Table of contents
Preamble
Always on Failover Cluster Instances or FCI for short is the SQL Server feature for High Availability (HA) within the same datacenter. Why within the same datacenter ? Mostly because the feature is based on shared storage.
Always On is an umbrella term for the availability features in SQL Server and covers both availability groups and FCIs. Always On is not the name of the availability group feature.
So Always On is made of:
- Always On Failover Cluster Instance (FCI) or FCI for short
- Always On Availability Group or AG for short
The storage becomes a Single Point Of Failure (SPOF) and, of course, with modern disk array storage you could replicate to another datacenter (not too far away) but by experience we have seen that it is not always working very well. FCI is more for HA in same datacenter where for multi datacenters HA you would go for Always On Availability Groups. Both feature can also be clubbed…
The FCI high level principle is really something well known with a cluster manager that is starting the database engine on a surviving node as well as managing a floating virtual IP address for applicative connection. In the case of SQL Server on Linux the cluster software is Pacemaker (Windows Server Failover Cluster for Windows) and the shared storage is anything in iSCSI, NFS, SMB, SAN…
For my testing I am using a shared disk between two virtual machines running Oracle Linux Server release 8.5 (not certified by Microsoft). My two virtual machines are:
- server1.domain.com with IP address 192.168.56.101
- server2.domain.com with IP address 192.168.56.102
Pacemaker, SQL Server and Linux installation
As I have already done it in a previous article I will go fast even if in OEL/RHEL 8 we have some slight (for the better) changes:
[root@server1 ~]# dnf config-manager --enable ol8_appstream ol8_baseos_latest ol8_addons [root@server1 ~]# dnf install pacemaker pcs fence-agents-all resource-agents [root@server1 ~]# echo secure_password | passwd --stdin hacluster Changing password for user hacluster. passwd: all authentication tokens updated successfully. [root@server1 ~]# systemctl start pcsd [root@server1 ~]# systemctl enable pcsd Created symlink /etc/systemd/system/multi-user.target.wants/pcsd.service → /usr/lib/systemd/system/pcsd.service. |
SQL Server and SQL Server command line tools installation:
[root@server1 ~]# cd /etc/yum.repos.d/ [root@server1 yum.repos.d]# wget https://packages.microsoft.com/config/rhel/7/mssql-server-2019.repo [root@server1 yum.repos.d]# dnf install -y mssql-server [root@server1 yum.repos.d]# wget https://packages.microsoft.com/config/rhel/7/prod.repo [root@server1 yum.repos.d]# dnf install -y mssql-tools unixODBC-devel |
Configure LVM system ID on ALL cluster nodes (this is required for Pacemaker LVM Volume Group activation):
[root@server1 ~]# vi /etc/lvm/lvm.conf [root@server1 ~]# grep "system_id_source =" /etc/lvm/lvm.conf system_id_source = "uname" [root@server1 ~]# lvm systemid system ID: server1.domain.com [root@server1 ~]# uname -n server1.domain.com |
As I am in OEL 8.5 I can use the newest flag –setautoactivation n to create the volume group (much simpler than what was required before). /dev/sdb is a shared disk created in Virtualbox, we have already seen this here (link):
[root@server1 ~]# vgcreate --setautoactivation n vg01 /dev/sdb Physical volume "/dev/sdb" successfully created. Volume group "vg01" successfully created with system ID server1.domain.com |
If you create the volume group without system id configuration you can still post change it with:
[root@server1 ~]# vgchange --systemid server1.domain.com vg01 Volume group "vg01" successfully changed [root@server1 ~]# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID vg00 1 4 0 wz--n- <99.00g <80.90g vg01 1 1 0 wz--n- <2.00g 1020.00m server1.domain.com |
Create the logical volume:
[root@server1 ~]# lvcreate -n lvol01 -L 1G vg01 Logical volume "lvol01" created. [root@server1 ~]# mkfs -t xfs /dev/vg01/lvol01 meta-data=/dev/vg01/lvol01 isize=512 agcount=4, agsize=65536 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 data = bsize=4096 blocks=262144, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 |
And associated file system:
[root@server1 ~]# mkdir /mssql [root@server1 ~]# systemctl daemon-reload [root@server1 ~]# mount -t xfs /dev/vg01/lvol01 /mssql [root@server1 ~]# df -h /mssql Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg01-lvol01 1014M 40M 975M 4% /mssql [root@server1 ~]# chown -R mssql:mssql /mssql |
As mssql account create the needed directories:
[mssql@server1 ~]$ mkdir -p /mssql/data /mssql/log /mssql/dump /mssql/backup/ /mssql/masterdatabasedir/ |
As root execute below script to customize your SQL Server installation (if you configure everything before starting SQL Server service then all database files will directly be in good directory):
/opt/mssql/bin/mssql-conf set network.tcpport 1443 /opt/mssql/bin/mssql-conf set filelocation.defaultdatadir /mssql/data /opt/mssql/bin/mssql-conf set filelocation.defaultlogdir /mssql/log /opt/mssql/bin/mssql-conf set filelocation.defaultdumpdir /mssql/dump /opt/mssql/bin/mssql-conf set filelocation.defaultbackupdir /mssql/backup/ /opt/mssql/bin/mssql-conf set filelocation.masterdatafile /mssql/masterdatabasedir/master.mdf /opt/mssql/bin/mssql-conf set filelocation.masterlogfile /mssql/masterdatabasedir/mastlog.ldf /opt/mssql/bin/mssql-conf set memory.memorylimitmb 1024 |
configure corosync with hacluster user using:
[root@server1 ~]# pcs host auth server1.domain.com server2.domain.com -u hacluster Password: server2.domain.com: Authorized server1.domain.com: Authorized [root@server1 ~]# pcs status corosync Membership information ---------------------- Nodeid Votes Name 1 1 server1.domain.com (local) 2 1 server2.domain.com |
Create the cluster with something like:
[root@server1 ~]# pcs cluster setup cluster01 server1.domain.com addr=192.168.56.101 server2.domain.com addr=192.168.56.102 Destroying cluster on hosts: 'server1.domain.com', 'server2.domain.com'... server1.domain.com: Successfully destroyed cluster server2.domain.com: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'server1.domain.com', 'server2.domain.com' server1.domain.com: successful removal of the file 'pcsd settings' server2.domain.com: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'server1.domain.com', 'server2.domain.com' server1.domain.com: successful distribution of the file 'corosync authkey' server1.domain.com: successful distribution of the file 'pacemaker authkey' server2.domain.com: successful distribution of the file 'corosync authkey' server2.domain.com: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'server1.domain.com', 'server2.domain.com' server1.domain.com: successful distribution of the file 'corosync.conf' server2.domain.com: successful distribution of the file 'corosync.conf' Cluster has been successfully set up. |
Few additional configuration, please refer to Microsoft SQL Server on Linux official documentation:
[root@server1 ~]# pcs cluster start --all server1.domain.com: Starting Cluster... server2.domain.com: Starting Cluster... [root@server1 ~]# pcs cluster enable --all server1.domain.com: Cluster Enabled server2.domain.com: Cluster Enabled [root@server1 ~]# pcs property set stonith-enabled=false [root@server1 ~]# pcs property set no-quorum-policy=ignore [root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Thu Nov 25 12:28:42 2021 * Last change: Thu Nov 25 12:12:33 2021 by root via cibadmin on server1.domain.com * 2 nodes configured * 0 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com ] Full List of Resources: * No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
Failover Cluster Instances Pacemaker configuration
Creation of the virtual IP that will move across cluster nodes (I have chosen to use 192.168.56.99 to remain in the same range of my two virtual machines):
[root@server1 ~]# pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=192.168.56.99 cidr_netmask=32 nic=enp0s3 op monitor interval=30s [root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Thu Nov 25 12:30:58 2021 * Last change: Thu Nov 25 12:30:31 2021 by root via cibadmin on server1.domain.com * 2 nodes configured * 1 resource instance configured Node List: * Online: [ server1.domain.com server2.domain.com ] Full List of Resources: * virtualip (ocf::heartbeat:IPaddr2): Started server1.domain.com Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
You can already confirm that this first resource is working:
[root@server1 ~]# ip addr show dev enp0s3 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 08:00:27:27:b1:1a brd ff:ff:ff:ff:ff:ff inet 192.168.56.101/24 brd 192.168.56.255 scope global noprefixroute enp0s3 valid_lft forever preferred_lft forever inet 192.168.56.99/32 scope global enp0s3 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fe27:b11a/64 scope link valid_lft forever preferred_lft forever |
And can switch to your other cluster node with:
[root@server1 ~]# pcs resource move virtualip server2.domain.com |
For my LVM volume group what to use ?:
[root@server1 ~]# pcs resource list ocf:heartbeat | grep -i lvm ocf:heartbeat:LVM-activate - This agent activates/deactivates logical volumes. ocf:heartbeat:lvmlockd - This agent manages the lvmlockd daemon |
Create the Volume Group resource (pcs resource describe LVM-activate):
[root@server1 ~]# pcs resource create vg01 ocf:heartbeat:LVM-activate vgname=vg01 vg_access_mode=system_id activation_mode=exclusive |
Create the Pacemaker filesystem resource with:
[root@server1 ~]# pcs resource create mssql ocf:heartbeat:Filesystem device="/dev/vg01/lvol01" directory="/mssql" fstype="xfs" |
Create a resource group (msqsql01) with (for probably good reason my resources got distributed on all cluster nodes which is exactly what I do not want):
[root@server1 /]# pcs resource group add mssql01 virtualip vg01 mssql [root@server1 /]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Thu Nov 25 15:42:13 2021 * Last change: Thu Nov 25 15:41:26 2021 by hacluster via crmd on server2.domain.com * 2 nodes configured * 3 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com ] Full List of Resources: * Resource Group: mssql01: * virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.com * vg01 (ocf::heartbeat:LVM-activate): Started server2.domain.com * mssql (ocf::heartbeat:Filesystem): Started server2.domain.com Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
Create the Pacemaker SQL Server account with:
[mssql@server1 ~]$ sqlcmd -S localhost,1443 -U SA Password: 1> use master 2> go Changed database context to 'master'. 1> create login pacemaker with password=N'Passw0rd!*' 2> go 1> alter server role [sysadmin] add member [pacemaker] 2> go 1> |
Copy the machine key to all cluster nodes, I have also copied the SQL Server configuration file that I updated on server1.domain.com (the file is on a local file system):
[root@server1 ~]# ll /var/opt/mssql/mssql.conf -rw-r--r-- 1 root root 349 Nov 25 16:53 mssql.conf [mssql@server1 ~]$ scp /var/opt/mssql/mssql.conf server2:/var/opt/mssql/ mssql@server2's password: mssql.conf [mssql@server1 ~]$ scp /var/opt/mssql/secrets/machine-key server2:/var/opt/mssql/secrets/ mssql@server2's password: machine-key |
Create a file to store the SQL Server username and password for the Pacemaker login:
[root@server1 ~]# touch /var/opt/mssql/secrets/passwd [root@server1 ~]# echo pacemaker | sudo tee -a /var/opt/mssql/secrets/passwd pacemaker [root@server1 ~]# echo 'Passw0rd!*' | sudo tee -a /var/opt/mssql/secrets/passwd Passw0rd!* [root@server1 ~]# chown root:root /var/opt/mssql/secrets/passwd [root@server1 ~]# chmod 600 /var/opt/mssql/secrets/passwd [root@server1 ~]# cat /var/opt/mssql/secrets/passwd pacemaker Passw0rd!* |
As requested added SQL Server resource agent for Pacemaker additional package:
[root@server1 ~]# dnf -y install mssql-server-ha |
Create the SQL Server High Availability resource with (could use –group to avoid second command):
[root@server1 ~]# pcs resource create mssqlha ocf:mssql:fci [root@server1 ~]# pcs resource group add mssql01 mssqlha |
My FCI resource failed and in fact created a complete mess onto my cluster by stopping all other resources, I have found (journactl -xlf):
Nov 25 18:10:43 server2.domain.com fci(mssqlha)[47500]: INFO: start: 2021/11/25 18:10:43 From RetryExecute - Attempt 14 to connect to the instance at localhost:1433 Nov 25 18:10:43 server2.domain.com fci(mssqlha)[47506]: INFO: start: 2021/11/25 18:10:43 Attempt 14 returned error: Unresponsive or down Unable to open tcp connection with host 'localhost:1433': dial tcp 127.0.0.1:1433: getsockopt: connection refused |
Obviously I’m not using default listening port so tried:
[root@server1 pacemaker]# pcs resource config mssqlha Resource: mssqlha (class=ocf provider=mssql type=fci) Operations: monitor interval=10 timeout=30 (mssqlha-monitor-interval-10) start interval=0s timeout=1000 (mssqlha-start-interval-0s) stop interval=0s timeout=20 (mssqlha-stop-interval-0s) |
No available option because correct command is (few references on this…):
[root@server1 ~]# pcs resource describe ocf:mssql:fci . . [root@server1 ~]# pcs resource update mssqlha port=1443 [root@server1 ~]# pcs resource config mssqlha Resource: mssqlha (class=ocf provider=mssql type=fci) Attributes: port=1443 Operations: monitor interval=10 timeout=30 (mssqlha-monitor-interval-10) start interval=0s timeout=1000 (mssqlha-start-interval-0s) stop interval=0s timeout=20 (mssqlha-stop-interval-0s) |
After this last command all was working well. Sometimes you have to wait a while to have Pacemaker purging the error message and getting corerct status of resources…

SQL Server failover testing
To test the failover I have started from this situation:
[root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Fri Nov 26 11:03:23 2021 * Last change: Fri Nov 26 10:32:17 2021 by hacluster via crmd on server1.domain.com * 2 nodes configured * 4 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com ] Full List of Resources: * Resource Group: mssql01: * virtualip (ocf::heartbeat:IPaddr2): Started server1.domain.com * vg01 (ocf::heartbeat:LVM-activate): Started server1.domain.com * mssql (ocf::heartbeat:Filesystem): Started server1.domain.com * mssqlha (ocf::mssql:fci): Started server1.domain.com Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
And to simulate a node crash I have issued:
[root@server1 ~]# pcs node standby server1.domain.com |
After a short period I now have:
[root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Fri Nov 26 11:26:27 2021 * Last change: Fri Nov 26 11:14:16 2021 by root via cibadmin on server1.domain.com * 2 nodes configured * 4 resource instances configured Node List: * Node server1.domain.com: standby * Online: [ server2.domain.com ] Full List of Resources: * Resource Group: mssql01: * virtualip (ocf::heartbeat:IPaddr2): Started server2.domain.com * vg01 (ocf::heartbeat:LVM-activate): Started server2.domain.com * mssql (ocf::heartbeat:Filesystem): Started server2.domain.com * mssqlha (ocf::mssql:fci): Started server2.domain.com Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
And obviously I can still connect with SQL Server Management Studio (SSMS) using my 192.168.56.99 virtual IP. Well in fact I can also connect with the node IP address so I have changed (on all cluster nodes because my SQL Server configuration file, mssql.conf, is on a local file system):
[root@server1 ~]# /opt/mssql/bin/mssql-conf set network.ipaddress 192.168.56.99 SQL Server needs to be restarted in order to apply this setting. Please run 'systemctl restart mssql-server.service'. [root@server1 ~]# grep ipaddress ~mssql/mssql.conf ipaddress = 192.168.56.99 |
I unstandby my server and moved the SQL Server instance back to server1.domain.com, and as I have a group all resources will also move:
[root@server1 ~]# pcs node unstandby server1.domain.com [root@server1 ~]# pcs resource move mssqlha server1.domain.com [root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Fri Nov 26 11:49:01 2021 * Last change: Fri Nov 26 11:48:58 2021 by root via crm_resource on server1.domain.com * 2 nodes configured * 4 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com ] Full List of Resources: * Resource Group: mssql01: * virtualip (ocf::heartbeat:IPaddr2): Started server1.domain.com * vg01 (ocf::heartbeat:LVM-activate): Started server1.domain.com * mssql (ocf::heartbeat:Filesystem): Started server1.domain.com * mssqlha (ocf::mssql:fci): Starting server1.domain.com Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
And now SQl Server is correctly binding only on my virtual IP address:
[root@server1 ~]# netstat -an | grep LISTEN | grep 1443 tcp 0 0 192.168.56.99:1443 0.0.0.0:* LISTEN |
Starting from this I have discovered that the SQL Server agent was not working as expected (journalctl -xlf):
Nov 26 15:11:39 server2 fci(mssqlha)[329569]: INFO: start: 2021/11/26 15:11:39 From RetryExecute - Attempt 1 to connect to the instance at localhost:1443 Nov 26 15:11:39 server2 fci(mssqlha)[329569]: INFO: start: 2021/11/26 15:11:39 Attempt 1 returned error: Unresponsive or down Unable to open tcp connection with host 'localhost:1443': dial tcp 127.0.0.1:1443: getsockopt: connection refused |
This error message is normal as it is no more possible to connect to cluster node IP address or localhost… 192.168.56.99 must be used…
Looking at Failover Cluster Instances resource agent processes:
[root@server2 ~]# ps -ef | grep fci |grep -v grep root 329569 7752 0 15:04 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/fci start root 338459 329569 0 15:12 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/fci start root 338460 338459 0 15:12 ? 00:00:00 /usr/lib/ocf/lib/mssql/fci-helper --port 1443 --credentials-file /var/opt/mssql/secrets/passwd --application-name monitor-mssqlha-start --connection-timeout 20 --health-threshold 3 --action start --virtual-server-name mssqlha root 338461 338459 0 15:12 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/fci start |
I have tried to see if there any otpino to specify hostname, and yes there is:
[root@server2 ~]# /usr/lib/ocf/lib/mssql/fci-helper -h Usage of /usr/lib/ocf/lib/mssql/fci-helper: -action string One of --start, --monitor start: Start the replica on this node. monitor: Monitor the replica on this node. -application-name string The application name to use for the T-SQL connection. -connection-timeout int The connection timeout in seconds. The application will retry connecting to the instance until this time elapses. Default: 30 (default 30) -credentials-file string The path to the credentials file. -health-threshold uint The instance health threshold. Default: 3 (SERVER_CRITICAL_ERROR) (default 3) -hostname string The hostname of the SQL Server instance to connect to. Default: localhost (default "localhost") -monitor-interval-timeout int The monitor interval timeout in seconds. For FCI this is expected to be always Default: 0 -port uint The port on which the instance is listening for logins. -virtual-server-name string The virtual server name that should be set on the SQL Server instance. |
But unfortunately /usr/lib/ocf/resource.d/mssql/fci script is not specifying this option (a modification of the script is however possible):
command_output="$( "$FCI_HELPER_BIN" \ --port "$OCF_RESKEY_port" \ --credentials-file "$OCF_RESKEY_monitoring_credentials_file" \ --application-name "monitor-$OCF_RESOURCE_INSTANCE-monitor" \ --connection-timeout "$OCF_RESKEY_monitor_timeout" \ --health-threshold "$OCF_RESKEY_monitor_policy" \ --action monitor \ --virtual-server-name "$OCF_RESOURCE_INSTANCE" \ 2>&1 | |
I have tried to update the value but the parameter hostname is not exposed in ocf::mssql:fci Pacemaker resource:
[root@server1 mssql]# pcs resource update mssqlha hostname=mssqlha.domain.com Error: invalid resource option 'hostname', allowed options are: 'binary', 'login_retries', 'monitor_policy', 'monitor_timeout', 'monitoring_credentials_file', 'mssql_args', 'port', 'status_file', 'stop_timeout', 'user', 'working_dir', use --force to override [root@server1 mssql]# pcs resource update mssqlha hostname=mssqlha.domain.com --force Warning: invalid resource option 'hostname', allowed options are: 'binary', 'login_retries', 'monitor_policy', 'monitor_timeout', 'monitoring_credentials_file', 'mssql_args', 'port', 'status_file', 'stop_timeout', 'user', 'working_dir' |
My last trial has been to try to insert in /etc/hosts of my cluster nodes the virtual server name, but again this is not used (–virtual-server-name of fci-helper):
192.168.56.99 mssqlha mssqlha.domain.com |
So I had to revert this IP address binding… A bit desapointing from security standpoint…
Conclusion
Again working seamless and my main issues where purely related to Pacemaker itself. When you master Pacemaker (not my case) inserting a SQL Server instance in it will be piece of cake.
One very good help is the graphical interface accessible with (any cluster node, https and port 2224):
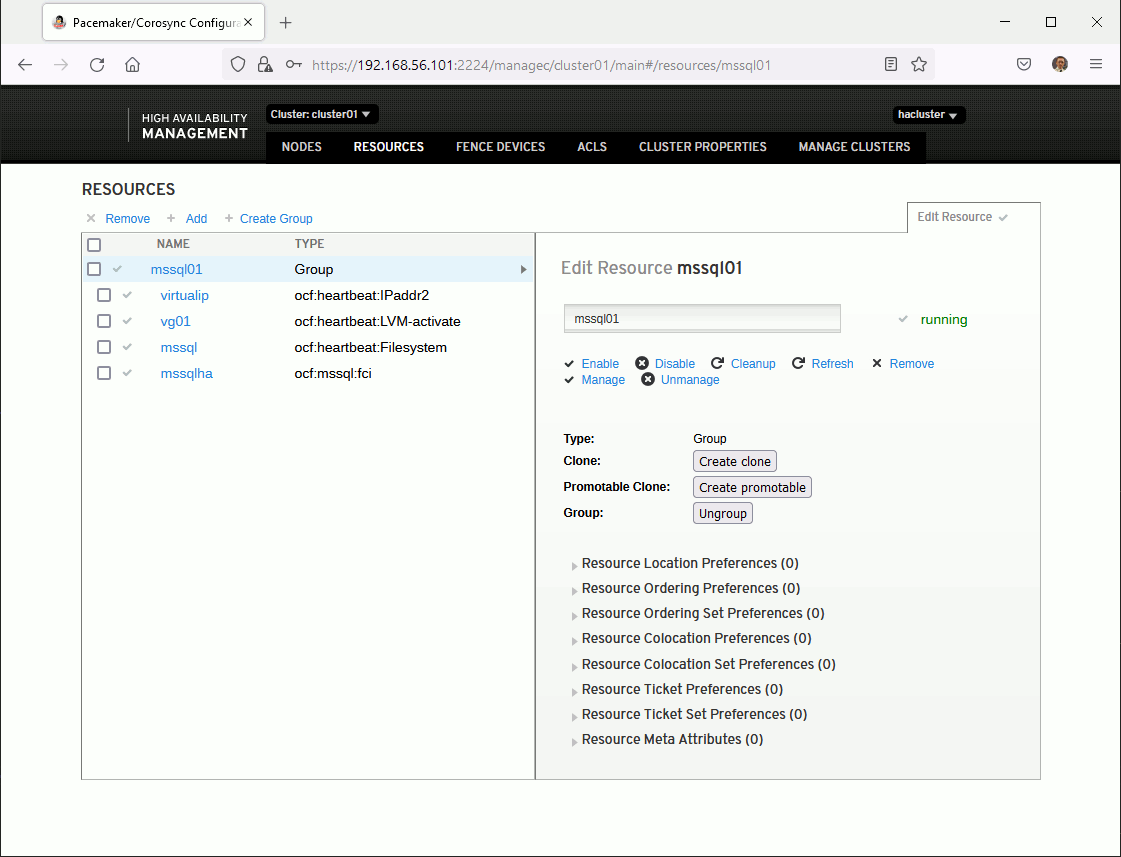
Of course everything can be done command line, but for beginner like me it helps…
I have the feeling that Pacemaker is starting resources in the order they appear in the group but if you want to be really sure of the order you can do (of course the file system cannot be there if the volume group is not there and so on):
[root@server1 ~]# pcs constraint order set virtualip vg01 mssql mssqlha [root@server1 ~]# pcs constraint order config --full Ordering Constraints: Resource Sets: set virtualip vg01 mssql mssqlha (id:order_set_vpv1ml_set) (id:order_set_vpv1ml) |
References
- CHAPTER 5. CONFIGURING AN ACTIVE/PASSIVE APACHE HTTP SERVER IN A RED HAT HIGH AVAILABILITY CLUSTER
- Creating a Service and Testing Failover
- Configure failover cluster instance – SQL Server on Linux (RHEL)
- Failover Cluster Instances – SQL Server on Linux




