Table of contents
Preamble
We have seen in first part binaries installation and basic components configuration. Second part will be simple test case configuration as well as trying to make it working…
The GoldenGate for Big Data integration with Kafka is possible through three different Kafka Handlers also called connectors:
- Kafka Generic Handler (Pub/Sub)
- Kafka Connect Handler
- Kafka REST Proxy Handler
Only the two first are available under the Opensource Apache Licensed version so we will review only those two. Oracle has written few articles on the differences (see references section) but those small sentences sum-up it well:
Kafka Handler
Can send raw bytes messages in four formats: JSON, Avro, XML, delimited text
Kafka Connect Handler
Generates in-memory Kafka Connect schemas and messages. Passes the messages to Kafka Connect converter to convert to bytes to send to Kafka.
There are currently only two converters: JSON and Avro. Only Confluent currently has Avro. But using the Kafka Connect interface allows the user to integrate with the open source Kafka Connect connectors.
This picture from Oracle corporation (see references section for complete article) summarize it well:
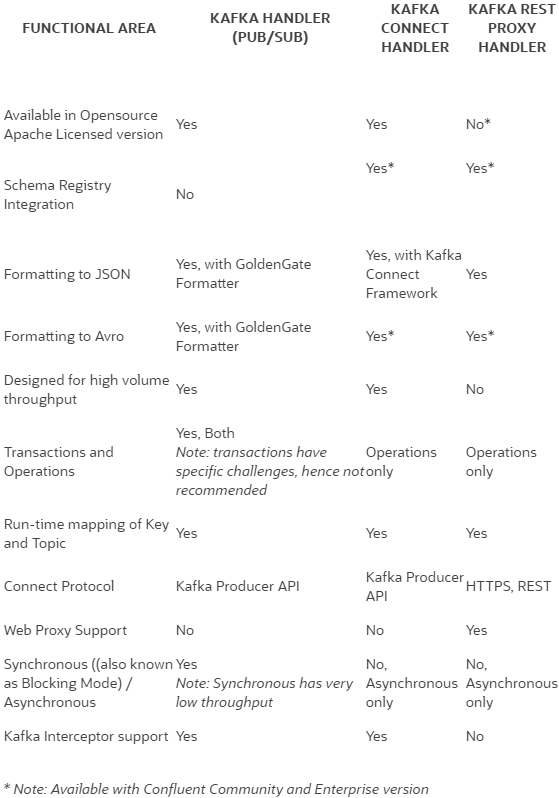
I initially thought the Kafka Connect Handler was provided as a plugin by Conluent but it is included by default in defaut Apache Kafka:
The Kafka Connect framework is also included in the Apache versions as well as Confluent version.
So it is possible to run the OGG Kafka Connect Handler with Apache Kafka. And it is possible to run open source Kafka Connect connectors with Apache Kafka.
One thing Confluent Kafka has that Apache Kafka does not is the Avro schema registry and the Avro Converter.
Oracle test case creation
My simple test case, created in my pdb1 pluggable database, will be as follow:
SQL> CREATE USER appuser IDENTIFIED BY secure_password; USER created. SQL> GRANT CONNECT, RESOURCE TO appuser; GRANT succeeded. SQL> ALTER USER appuser quota unlimited ON users; USER altered. SQL> CONNECT appuser/secure_password@pdb1 Connected. SQL> CREATE TABLE test01(id NUMBER, descr VARCHAR2(50), CONSTRAINT TEST01_PK PRIMARY KEY (id) ENABLE); TABLE created. SQL> DESC test01 Name NULL? TYPE ----------------------------------------- -------- ---------------------------- ID NOT NULL NUMBER DESCR VARCHAR2(50) |
GoldenGate extract configuration
In this chapter I create an extract (capture) process to extract figures from my appuser.test01 test table:
GGSCI (server01) 1> add credentialstore Credential store created. GGSCI (server01) 2> alter credentialstore add user c##ggadmin@orcl alias c##ggadmin Password: Credential store altered. GGSCI (server01) 3> info credentialstore Reading from credential store: Default domain: OracleGoldenGate Alias: ggadmin Userid: c##ggadmin@orcl |
Use ‘alter credentialstore delete user’ to remove an alias…
GGSCI (server01) 11> dblogin useridalias c##ggadmin Successfully logged into database CDB$ROOT. GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 10> add trandata pdb1.appuser.test01 2021-01-22 10:55:21 INFO OGG-15131 Logging of supplemental redo log data is already enabled for table PDB1.APPUSER.TEST01. 2021-01-22 10:55:21 INFO OGG-15135 TRANDATA for instantiation CSN has been added on table PDB1.APPUSER.TEST01. 2021-01-22 10:55:21 INFO OGG-10471 ***** Oracle Goldengate support information on table APPUSER.TEST01 ***** Oracle Goldengate support native capture on table APPUSER.TEST01. Oracle Goldengate marked following column as key columns on table APPUSER.TEST01: ID. |
Configure the extract process (ERROR: Invalid group name (must be at most 8 characters).):
GGSCI (server01) 10> dblogin useridalias c##ggadmin Successfully logged into database CDB$ROOT. GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 11> edit params ext01 GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 12> view params ext01 extract ext01 useridalias c##ggadmin ddl include mapped exttrail ./dirdat/ex sourcecatalog pdb1 table appuser.test01 |
Add, register extract and add the EXTTRAIL (name must be 2 characters or less !):
GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 19> add extract ext01, integrated tranlog, begin now EXTRACT (Integrated) added. GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 20> register extract ext01 database container (pdb1) 2021-01-22 11:06:30 INFO OGG-02003 Extract EXT01 successfully registered with database at SCN 7103554. GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 21> add exttrail ./dirdat/ex, extract ext01 EXTTRAIL added. |
Finally start it with (you can also use ‘view report ext01’ to get more detailed informations):
GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 22> start ext01 Sending START request to MANAGER ... EXTRACT EXT01 starting GGSCI (server01 as c##ggadmin@orcl/CDB$ROOT) 23> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING EXTRACT RUNNING EXT01 00:00:00 19:13:08 |
Test it works by inserting a row in your test table:
SQL> INSERT INTO test01 VALUES(10,'Ten'); 1 ROW created. SQL> COMMIT; COMMIT complete. |
And checking you trail files get created in chosen directory:
[oracle@server01 oggcore_1]$ ll dirdat total 2 -rw-r----- 1 oracle dba 1294 Jan 22 11:24 ex000000000 |
GoldenGate for Big Data and Kafka Handler configuration
One cool directory to look at is AdapterExamples directory located inside you GoldenGate for Big Data installation and in my case AdapterExamples/big-data/kafka* sub directories:
[oracle@server01 big-data]$ pwd /u01/app/oracle/product/19.1.0/oggbigdata_1/AdapterExamples/big-data [oracle@server01 big-data]$ ll -d kafka* drwxr-x--- 2 oracle dba 96 Sep 25 2019 kafka drwxr-x--- 2 oracle dba 96 Sep 25 2019 kafka_connect drwxr-x--- 2 oracle dba 96 Sep 25 2019 kafka_REST_proxy [oracle@server01 big-data]$ ll kafka total 4 -rw-r----- 1 oracle dba 261 Sep 3 2019 custom_kafka_producer.properties -rw-r----- 1 oracle dba 1082 Sep 25 2019 kafka.props -rw-r----- 1 oracle dba 332 Sep 3 2019 rkafka.prm |
So in kafka directory we have three files that you can copy to dirprm directory of your GoldenGate for Big Data installation. Now you must customize them to match your configuration.
In custom_kafka_producer.properties I have just changed bootstrap.servers variable to match my Kafka server:
bootstrap.servers=localhost:9092 acks=1 reconnect.backoff.ms=1000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer # 100KB per partition batch.size=16384 linger.ms=0 |
In kafka.props I have changed gg.classpath to an extract of a Kafka installation directory (this directory must be owned or readable by oracle account). It means that if Kafka is installed on another server (normal configuration) you must copy the libs to your GoldenGate for Big Data server. The chosen example payload format is avro_op (Avro in operation more verbose format). Can be one of these: xml, delimitedtext, json, json_row, avro_row, avro_op:
gg.handlerlist = kafkahandler gg.handler.kafkahandler.type=kafka gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties #The following resolves the topic name using the short table name gg.handler.kafkahandler.topicMappingTemplate=${tableName} #The following selects the message key using the concatenated primary keys gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys} gg.handler.kafkahandler.format=avro_op gg.handler.kafkahandler.SchemaTopicName=mySchemaTopic gg.handler.kafkahandler.BlockingSend =false gg.handler.kafkahandler.includeTokens=false gg.handler.kafkahandler.mode=op gg.handler.kafkahandler.MetaHeaderTemplate=${alltokens} goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec #Sample gg.classpath for Apache Kafka gg.classpath=dirprm/:/u01/kafka_2.13-2.7.0/libs/* #Sample gg.classpath for HDP #gg.classpath=/etc/kafka/conf:/usr/hdp/current/kafka-broker/libs/* javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar |
In rkafka.prm I have changed MAP | TARGET parameter:
REPLICAT rkafka -- Trail file for this example is located in "AdapterExamples/trail" directory -- Command to add REPLICAT -- add replicat rkafka, exttrail AdapterExamples/trail/tr TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP pdb1.appuser.*, TARGET appuser.*; |
As explained in rkafka.prm file I add replicat process (dump) and trail directory (it must be the one of your legacy GoldenGate installation):
GGSCI (server01) 1> add replicat rkafka, exttrail /u01/app/oracle/product/19.1.0/oggcore_1/dirdat/ex REPLICAT added. GGSCI (server01) 2> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT STOPPED RKAFKA 00:00:00 00:00:03 GGSCI (server01) 3> start rkafka Sending START request to MANAGER ... REPLICAT RKAFKA starting GGSCI (server01) 4> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT RUNNING RKAFKA 00:00:00 00:12:08 |
As a test I insert a row in my test table:
SQL> INSERT INTO test01 VALUES(1,'One'); 1 ROW created. SQL> COMMIT; COMMIT complete. |
I can read the event on the topic that has my table name (the first event is the test I have done when I configured GoldenGate):
[kafka@server01 kafka_2.13-2.7.0]$ bin/kafka-topics.sh --list --zookeeper localhost:2181 TEST01 __consumer_offsets mySchemaTopic quickstart-events [kafka@server01 kafka_2.13-2.7.0]$ bin/kafka-console-consumer.sh --topic TEST01 --from-beginning --bootstrap-server localhost:9092 APPUSER.TEST01I42021-01-22 11:32:20.00000042021-01-22T15:20:51.081000(00000000000000001729ID$@Ten APPUSER.TEST01I42021-01-22 15:24:55.00000042021-01-22T15:25:00.665000(00000000000000001872ID▒?One |
You can clean the installation with:
stop rkafka delete replicat rkafka |
GoldenGate for Big Data and Kafka Connect Handler configuration
Same as previous chapter I copy the demo configuration files with:
[oracle@server01 kafka_connect]$ pwd /u01/app/oracle/product/19.1.0/oggbigdata_1/AdapterExamples/big-data/kafka_connect [oracle@server01 kafka_connect]$ ll total 4 -rw-r----- 1 oracle dba 592 Sep 3 2019 kafkaconnect.properties -rw-r----- 1 oracle dba 337 Sep 3 2019 kc.prm -rw-r----- 1 oracle dba 1733 Sep 25 2019 kc.props [oracle@server01 kafka_connect]$ cp * ../../../dirprm/ |
As I’m using the same server for all component kafkaconnect.properties file is already correct. I have just added converter.type to correct a bug. We see that here the example is configured to use JSON for payload:
bootstrap.servers=localhost:9092 acks=1 #JSON Converter Settings key.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter=org.apache.kafka.connect.json.JsonConverter value.converter.schemas.enable=true #Avro Converter Settings #key.converter=io.confluent.connect.avro.AvroConverter #value.converter=io.confluent.connect.avro.AvroConverter #key.converter.schema.registry.url=http://localhost:8081 #value.converter.schema.registry.url=http://localhost:8081 #Adjust for performance buffer.memory=33554432 batch.size=16384 linger.ms=0 converter.type=key converter.type=value converter.type=header |
In kc.props file I only change gg.classpath parameter with exact same comment as Kafka Handler configuration:
gg.handlerlist=kafkaconnect #The handler properties gg.handler.kafkaconnect.type=kafkaconnect gg.handler.kafkaconnect.kafkaProducerConfigFile=kafkaconnect.properties gg.handler.kafkaconnect.mode=op #The following selects the topic name based on the fully qualified table name gg.handler.kafkaconnect.topicMappingTemplate=${fullyQualifiedTableName} #The following selects the message key using the concatenated primary keys gg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys} gg.handler.kafkahandler.MetaHeaderTemplate=${alltokens} #The formatter properties gg.handler.kafkaconnect.messageFormatting=row gg.handler.kafkaconnect.insertOpKey=I gg.handler.kafkaconnect.updateOpKey=U gg.handler.kafkaconnect.deleteOpKey=D gg.handler.kafkaconnect.truncateOpKey=T gg.handler.kafkaconnect.treatAllColumnsAsStrings=false gg.handler.kafkaconnect.iso8601Format=false gg.handler.kafkaconnect.pkUpdateHandling=abend gg.handler.kafkaconnect.includeTableName=true gg.handler.kafkaconnect.includeOpType=true gg.handler.kafkaconnect.includeOpTimestamp=true gg.handler.kafkaconnect.includeCurrentTimestamp=true gg.handler.kafkaconnect.includePosition=true gg.handler.kafkaconnect.includePrimaryKeys=false gg.handler.kafkaconnect.includeTokens=false goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec #Apache Kafka Classpath gg.classpath=/u01/kafka_2.13-2.7.0/libs/* #Confluent IO classpath #gg.classpath={Confluent install dir}/share/java/kafka-serde-tools/*:{Confluent install dir}/share/java/kafka/*:{Confluent install dir}/share/java/confluent-common/* javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.:ggjava/ggjava.jar:./dirprm |
In kc.prm file I only change the MAP | TARGET configuration as follow:
REPLICAT kc -- Trail file for this example is located in "AdapterExamples/trail" directory -- Command to add REPLICAT -- add replicat conf, exttrail AdapterExamples/trail/tr NODBCHECKPOINT TARGETDB LIBFILE libggjava.so SET property=dirprm/kc.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 1000 MAP pdb1.appuser.*, TARGET appuser.*; |
Add the Kafka Connect Handler replicat with:
GGSCI (server01) 1> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING GGSCI (server01) 2> add replicat kc, exttrail /u01/app/oracle/product/19.1.0/oggcore_1/dirdat/ex REPLICAT added. GGSCI (server01) 3> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT STOPPED KC 00:00:00 00:00:05 GGSCI (server01) 3> start kc Sending START request to MANAGER ... REPLICAT KC starting GGSCI (server01) 4> info all Program Status Group Lag at Chkpt Time Since Chkpt MANAGER RUNNING REPLICAT RUNNING KC 00:00:00 00:00:04 |
Add a new row in the test table (and commit):
SQL> CONNECT appuser/secure_password@pdb1 Connected. SQL> SELECT * FROM test01; ID DESCR ---------- -------------------------------------------------- 10 Ten 1 One SQL> INSERT INTO test01 VALUES(2,'Two'); 1 ROW created. SQL> COMMIT; COMMIT complete. |
Reading the new topic you should see new lines coming:
[kafka@server01 kafka_2.13-2.7.0]$ bin/kafka-topics.sh --list --zookeeper localhost:2181 APPUSER.TEST01 TEST01 __consumer_offsets mySchemaTopic quickstart-events [kafka@server01 kafka_2.13-2.7.0]$ bin/kafka-console-consumer.sh --topic APPUSER.TEST01 --from-beginning --bootstrap-server localhost:9092 {"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"table"},{"type":"string","optional":true,"field":"op_type"},{"type":"string","optional":true,"field":"op_ts"},{"type":"string","optional":true,"field":"current_ts"},{"type":"string","optional":true,"field":"pos"},{"type":"double","optional":true,"field":"ID"},{"type":"string","optional":true,"field":"DESCR"}],"optional":false,"name":"APPUSER.TEST01"},"payload":{"table":"APPUSER.TEST01","op_type":"I","op_ts":"2021-01-22 11:32:20.000000","current_ts":"2021-01-22 17:36:00.285000","pos":"00000000000000001729","ID":10.0,"DESCR":"Ten"}} {"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"table"},{"type":"string","optional":true,"field":"op_type"},{"type":"string","optional":true,"field":"op_ts"},{"type":"string","optional":true,"field":"current_ts"},{"type":"string","optional":true,"field":"pos"},{"type":"double","optional":true,"field":"ID"},{"type":"string","optional":true,"field":"DESCR"}],"optional":false,"name":"APPUSER.TEST01"},"payload":{"table":"APPUSER.TEST01","op_type":"I","op_ts":"2021-01-22 15:24:55.000000","current_ts":"2021-01-22 17:36:00.727000","pos":"00000000000000001872","ID":1.0,"DESCR":"One"}} {"schema":{"type":"struct","fields":[{"type":"string","optional":true,"field":"table"},{"type":"string","optional":true,"field":"op_type"},{"type":"string","optional":true,"field":"op_ts"},{"type":"string","optional":true,"field":"current_ts"},{"type":"string","optional":true,"field":"pos"},{"type":"double","optional":true,"field":"ID"},{"type":"string","optional":true,"field":"DESCR"}],"optional":false,"name":"APPUSER.TEST01"},"payload":{"table":"APPUSER.TEST01","op_type":"I","op_ts":"2021-01-22 17:38:23.000000","current_ts":"2021-01-22 17:38:27.800000","pos":"00000000000000002013","ID":2.0,"DESCR":"Two"}} |
References
- Comparing GoldenGate Kafka Handlers
- Oracle GoldenGate Big Data Adapter: Apache Kafka Producer
- Troubleshooting Oracle GoldenGate for Big Data Kafka Handler (Doc ID 2519451.1)
- Welcome to All Things Data Integration: Announcements, Insights, Best Practices, Tips & Tricks, and Trend Related…
- Difference between the OGGBD Kafka Handler and Kafka Connect Handler (Doc ID 2314366.1)
- Oracle GoldenGate Adapter for Confluent Platform, powered by Apache Kafka
- OGG Big Data Replicat Using Kafka Connect Handler Fails With “Missing required configuration “converter.type” which has no default value” (Doc ID 2455697.1)



 installation and usage")


Amin says:
Hi
Many thanks for your great effort , I learned for it and also I need to add that newer version no longer require ZooKeeper connection
[kafka@server01 kafka_2.13-3.1.0]$ bin/kafka-topics.sh –list –bootstrap-server localhost:9092
TEST01
__consumer_offsets
mySchemaTopic
[oracle@oam kafka_2.13-3.1.0]$
Thanks
Yannick Jaquier says:
Hi,
Thanks for comment and your sharing !