Even if we upgraded our HortonWorks Hadoop Platform (HDP) to 3.1.4 to solve many HDP 2 issues we still encountered few components that are failing for unexpected reason and/or that keep increasing their memory usage, and never decreasing, for no particular reason (at least not one we have found so far) like Hive Metastore.
Of course we are using Ambari (2.7.4) and Hive Dashboard (Grafana) but this is only in a reactive approach to stop/start components and to proactively monitor memory usage and so on.
To try to automate we decided to investigate Ambari API and Ambari Metrics System (AMS). The documentation of those two components is not the best I have seen and it might be difficult to enter into the usage of those two components. But once the basic understanding is there the limit on what’s possible to do is infinite…
AMS will be to programmatically get what you would get from Grafana and then trigger an action with Ambari API to restart a component.
All the script below with be in Python 3.8.6 using Python HTTP-speaking package requests for convenience. I guess it can be transposed to any language of your choice but around Big Data platform (and in general) Python is quite popular…
Ambari Metrics System (AMS)
The idea behind the usage of this RESTAPI is to get latest memory usage and configured maximum memory usage value of Hive Metastore.
First identify your AMS server by clicking on Ambari Metrics service and getting details of Metric Collector component:
ams01
Once you have identified your AMS server (that will be call AMS_SERVER in below) check you can access the REATAPI by using http://AMS_SERVER:6188/ws/v1/timeline/metrics/hosts or http://AMS_SERVER:6188/ws/v1/timeline/metrics/metadata urls in a web browser. First url is giving a picture of your servers with their associated components that I cannot share here and second url is giving a list of all the available metrics (the Firefox 84.0.2 display is much better than Chrome one as JSON output is formatted, you can even filter it):
ams02
To get metrics value you must HTTP GET on a rule of the form:
If you want only the latest raw value of one or many metric names you can omit appId, startTime, endTime and precision parameters of the url…
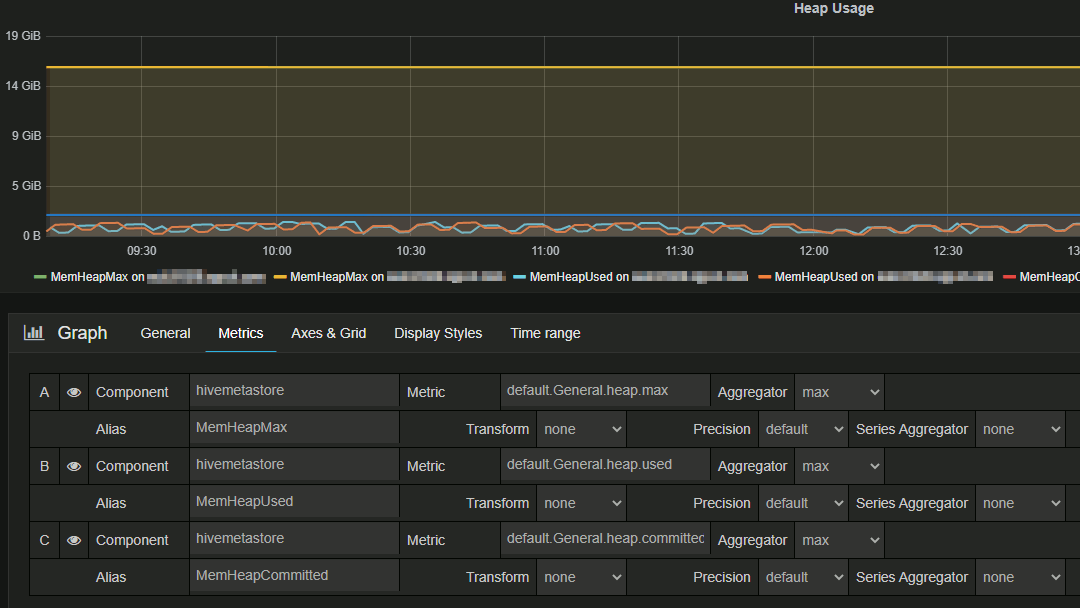
Then to know which metrics name you need to get you can use your Ambari Grafana component and after authentication you can edit any chart and get metric name (in my example I have my Hive Metastore running on two different hosts):
ams03
So I need to get default.General.heap.max and default.General.heap.used metric names from the hostnames(s) where is running the metastore appId. In other words an url with this parameter: metricNames=default.General.heap.max,default.General.heap.used&appId=hivemetastore&hostname=hiveserver01.domain.com
In Python it gives something like:
import requests
import json
# -----------------------------------------------------------------------------# Functions# -----------------------------------------------------------------------------def human_readable(num):
"""
this function will convert bytes to MB.... GB... etc
"""
step_unit =1024.0for x in['bytes','KB','MB','GB','TB']:
if num < step_unit:
return"%3.1f %s" % (num, x)
num /= step_unit
# -----------------------------------------------------------------------------# Variables# -----------------------------------------------------------------------------
AMS_SERVER ='amshost01.domain.com'
AMS_PORT ='6188'
AMS_URL ='http://' + AMS_SERVER + ':' + AMS_PORT + '/ws/v1/timeline/'# -----------------------------------------------------------------------------# Main# -----------------------------------------------------------------------------try:
request01 = requests.get(AMS_URL + "metrics?metricNames=default.General.heap.max,default.General.heap.used&appId=hivemetastore&hostname=hiveserver01.domain.com")
request01_dict = json.loads(request01.text)
output ={}for row in request01_dict['metrics']:
for key01, value01 in row.items():
if key01 =='metricname':
metricname = value01
if key01 =='metrics':
for key02, value02 in value01.items():
metricvalue = value02
output[metricname]= metricvalue
print('Hive Metastore Heap Max: ' + human_readable(output['default.General.heap.max']))print('Hive Metastore Heap Used: ' + human_readable(output['default.General.heap.used']))print(("Hive Metastore percentage memory used: {:.0f}").format(output['default.General.heap.used']*100/output['default.General.heap.max']))except:
print("Cannot contact AMS server")
exit(1)
exit(0)
import requests
import json# -----------------------------------------------------------------------------
# Functions
# -----------------------------------------------------------------------------
def human_readable(num):
"""
this function will convert bytes to MB.... GB... etc
"""
step_unit = 1024.0
for x in ['bytes', 'KB', 'MB', 'GB', 'TB']:
if num < step_unit:
return "%3.1f %s" % (num, x)
num /= step_unit# -----------------------------------------------------------------------------
# Variables
# -----------------------------------------------------------------------------
AMS_SERVER = 'amshost01.domain.com'
AMS_PORT = '6188'
AMS_URL = 'http://' + AMS_SERVER + ':' + AMS_PORT + '/ws/v1/timeline/'# -----------------------------------------------------------------------------
# Main
# -----------------------------------------------------------------------------try:
request01 = requests.get(AMS_URL + "metrics?metricNames=default.General.heap.max,default.General.heap.used&appId=hivemetastore&hostname=hiveserver01.domain.com")
request01_dict = json.loads(request01.text)
output = {}
for row in request01_dict['metrics']:
for key01, value01 in row.items():
if key01 == 'metricname':
metricname = value01
if key01 == 'metrics':
for key02, value02 in value01.items():
metricvalue = value02
output[metricname] = metricvalue
print('Hive Metastore Heap Max: ' + human_readable(output['default.General.heap.max']))
print('Hive Metastore Heap Used: ' + human_readable(output['default.General.heap.used']))
print(("Hive Metastore percentage memory used: {:.0f}").format(output['default.General.heap.used']*100/output['default.General.heap.max']))
except:
print("Cannot contact AMS server")
exit(1)exit(0)
You can obviously double-check in Grafana to be 100% sure you are returning what you expect…
Ambari API
In this first chapter we have seen how to get metrics information of your components that can be used to trigger an action of this component. To trigger this action by script you need to use Ambari API.
As you are using Ambari you need to have an Ambari account and password to execute this RESTAPI. This is simple to implement with Python requests package.
All
The first information you need to get is the cluster name you have chosen when installing HDP. In Python this can simply be done with, in below AMBARI_URL is in the form of ‘http://’ + AMBARI_SERVER + ‘:’ + AMBARI_PORT + ‘/api/v1/clusters/’. For example ‘http://ambariserver01.domain.com:8080/api/v1/clusters/’
To get service status (SERVICE is the variable containing your service name). I replace INSTALLED by STOPPED because a service/component is in INSTALLED state when stopped:
To get component status (SERVICE and COMPONENT variables respectively contains service and componentn anmes):
try:
request01 = requests.get(AMBARI_URL + cluster_name + '/services/' + SERVICE + '/components/' + COMPONENT, auth=('ambari_account','ambari_password'))
request01_dict = json.loads(request01.text)# If a componennt is running on multiple hostsfor row in request01_dict["host_components"]:
print('Component ' + COMPONENT + ' of service ' + SERVICE + ' running on ' + row["HostRoles"]["host_name"] + ' status: '+ request01_dict['ServiceComponentInfo']['state'].replace("INSTALLED","STOPPED"))except:
logging.error("Cannot contact Ambari server")print("Cannot contact Ambari server")
exit(1)
try:
request01 = requests.get(AMBARI_URL + cluster_name + '/services/' + SERVICE + '/components/' + COMPONENT, auth=('ambari_account', 'ambari_password'))
request01_dict = json.loads(request01.text)
# If a componennt is running on multiple hosts
for row in request01_dict["host_components"]:
print('Component ' + COMPONENT + ' of service ' + SERVICE + ' running on ' + row["HostRoles"]["host_name"] + ' status: '+ request01_dict['ServiceComponentInfo']['state'].replace("INSTALLED","STOPPED"))
except:
logging.error("Cannot contact Ambari server")
print("Cannot contact Ambari server")
exit(1)
Stop services and components
To stop a service you need an HTTP PUT request, so with a body to simply overwrite the state of the service/component by INSTALLED. Context can be customize to see self explaining display in Ambari web application like this:
ambari_api01
You must also set the header of your PUT request. The PUT request return a message to tell you if your request has been accepted or not:
What I have finally done is an executable file with parameters (using args python package) and I have now an usable script to interreact with components. This script can be given to level 1 operations to perform routine action while on duty like:
# ./ambari_restapi.py --help
usage: ambari_restapi.py [-h][--list_services][--list_components][--status][--service SERVICE][--component COMPONENT][--stop][--start]
optional arguments:
-h, --help show this help message and exit
--list_services List all services
--list_components List all components
--status Status of service or component, works in conjunction with --service or --component--service SERVICE Service name
--component COMPONENT
Component name
--stop Stop service or component, works in conjunction with --service or --component--start Start service or component, works in conjunction with --service or --component# ./ambari_restapi.py --list_services
AMBARI_INFRA_SOLR
AMBARI_METRICS
HBASE
HDFS
HIVE
MAPREDUCE2
OOZIE
PIG
SMARTSENSE
SPARK2
TEZ
YARN
ZEPPELIN
ZOOKEEPER
# ./ambari_restapi.py --help
usage: ambari_restapi.py [-h] [--list_services] [--list_components] [--status] [--service SERVICE] [--component COMPONENT] [--stop] [--start]optional arguments:
-h, --help show this help message and exit
--list_services List all services
--list_components List all components
--status Status of service or component, works in conjunction with --service or --component
--service SERVICE Service name
--component COMPONENT
Component name
--stop Stop service or component, works in conjunction with --service or --component
--start Start service or component, works in conjunction with --service or --component# ./ambari_restapi.py --list_services
AMBARI_INFRA_SOLR
AMBARI_METRICS
HBASE
HDFS
HIVE
MAPREDUCE2
OOZIE
PIG
SMARTSENSE
SPARK2
TEZ
YARN
ZEPPELIN
ZOOKEEPER
Then with a monitoring tool if the AMS result is above a defined threshold we can trigger action using Ambari API script…







SJ says:
Hi, I’m seeing “server error” – can you help?
Code:
host = https://myhost.domain.com
url = self.options[“host”] + “/api/v1/clusters/” + cluster_name + “/hosts/” + host_name + “/host_components/” + component
data={“HostRoles”: {“state”: “INSTALLED”}}
services = requests.put(url, json=data, headers=self.options[“http_header”], auth=(self.options[“user”], self.options[“password”]))
Error:
12-Jul-21 13:34:06 – {
“status”: 500,
“message”: “Server Error”
}
12-Jul-21 13:34:06 – Server Error
12-Jul-21 13:34:06 – 500
12-Jul-21 13:34:06 – None
Yannick Jaquier says:
Hi,
Difficult to help from remote…
I don’t see a port number in your script excerpt: normal ?