping -c 1 192.168.56.99
PING 192.168.56.99 (192.168.56.99) 56(84) bytes of data.
64 bytes from 192.168.56.99: icmp_seq=1 ttl=64 time=0.025 ms--- 192.168.56.99 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.025/0.025/0.025/0.000 ms
[root@server2 ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:47:54:07 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.102/24 brd 192.168.56.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.56.99/24 brd 192.168.56.255 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe47:5407/64 scope link
valid_lft forever preferred_lft forever
Move virtual IP on server3.domain.com:
[root@server3 ~]# pcs resource move virtualip server3.domain.com[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1910:24:592017 Last change: Wed Apr 1910:06:212017 by root via crm_resource on server3.domain.com
2 nodes and 1 resource configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 ~]# pcs resource move virtualip server3.domain.com
[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server2.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 10:24:59 2017 Last change: Wed Apr 19 10:06:21 2017 by root via crm_resource on server3.domain.com2 nodes and 1 resource configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
We see the IP address has been transferred to server3.domain.com:
[root@server3 ~]# ip addr show dev eth02: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:b4:9d:bf brd ff:ff:ff:ff:ff:ff
inet 192.168.56.103/24 brd 192.168.56.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.56.99/24 brd 192.168.56.255 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feb4:9dbf/64 scope link
valid_lft forever preferred_lft forever
[root@server3 ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:b4:9d:bf brd ff:ff:ff:ff:ff:ff
inet 192.168.56.103/24 brd 192.168.56.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.56.99/24 brd 192.168.56.255 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feb4:9dbf/64 scope link
valid_lft forever preferred_lft forever
Volume group
I create a volume group (vg01) on a shared disk, I also mount the logical volume but this part is not yet required:
I add the LVM resource to Pacemaker, I deliberately create it on server2.domain.com:
[root@server2 /]# pcs resource create vg01 LVM volgrpname=vg01[root@server2 /]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1915:27:282017 Last change: Wed Apr 1915:27:242017 by root via cibadmin on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 /]# pcs resource create vg01 LVM volgrpname=vg01
[root@server2 /]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 15:27:28 2017 Last change: Wed Apr 19 15:27:24 2017 by root via cibadmin on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
I try to move vg01 volume group to server3.domain.com:
[root@server2 ~]# pcs resource move vg01 server3.domain.com[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1915:31:172017 Last change: Wed Apr 1915:31:04 2017 by root via crm_resource on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): FAILED server2.domain.com (blocked)
Failed Actions:
* vg01_stop_0 on server2.domain.com 'unknown error'(1): call=12, status=complete, exitreason='LVM: vg01 did not stop correctly',
last-rc-change='Wed Apr 19 15:31:04 2017', queued=1ms, exec=10526ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource move vg01 server3.domain.com
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 15:31:17 2017 Last change: Wed Apr 19 15:31:04 2017 by root via crm_resource on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): FAILED server2.domain.com (blocked)Failed Actions:
* vg01_stop_0 on server2.domain.com 'unknown error' (1): call=12, status=complete, exitreason='LVM: vg01 did not stop correctly',
last-rc-change='Wed Apr 19 15:31:04 2017', queued=1ms, exec=10526msDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
All this to show that it is not so easy and it requires a bit more of modification. I start by removing the volume group resource:
[root@server2 ~]# lvmconf --enable-halvm --services --startstopservices
Warning: Stopping lvm2-lvmetad.service, but it can still be activated by:
lvm2-lvmetad.socket
Removed symlink /etc/systemd/system/sysinit.target.wants/lvm2-lvmetad.socket.
[root@server2 ~]# ps -ef | grep lvm
root 319749198015:58 pts/1 00:00:00 grep--color=auto lvm
[root@server2 ~]# lvmconf --enable-halvm --services --startstopservices
Warning: Stopping lvm2-lvmetad.service, but it can still be activated by:
lvm2-lvmetad.socket
Removed symlink /etc/systemd/system/sysinit.target.wants/lvm2-lvmetad.socket.
[root@server2 ~]# ps -ef | grep lvm
root 31974 9198 0 15:58 pts/1 00:00:00 grep --color=auto lvm
In /etc/lvm/lvm.conf file of all nodes I add:
volume_list = ["vg00"]
volume_list = [ "vg00" ]
Execute below command on each node, this is not supporting kernel upgrade. The annoying thing is that each time you have a new kernel you have to issue the command on new kernel BEFORE rebooting or you need to reboot two times:
Recreate the volume group resource with exclusive option (parameter to ensure that only the cluster is capable of activating the LVM logical volume):
[root@server2 ~]# pcs resource create vg01 LVM volgrpname=vg01 exclusive=true[root@server2 ~]# pcs resource show
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:10:532017 Last change: Wed Apr 1917:10:432017 by root via cibadmin on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource create vg01 LVM volgrpname=vg01 exclusive=true
[root@server2 ~]# pcs resource show
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:10:53 2017 Last change: Wed Apr 19 17:10:43 2017 by root via cibadmin on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
The volume group move is now working fine:
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:10:532017 Last change: Wed Apr 1917:10:432017 by root via cibadmin on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource move vg01 server3.domain.com[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:12:202017 Last change: Wed Apr 1917:11:06 2017 by root via crm_resource on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:10:53 2017 Last change: Wed Apr 19 17:10:43 2017 by root via cibadmin on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource move vg01 server3.domain.com
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:12:20 2017 Last change: Wed Apr 19 17:11:06 2017 by root via crm_resource on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Filesystem
Create the file system based on a logical volume:
[root@server2 ~]# pcs resource create u01 Filesystem device="/dev/vg01/lvol01" directory="/u01" fstype="xfs"[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:13:512017 Last change: Wed Apr 1917:13:472017 by root via cibadmin on server2.domain.com
2 nodes and 3 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# pcs resource create u01 Filesystem device="/dev/vg01/lvol01" directory="/u01" fstype="xfs"
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:13:51 2017 Last change: Wed Apr 19 17:13:47 2017 by root via cibadmin on server2.domain.com2 nodes and 3 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
To collocate resources I create a group, this can also be done with constraints but a group is more logic in our case (the order you choose will be starting order):
[root@server3 u01]# pcs resource group add oracle virtualip vg01 u01[root@server3 u01]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:36:102017 Last change: Wed Apr 1917:36:07 2017 by root via cibadmin on server3.domain.com
2 nodes and 3 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 u01]# pcs resource group add oracle virtualip vg01 u01
[root@server3 u01]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:36:10 2017 Last change: Wed Apr 19 17:36:07 2017 by root via cibadmin on server3.domain.com2 nodes and 3 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
At that stage you can test already created resources are moving from one cluster node to the other with something like:
[root@server3 u01]# pcs cluster standby server3.domain.com[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:45:452017 Last change: Wed Apr 1917:45:372017 by root via crm_resource on server2.domain.com
2 nodes and 3 resources configured
Node server3.domain.com: standby
Online: [ server2.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
u01 (ocf::heartbeat:Filesystem): Started server2.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 u01]# pcs cluster standby server3.domain.com
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:45:45 2017 Last change: Wed Apr 19 17:45:37 2017 by root via crm_resource on server2.domain.com2 nodes and 3 resources configuredNode server3.domain.com: standby
Online: [ server2.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.com
vg01 (ocf::heartbeat:LVM): Started server2.domain.com
u01 (ocf::heartbeat:Filesystem): Started server2.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
And be back in initial situation with (they are back on server3.domain.com because I have also played with preferred node but this is not mandatory):
[root@server3 ~]# pcs node unstandby server3.domain.com[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 1917:48:05 2017 Last change: Wed Apr 1917:48:03 2017 by root via crm_attribute on server3.domain.com
2 nodes and 3 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 ~]# pcs node unstandby server3.domain.com
[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Wed Apr 19 17:48:05 2017 Last change: Wed Apr 19 17:48:03 2017 by root via crm_attribute on server3.domain.com2 nodes and 3 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Oracle database
[root@server2 ~]# pcs resource describe oracle
ocf:heartbeat:oracle - Manages an Oracle Database instance
Resource script for oracle. Manages an Oracle Database instance
as an HA resource.
Resource options:
sid (required): The Oracle SID (aka ORACLE_SID).
home: The Oracle home directory (aka ORACLE_HOME). If not specified, then the SID along with its home should be listed in/etc/oratab.
user: The Oracle owner (aka ORACLE_OWNER). If not specified, then it is set to the owner of file$ORACLE_HOME/dbs/*${ORACLE_SID}.ora. If this does not work for you, just set it explicitely.
monuser: Monitoring user name. Every connection as sysdba is logged in an audit log. This can result in a large number of new files created. A new user is created (if it doesn't exist) in the start action and subsequently used in monitor. It should have very limited rights. Make sure that the password for this user does not expire.
monpassword: Password for the monitoring user. Make sure that the password for this user does not expire.
monprofile: Profile used by the monitoring user. If the profile does not exist, it will be created with a non-expiring password.
ipcrm: Sometimes IPC objects (shared memory segments and semaphores) belonging to an Oracle instance might be left behind which prevents the instance from starting. It is not easy to figure out which shared segments belong to which instance, in particular when more instances are running as same user. What we use here is the "oradebug" feature and its "ipc" trace utility. It is not optimal to parse the debugging information, but I am not aware of any other way to find out about the IPC information. In case the format or wording of the trace report changes, parsing might fail. There are some precautions, however, to prevent stepping on other peoples toes. There is also a dumpinstipc option which will make us print the IPC objects which belong to the instance. Use it to see if we parse the trace file correctly. Three settings are possible: - none: don't mess with IPC and hope for the best (beware: you'll probably be out of luck, sooner or later) - instance: try to figure out the IPC stuff which belongs to the instance and remove only those (default; should be safe) - orauser: remove all IPC belonging to the user which runs the instance (don't use this if you run more than one instance as same user or if other apps running as this user use IPC) The default setting "instance" should be safe to use, but in that case we cannot guarantee that the instance will start. In case IPC objects were already left around, because, for instance, someone mercilessly killing Oracle processes, there is no way any more to find out which IPC objects should be removed. In that case, human intervention is necessary, and probably _all_ instances running as same user will have to be stopped. The third setting, "orauser", guarantees IPC objects removal, but it does that based only on IPC objects ownership, so you should use that only if every instance runs as separate user. Please report any problems. Suggestions/fixes welcome.
clear_backupmode: The clear of the backup mode of ORACLE.
shutdown_method: How to stop Oracle is a matter of taste it seems. The default method ("checkpoint/abort") is: alter system checkpoint; shutdown abort; This should be the fastest safe way bring the instance down. If you find"shutdown abort" distasteful, set this attribute to "immediate"inwhichcase we will shutdown immediate; If you still think that there's even better way to shutdown an Oracle instance we are willing to listen.
[root@server2 ~]# pcs resource describe oracle
ocf:heartbeat:oracle - Manages an Oracle Database instanceResource script for oracle. Manages an Oracle Database instance
as an HA resource.Resource options:
sid (required): The Oracle SID (aka ORACLE_SID).
home: The Oracle home directory (aka ORACLE_HOME). If not specified, then the SID along with its home should be listed in /etc/oratab.
user: The Oracle owner (aka ORACLE_OWNER). If not specified, then it is set to the owner of file $ORACLE_HOME/dbs/*${ORACLE_SID}.ora. If this does not work for you, just set it explicitely.
monuser: Monitoring user name. Every connection as sysdba is logged in an audit log. This can result in a large number of new files created. A new user is created (if it doesn't exist) in the start action and subsequently used in monitor. It should have very limited rights. Make sure that the password for this user does not expire.
monpassword: Password for the monitoring user. Make sure that the password for this user does not expire.
monprofile: Profile used by the monitoring user. If the profile does not exist, it will be created with a non-expiring password.
ipcrm: Sometimes IPC objects (shared memory segments and semaphores) belonging to an Oracle instance might be left behind which prevents the instance from starting. It is not easy to figure out which shared segments belong to which instance, in particular when more instances are running as same user. What we use here is the "oradebug" feature and its "ipc" trace utility. It is not optimal to parse the debugging information, but I am not aware of any other way to find out about the IPC information. In case the format or wording of the trace report changes, parsing might fail. There are some precautions, however, to prevent stepping on other peoples toes. There is also a dumpinstipc option which will make us print the IPC objects which belong to the instance. Use it to see if we parse the trace file correctly. Three settings are possible: - none: don't mess with IPC and hope for the best (beware: you'll probably be out of luck, sooner or later) - instance: try to figure out the IPC stuff which belongs to the instance and remove only those (default; should be safe) - orauser: remove all IPC belonging to the user which runs the instance (don't use this if you run more than one instance as same user or if other apps running as this user use IPC) The default setting "instance" should be safe to use, but in that case we cannot guarantee that the instance will start. In case IPC objects were already left around, because, for instance, someone mercilessly killing Oracle processes, there is no way any more to find out which IPC objects should be removed. In that case, human intervention is necessary, and probably _all_ instances running as same user will have to be stopped. The third setting, "orauser", guarantees IPC objects removal, but it does that based only on IPC objects ownership, so you should use that only if every instance runs as separate user. Please report any problems. Suggestions/fixes welcome.
clear_backupmode: The clear of the backup mode of ORACLE.
shutdown_method: How to stop Oracle is a matter of taste it seems. The default method ("checkpoint/abort") is: alter system checkpoint; shutdown abort; This should be the fastest safe way bring the instance down. If you find "shutdown abort" distasteful, set this attribute to "immediate" in which case we will shutdown immediate; If you still think that there's even better way to shutdown an Oracle instance we are willing to listen.
I have then installed Oracle on server3.domain.com where is mounted /u01 filesystem. I have also copied /etc/oratab, /usr/local/bin/coraenv, /usr/local/bin/dbhome and /usr/local/bin/oraenv to server2.domain.com. This step is not mandatory but it will ease Oracle usage on both nodes.
I have also, obviously, changed the listener to make it listening on my virtual IP i.e. 192.168.56.99.
Create the oracle resource:
[root@server3 ~]# pcs resource create orcl oracle sid="orcl" --group=oracle[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 2018:18:412017 Last change: Thu Apr 2018:18:382017 by root via cibadmin on server3.domain.com
2 nodes and 4 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
orcl (ocf::heartbeat:oracle): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 ~]# pcs resource create orcl oracle sid="orcl" --group=oracle
[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 20 18:18:41 2017 Last change: Thu Apr 20 18:18:38 2017 by root via cibadmin on server3.domain.com2 nodes and 4 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
orcl (ocf::heartbeat:oracle): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
You must create monitoring user (default is OCFMON) and profile (default is OCFMONPROFILE) or you will get below error message:
* orcl_start_0 on server2.domain.com 'unknown error'(1): call=268, status=complete, exitreason='monprofile must start with C## for container databases',
last-rc-change='Fri Apr 21 15:17:06 2017', queued=0ms, exec=17138ms
* orcl_start_0 on server2.domain.com 'unknown error' (1): call=268, status=complete, exitreason='monprofile must start with C## for container databases',
last-rc-change='Fri Apr 21 15:17:06 2017', queued=0ms, exec=17138ms
Please note that container databases is also taken into account and the account must be created on container with C## option as a global account. I have chosen not to create the required profile but I must take it into account when creating the resource:
SQL>CREATEUSER c##ocfmon IDENTIFIEDBY"secure_password";
USER created.
SQL>GRANTCONNECTTO c##ocfmon;
GRANT succeeded.
SQL> create user c##ocfmon identified by "secure_password";User created.SQL> grant connect to c##ocfmon;Grant succeeded.
To have my pluggable database automatically opened as instance startup I have used a nice 12cR2 new feature called pluggable database default state:
SQL> SELECT * FROM dba_pdb_saved_states;
no rows selected
SQL> set lines 150
SQL> col name for a20
SQL> SELECT name, open_mode FROM v$pdbs;
NAME OPEN_MODE
-------------------- ----------
PDB$SEED READ ONLY
PDB1 MOUNTED
SQL> alter pluggable database pdb1 open;
Pluggable database altered.
SQL> alter pluggable database pdb1 save state;
Pluggable database altered.
SQL> col con_name for a20
SQL> SELECT con_name, state FROM dba_pdb_saved_states;
CON_NAME STATE
-------------------- --------------
PDB1 OPEN
SQL> SELECT * FROM dba_pdb_saved_states;no rows selectedSQL> set lines 150
SQL> col name for a20
SQL> SELECT name, open_mode FROM v$pdbs;NAME OPEN_MODE
-------------------- ----------
PDB$SEED READ ONLY
PDB1 MOUNTEDSQL> alter pluggable database pdb1 open;Pluggable database altered.SQL> alter pluggable database pdb1 save state;Pluggable database altered.SQL> col con_name for a20
SQL> SELECT con_name, state FROM dba_pdb_saved_states;CON_NAME STATE
-------------------- --------------
PDB1 OPEN
Oracle listener
Create the Oracle listener resource with:
[root@server3 ~]# pcs resource create listener_orcl oralsnr sid="orcl" listener="listener_orcl" --group=oracle[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 2018:21:05 2017 Last change: Thu Apr 2018:21:02 2017 by root via cibadmin on server3.domain.com
2 nodes and 5 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
orcl (ocf::heartbeat:oracle): Started server3.domain.com
listener_orcl (ocf::heartbeat:oralsnr): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server3 ~]# pcs resource create listener_orcl oralsnr sid="orcl" listener="listener_orcl" --group=oracle
[root@server3 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 20 18:21:05 2017 Last change: Thu Apr 20 18:21:02 2017 by root via cibadmin on server3.domain.com2 nodes and 5 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
u01 (ocf::heartbeat:Filesystem): Started server3.domain.com
orcl (ocf::heartbeat:oracle): Started server3.domain.com
listener_orcl (ocf::heartbeat:oralsnr): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Pacemaker graphical interface
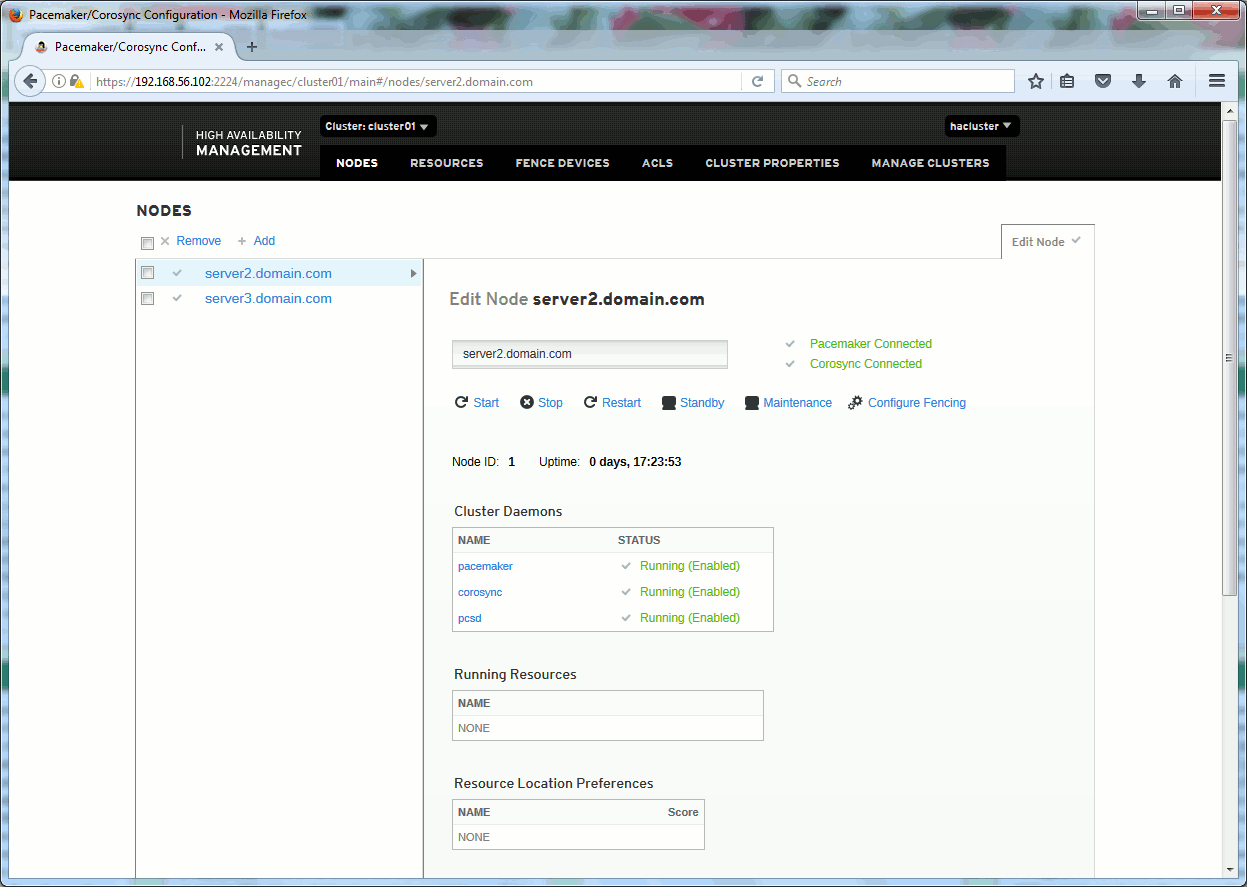
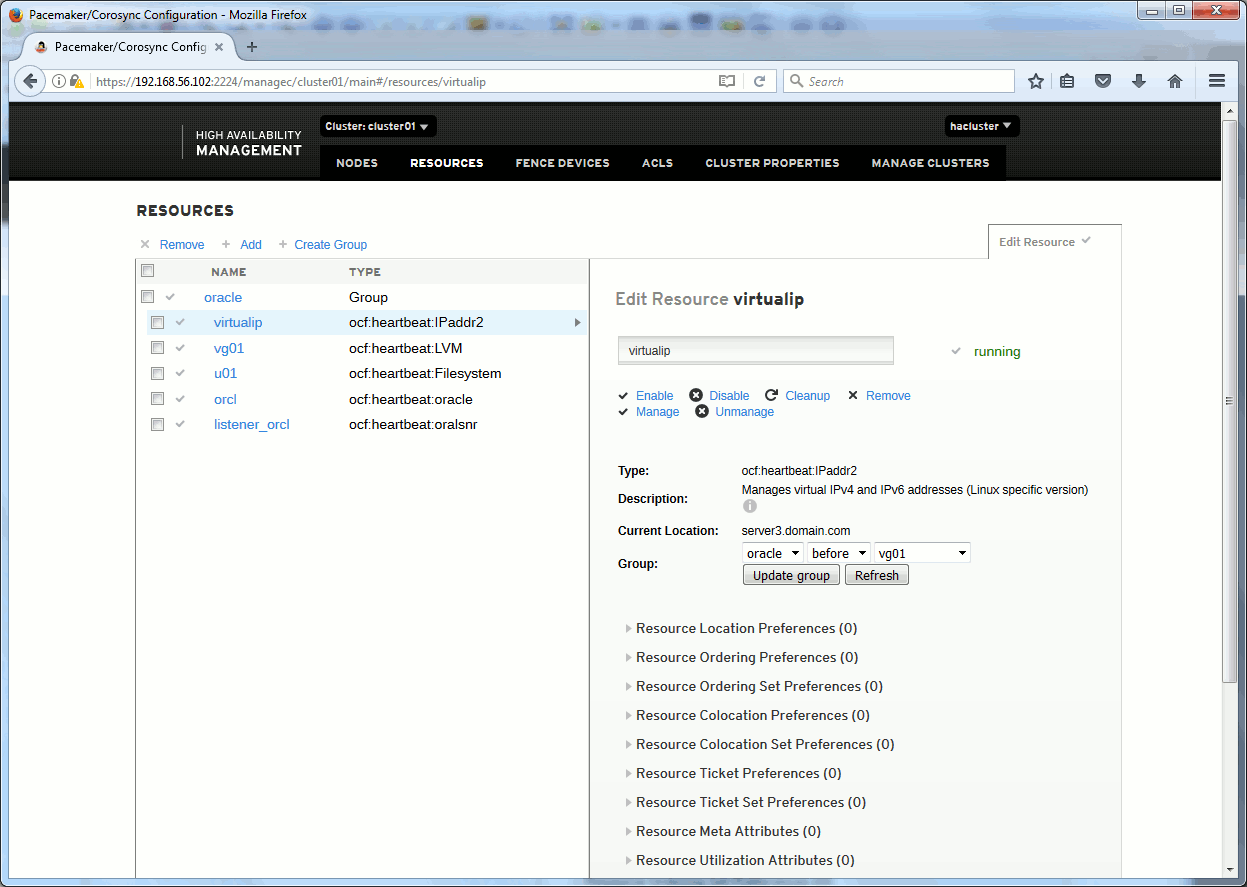
You can go on any node of your cluster in https on port 2224 and get a very nice graphical interface where you can do apparently all the required modification of your cluster. Including the stop/start of resources. Overall this graphical interface is of great help when you want to know which options are available for resources:
pcs01pcs02
Issues encountered
LVM volume group creation
If for any reason you must re-create or simply create the LVM volume group once you have done the configuration to forbid kernel to activate any volume outside of the root one (vg00 in my case) you must use below trick to escape from all LVM error messages.
The error messages you will get are:
[root@server2 ~]# vgcreate vg01 /dev/sdb
Physical volume "/dev/sdb" successfully created.
Volume group "vg01" successfully created
[root@server2 ~]# lvcreate -L 500m -n lvol01 vg01
Volume "vg01/lvol01" is not active locally.
Aborting. Failed to wipe start of new LV.
[root@server2 ~]# vgcreate vg01 /dev/sdb
Physical volume "/dev/sdb" successfully created.
Volume group "vg01" successfully created
[root@server2 ~]# lvcreate -L 500m -n lvol01 vg01
Volume "vg01/lvol01" is not active locally.
Aborting. Failed to wipe start of new LV.
Trying to activate the volume group is not changing anything:
[root@server2 ~]# vgchange -a y vg010 logical volume(s)in volume group "vg01" now active
[root@server2 ~]# vgchange -a y vg01
0 logical volume(s) in volume group "vg01" now active
To overcome the problem use below sequence:
[root@server2 ~]# lvscan
ACTIVE '/dev/vg00/lvol00'[10.00 GiB] inherit
ACTIVE '/dev/vg00/lvol03'[500.00 MiB] inherit
ACTIVE '/dev/vg00/lvol01'[4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol02'[4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol20'[5.00 GiB] inherit
[root@server2 ~]# vgcreate vg01 /dev/sdb --addtag pacemaker --config 'activation { volume_list = [ "@pacemaker" ] }'
Volume group "vg01" successfully created
[root@server2 ~]# lvcreate --addtag pacemaker -L 15g -n lvol01 vg01 --config 'activation { volume_list = [ "@pacemaker" ] }'
Logical volume "lvol01" created.
[root@server2 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvol00 vg00 -wi-ao---- 10.00g
lvol01 vg00 -wi-ao---- 4.00g
lvol02 vg00 -wi-ao---- 4.00g
lvol03 vg00 -wi-ao---- 500.00m
lvol20 vg00 -wi-ao---- 5.00g
lvol01 vg01 -wi-a----- 15.00g
[root@server2 ~]# lvscan
ACTIVE '/dev/vg01/lvol01'[15.00 GiB] inherit
ACTIVE '/dev/vg00/lvol00'[10.00 GiB] inherit
ACTIVE '/dev/vg00/lvol03'[500.00 MiB] inherit
ACTIVE '/dev/vg00/lvol01'[4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol02'[4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol20'[5.00 GiB] inherit
[root@server2 ~]# lvchange -an vg01/lvol01 --deltag pacemaker
Logical volume vg01/lvol01 changed.
[root@server2 ~]# vgchange -an vg01 --deltag pacemaker
Volume group "vg01" successfully changed
0 logical volume(s)in volume group "vg01" now active
[root@server2 ~]# pcs resource create vg01 LVM volgrpname=vg01 exclusive=true --group oracle[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 2017:16:372017 Last change: Thu Apr 2017:16:342017 by root via cibadmin on server2.domain.com
2 nodes and 2 resources configured
Online: [ server2.domain.com server3.domain.com ]
Full list of resources:
Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.com
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@server2 ~]# lvscan
ACTIVE '/dev/vg00/lvol00' [10.00 GiB] inherit
ACTIVE '/dev/vg00/lvol03' [500.00 MiB] inherit
ACTIVE '/dev/vg00/lvol01' [4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol02' [4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol20' [5.00 GiB] inherit
[root@server2 ~]# vgcreate vg01 /dev/sdb --addtag pacemaker --config 'activation { volume_list = [ "@pacemaker" ] }'
Volume group "vg01" successfully created
[root@server2 ~]# lvcreate --addtag pacemaker -L 15g -n lvol01 vg01 --config 'activation { volume_list = [ "@pacemaker" ] }'
Logical volume "lvol01" created.
[root@server2 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lvol00 vg00 -wi-ao---- 10.00g
lvol01 vg00 -wi-ao---- 4.00g
lvol02 vg00 -wi-ao---- 4.00g
lvol03 vg00 -wi-ao---- 500.00m
lvol20 vg00 -wi-ao---- 5.00g
lvol01 vg01 -wi-a----- 15.00g
[root@server2 ~]# lvscan
ACTIVE '/dev/vg01/lvol01' [15.00 GiB] inherit
ACTIVE '/dev/vg00/lvol00' [10.00 GiB] inherit
ACTIVE '/dev/vg00/lvol03' [500.00 MiB] inherit
ACTIVE '/dev/vg00/lvol01' [4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol02' [4.00 GiB] inherit
ACTIVE '/dev/vg00/lvol20' [5.00 GiB] inherit
[root@server2 ~]# lvchange -an vg01/lvol01 --deltag pacemaker
Logical volume vg01/lvol01 changed.
[root@server2 ~]# vgchange -an vg01 --deltag pacemaker
Volume group "vg01" successfully changed
0 logical volume(s) in volume group "vg01" now active
[root@server2 ~]# pcs resource create vg01 LVM volgrpname=vg01 exclusive=true --group oracle
[root@server2 ~]# pcs status
Cluster name: cluster01
Stack: corosync
Current DC: server3.domain.com (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Thu Apr 20 17:16:37 2017 Last change: Thu Apr 20 17:16:34 2017 by root via cibadmin on server2.domain.com2 nodes and 2 resources configuredOnline: [ server2.domain.com server3.domain.com ]Full list of resources:Resource Group: oracle
virtualip (ocf::heartbeat:IPaddr2): Started server3.domain.com
vg01 (ocf::heartbeat:LVM): Started server3.domain.comDaemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Resources constraints
Display resources constraints with:
[root@server2 ~]# pcs constraint show --full
Location Constraints:
Resource: oracle
Enabled on: server3.domain.com (score:INFINITY)(role: Started)(id:cli-prefer-oracle)
Resource: virtualip
Enabled on: server3.domain.com (score:INFINITY)(role: Started)(id:cli-prefer-virtualip)
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
15 thoughts on “Pacemaker configuration for an Oracle database and its listener”
Brian says:
How would you setup orcl (ocf::heartbeat:oracle): Started server3.domain.com for multiple DBs on the same server?
I have 4 Standalone and one CDB on the same Active / Passive Server Cluster.
Would each DB need to have it’s own Resource?
They share one Listener
I would say that yes one resource per database. That you can, or not, put in a pacemaker group for clarity…
The PDBs in your CDB will start automatically if you set them the correct state…
Hello,
very useful document , i’v question related to shared disk between 2 vmw Linux server
can we do that with SAN and what is the mount point parameters ? and do we need the mount point to be read write on both node before we start ?
Thanks.
Yes SAN is the exact perfect technology to share disks between servers ! And no you surely do not mount the same disk on two servers at the same time, unless the software is able to handle this like Oracle RAC.
Ashwin says:
I just happened to come across this blog and found it to be very informative and resourceful.
Very useful and detailed steps. I am able to build the environment. I would like to find out how we can switch to the other node if we shutdown the database in one node. Current configuration tries to restart on the same node. Also how do we extend this to Oracle EBS(E Business Suites) active-passive?
Thanks for comment ! You can move a resource using “pcs resource move” you can also set the location preferences. Last you would do for any other component (Oracle EBS) like you have done for the Oracle database…
Srini Alavala says:
Thanks Yannick for the response.
I would like to avoid the manual step of running the “pcs resource move” command. I am trying to accomplish Active-Passive High Availability. I would like to run Oracle database only on one node to avoid the licensing fee. I run the Oracle Database on the Active Node and monitor the database. whenever the database goes down, I want to shutdown the Active Node and start the Passive node. Starting the passive node automatically start the Oracle Database.
Secondly resource list doesn’t include EBS application. It only support Oracle DB, MySQL, Apache etc. EBS has Concurrent Processing Server & Web/Form Server in addition to Database Server. Is it possible to extend the same concept of monitoring Concurrent Processing and Web/Form applications similar to Oracle DB application? Can we use STONITH and Fencing Rules to monitor a specific process for these two applications?
If the disk where you have installed Oracle binaries is shared (SAN, NAS or whatever) and moving from one node to another then you are safe with Oracle licences.
Again I do not see any technical constraint to use Pacemaker with anything else than an Oracle database. Whatever number of components your EBS solution has you can create a dedicated resource for each of them. But again I don’t know EBS so I might not get the technical point you highlight…
Anilkumar Chintam says:
Hi Srini Alavala,
Could you please share the steps to configure EBS database in Linux HA cluster, we are planning to setup the same.






")
Brian says:
How would you setup orcl (ocf::heartbeat:oracle): Started server3.domain.com for multiple DBs on the same server?
I have 4 Standalone and one CDB on the same Active / Passive Server Cluster.
Would each DB need to have it’s own Resource?
They share one Listener
Thank you
Yannick Jaquier says:
I would say that yes one resource per database. That you can, or not, put in a pacemaker group for clarity…
The PDBs in your CDB will start automatically if you set them the correct state…
Subash Raja C says:
Can we add multiple VGs in LVM Resource
pcs resource create oradb-lvm ocf:heartbeat:LVM-activate vgname=ora-vg,oradata-vg,oraarch-vg,
redo-vg,orabkp-vg vg_access_mode=system_id –group bancsdbgroup
Subash Raja C says:
How to add multiple VGs in LVM Resource Group
sam says:
Hello,
very useful document , i’v question related to shared disk between 2 vmw Linux server
can we do that with SAN and what is the mount point parameters ? and do we need the mount point to be read write on both node before we start ?
Thanks.
Yannick Jaquier says:
Hello,
Thanks !
Yes SAN is the exact perfect technology to share disks between servers ! And no you surely do not mount the same disk on two servers at the same time, unless the software is able to handle this like Oracle RAC.
Ashwin says:
I just happened to come across this blog and found it to be very informative and resourceful.
Yannick Jaquier says:
Welcome and thanks for comment !
SRINI ALAVALA says:
Very useful and detailed steps. I am able to build the environment. I would like to find out how we can switch to the other node if we shutdown the database in one node. Current configuration tries to restart on the same node. Also how do we extend this to Oracle EBS(E Business Suites) active-passive?
Yannick Jaquier says:
Thanks for comment ! You can move a resource using “pcs resource move” you can also set the location preferences. Last you would do for any other component (Oracle EBS) like you have done for the Oracle database…
Srini Alavala says:
Thanks Yannick for the response.
I would like to avoid the manual step of running the “pcs resource move” command. I am trying to accomplish Active-Passive High Availability. I would like to run Oracle database only on one node to avoid the licensing fee. I run the Oracle Database on the Active Node and monitor the database. whenever the database goes down, I want to shutdown the Active Node and start the Passive node. Starting the passive node automatically start the Oracle Database.
Secondly resource list doesn’t include EBS application. It only support Oracle DB, MySQL, Apache etc. EBS has Concurrent Processing Server & Web/Form Server in addition to Database Server. Is it possible to extend the same concept of monitoring Concurrent Processing and Web/Form applications similar to Oracle DB application? Can we use STONITH and Fencing Rules to monitor a specific process for these two applications?
I really appreciate your input!
Yannick Jaquier says:
If the disk where you have installed Oracle binaries is shared (SAN, NAS or whatever) and moving from one node to another then you are safe with Oracle licences.
Again I do not see any technical constraint to use Pacemaker with anything else than an Oracle database. Whatever number of components your EBS solution has you can create a dedicated resource for each of them. But again I don’t know EBS so I might not get the technical point you highlight…
Anilkumar Chintam says:
Hi Srini Alavala,
Could you please share the steps to configure EBS database in Linux HA cluster, we are planning to setup the same.
Thanks
Anil