Table of contents
Preamble
Developing directly on an Hadoop cluster is not the best development environment you would dream for yourself. Of course it makes easy the testing of your code as you can instantly submit it but in worst case your editor will be vi. Obviously what new generation developers want is a clever editor running on their Windows (Linux ?) desktop. By clever editor I mean one having syntax completion, suggesting to import packages when using a procedures, suggesting unused variables if any and so on… Small teasing: Intellij IDEA from JetBrains is a serious contenders nowadays, apparently much better than Eclipse that is more or less dying…
We, at last, improved a bit the editor part by installing VSCode and editing our file with SSH FS plugins. In clear we edit through SSH files located directly on the server and then using a shell terminal (MobaXterm , Putty, …) we are able to submit scripts directly onto our Hadoop cluster. This works if you do Python (even if a PySpark plugin is not available in VSCode) but if you do Scala you also have to run an sbt command, each time, to compile you Scala program. A bit cumbersome…
As said above Intellij IDEA from JetBrains is a very good Scala language editor and the community edition does a pretty decent job. But then difficulties rise as this software lack a remote SSH edition… So it works well for pure Scala script but if you need to access you Hive table you have to work a bit to configure it…
This blog post is all about this: building a productive Scala/PySpark development environment on your Windows desktop and access Hive tables of an Hadoop cluster.
Spark installation and configuration
Before going in small details I have first tried to make raw Spark installation working on my Windows machine. I have started by downloading it on official web site:
And unzip it in default D:\spark-2.4.4-bin-hadoop2.7 directory. You must set SPARK_HOME environment variable to the directory you have unzip Spark. For convenience you also need to add D:\spark-2.4.4-bin-hadoop2.7\bin in the path of your Windows account (restart PowerShell after) and confirm it’s all good with:
$env:path |
Then issue spark-shell in a PowerShell session, you should get a warning like:
19/11/15 17:15:37 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:387) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80) at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:273) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:261) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:791) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:761) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:634) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2422) at org.apache.spark.SecurityManager.<init>(SecurityManager.scala:79) at org.apache.spark.deploy.SparkSubmit.secMgr$lzycompute$1(SparkSubmit.scala:348) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$secMgr$1(SparkSubmit.scala:348) at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:356) at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:356) at scala.Option.map(Option.scala:146) at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:355) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:774) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) |
Take winutils.exe that is Windows binary for Hadoop version at: https://github.com/steveloughran/winutils and put it in D:\spark-2.4.4-bin-hadoop2.7\bin folder.
I have downloaded the one for Hadoop 2.7.1 (linked to my Hadoop cluster). You must also set environment variable HADOOP_HOME to D:\spark-2.4.4-bin-hadoop2.7. Then scala-shell command should execute with no error. You can make the suggested testing right now:
PS D:\> spark-shell 19/11/15 17:29:20 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://client_machine.domain.com:4040 Spark context available as 'sc' (master = local[*], app id = local-1573835367367). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_231) Type in expressions to have them evaluated. Type :help for more information. scala> spark res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@28532753 scala> sc res1: org.apache.spark.SparkContext = org.apache.spark.SparkContext@44846c76 |
scala> val textFile = spark.read.textFile("D:/spark-2.4.4-bin-hadoop2.7/README.md") textFile: org.apache.spark.sql.Dataset[String] = [value: string] scala> textFile.count() res2: Long = 105 scala> textFile.filter(line => line.contains("Spark")).count() res3: Long = 20 |
And that’s it you have a local running working Spark environment with all the Spark clients: Spark shell, PySpark, Spark SQL, SparkR… I had to install Python 3.7.5 as it was not working with Python 3.8.0, might be corrected soon:
PS D:\> pyspark Python 3.7.5 (tags/v3.7.5:5c02a39a0b, Oct 15 2019, 00:11:34) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. 19/11/15 17:28:09 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Python version 3.7.5 (tags/v3.7.5:5c02a39a0b, Oct 15 2019 00:11:34) SparkSession available as 'spark'. >>> textFile = spark.read.text("D:/spark-2.4.4-bin-hadoop2.7/README.md") >>> textFile.count() 105 |
To access Hive running on my cluster I have taken the file called hive-site.xml in /etc/spark2/conf directory of one of my edge node where Spark was installed and put it in D:\spark-2.4.4-bin-hadoop2.7\conf folder. And it worked pretty well:
scala> val databases=spark.sql("show databases") databases: org.apache.spark.sql.DataFrame = [databaseName: string] scala> databases.show(10,false) +------------------+ |databaseName | +------------------+ |activity | |admin | |alexandre_c300 | |audit | |big_ews_processing| |big_ews_raw | |big_ews_refined | |big_fdc_processing| |big_fdc_raw | |big_fdc_refined | +------------------+ only showing top 10 rows |
But it failed for a more complex example:
scala> val df01=spark.sql("select * from admin.tbl_concatenate") df01: org.apache.spark.sql.DataFrame = [id_process: string, date_job_start: string ... 9 more fields] scala> df01.printSchema() root |-- id_process: string (nullable = true) |-- date_job_start: string (nullable = true) |-- date_job_stop: string (nullable = true) |-- action: string (nullable = true) |-- database_name: string (nullable = true) |-- table_name: string (nullable = true) |-- partition_name: string (nullable = true) |-- number_files_before: string (nullable = true) |-- partition_size_before: string (nullable = true) |-- number_files_after: string (nullable = true) |-- partition_size_after: string (nullable = true) scala> df01.show(10,false) java.lang.IllegalArgumentException: java.net.UnknownHostException: DataLakeHdfs at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:378) at org.apache.hadoop.hdfs.NameNodeProxies.createNonHAProxy(NameNodeProxies.java:310) at org.apache.hadoop.hdfs.NameNodeProxies.createProxy(NameNodeProxies.java:176) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:678) at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:619) |
To solve this I have to copy hdfs-site.xml from /etc/hadoop/conf directory of one of my edge where HDFS Client has been installed and it worked much better:
scala> val df01=spark.sql("select * from admin.tbl_concatenate") df01: org.apache.spark.sql.DataFrame = [id_process: string, date_job_start: string ... 9 more fields] scala> df01.show(10,false) 19/11/15 17:45:01 WARN DomainSocketFactory: The short-circuit local reads feature cannot be used because UNIX Domain sockets are not available on Windows. +----------+--------------+--------------+----------+----------------+------------------+----------------------------+-------------------+---------------------+------------------+--------------------+ |id_process|date_job_start|date_job_stop |action |database_name |table_name |partition_name |number_files_before|partition_size_before|number_files_after|partition_size_after| +----------+--------------+--------------+----------+----------------+------------------+----------------------------+-------------------+---------------------+------------------+--------------------+ |10468 |20190830103323|20190830103439|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q1111|3 |1606889 |3 |1606889 | |10468 |20190830103859|20190830104224|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7180|7 |37136990 |2 |37130614 | |10468 |20190830104251|20190830104401|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7210|4 |22095872 |3 |22094910 | |10468 |20190830104435|20190830104624|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7250|4 |73357246 |2 |73352589 | |10468 |20190830104659|20190830104759|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7280|1 |1696312 |1 |1696312 | |10468 |20190830104845|20190830104952|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7350|3 |3439184 |3 |3439184 | |10468 |20190830105023|20190830105500|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7371|6 |62283893 |2 |62274587 | |10468 |20190830105532|20190830105718|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q7382|5 |25501396 |3 |25497826 | |10468 |20190830110118|20190830110316|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q8030|3 |74338924 |3 |74338924 | |10468 |20190830110413|20190830110520|compaction|prod_ews_refined|tbl_bin_param_stat|fab=C2WF/lot_partition=Q8039|3 |5336123 |2 |5335855 | +----------+--------------+--------------+----------+----------------+------------------+----------------------------+-------------------+---------------------+------------------+--------------------+ only showing top 10 rows |
And that’s it you have built a working local Spark environment able to access your Hadoop cluster figures. Of course your Spark power is limited to your client machine and you cannot use the full power of your cluster but to develop scripts this is more than enough…
Sbt installation and configuration
If you write Scala script the next step to submit them using spark-submit and leave the interactive mode will be to compile them and produce a jar file usable by spark-submit. I have to say this is a drawback versus developing in Python where your PySpark script will be directly usable as-is with this language. The speed is also apparently not a criteria as PySpark has same performance as Scala. The only reason to do Scala, except being hype, is the functionalities that are more in advance in Scala versus Python…
The installation is as simple as downloading it on sbt official web site. I have chosen to take the zip file and uncompressed it in d:\sbt directory. For convenience add d:\sbt\bin in your environment path. I have configured my corporate proxy in sbtconfig.txt file located in d:\sbt\conf as follow:
-Dhttp.proxyHost=proxy.domain.com
-Dhttp.proxyPort=8080
-Dhttp.proxyUser=account
-Dhttp.proxyPassword=password |
PS D:\> mkdir foo-build Directory: D:\ Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 18/11/2019 12:07 foo-build PS D:\> cd .\foo-build\ PS D:\foo-build> ni build.sbt Directory: D:\foo-build Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 18/11/2019 12:08 0 build.sbt |
PS D:\foo-build> sbt [info] Updated file D:\foo-build\project\build.properties: set sbt.version to 1.3.3 [info] Loading project definition from D:\foo-build\project nov. 18, 2019 12:08:39 PM lmcoursier.internal.shaded.coursier.cache.shaded.org.jline.utils.Log logr WARNING: Unable to create a system terminal, creating a dumb terminal (enable debug logging for more information) [info] Updating | => foo-build-build / update 0s [info] Resolved dependencies [warn] [warn] Note: Unresolved dependencies path: [error] sbt.librarymanagement.ResolveException: Error downloading org.scala-sbt:sbt:1.3.3 [error] Not found [error] Not found [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading https://repo1.maven.org/maven2/org/scala-sbt/sbt/1.3.3/sbt-1.3.3.pom [error] not found: C:\Users\yjaquier\.ivy2\local\org.scala-sbt\sbt\1.3.3\ivys\ivy.xml [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] Error downloading org.scala-lang:scala-library:2.12.10 [error] Not found [error] Not found [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading https://repo1.maven.org/maven2/org/scala-lang/scala-library/2.12.10/scala-library-2.12.10.pom [error] not found: C:\Users\yjaquier\.ivy2\local\org.scala-lang\scala-library\2.12.10\ivys\ivy.xml [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] at lmcoursier.CoursierDependencyResolution.unresolvedWarningOrThrow(CoursierDependencyResolution.scala:245) [error] at lmcoursier.CoursierDependencyResolution.$anonfun$update$34(CoursierDependencyResolution.scala:214) [error] at scala.util.Either$LeftProjection.map(Either.scala:573) [error] at lmcoursier.CoursierDependencyResolution.update(CoursierDependencyResolution.scala:214) [error] at sbt.librarymanagement.DependencyResolution.update(DependencyResolution.scala:60) [error] at sbt.internal.LibraryManagement$.resolve$1(LibraryManagement.scala:52) [error] at sbt.internal.LibraryManagement$.$anonfun$cachedUpdate$12(LibraryManagement.scala:102) [error] at sbt.util.Tracked$.$anonfun$lastOutput$1(Tracked.scala:69) [error] at sbt.internal.LibraryManagement$.$anonfun$cachedUpdate$20(LibraryManagement.scala:115) [error] at scala.util.control.Exception$Catch.apply(Exception.scala:228) [error] at sbt.internal.LibraryManagement$.$anonfun$cachedUpdate$11(LibraryManagement.scala:115) [error] at sbt.internal.LibraryManagement$.$anonfun$cachedUpdate$11$adapted(LibraryManagement.scala:96) [error] at sbt.util.Tracked$.$anonfun$inputChanged$1(Tracked.scala:150) [error] at sbt.internal.LibraryManagement$.cachedUpdate(LibraryManagement.scala:129) [error] at sbt.Classpaths$.$anonfun$updateTask0$5(Defaults.scala:2946) [error] at scala.Function1.$anonfun$compose$1(Function1.scala:49) [error] at sbt.internal.util.$tilde$greater.$anonfun$$u2219$1(TypeFunctions.scala:62) [error] at sbt.std.Transform$$anon$4.work(Transform.scala:67) [error] at sbt.Execute.$anonfun$submit$2(Execute.scala:281) [error] at sbt.internal.util.ErrorHandling$.wideConvert(ErrorHandling.scala:19) [error] at sbt.Execute.work(Execute.scala:290) [error] at sbt.Execute.$anonfun$submit$1(Execute.scala:281) [error] at sbt.ConcurrentRestrictions$$anon$4.$anonfun$submitValid$1(ConcurrentRestrictions.scala:178) [error] at sbt.CompletionService$$anon$2.call(CompletionService.scala:37) [error] at java.util.concurrent.FutureTask.run(Unknown Source) [error] at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) [error] at java.util.concurrent.FutureTask.run(Unknown Source) [error] at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) [error] at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) [error] at java.lang.Thread.run(Unknown Source) [error] (update) sbt.librarymanagement.ResolveException: Error downloading org.scala-sbt:sbt:1.3.3 [error] Not found [error] Not found [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading https://repo1.maven.org/maven2/org/scala-sbt/sbt/1.3.3/sbt-1.3.3.pom [error] not found: C:\Users\yjaquier\.ivy2\local\org.scala-sbt\sbt\1.3.3\ivys\ivy.xml [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] Error downloading org.scala-lang:scala-library:2.12.10 [error] Not found [error] Not found [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading https://repo1.maven.org/maven2/org/scala-lang/scala-library/2.12.10/scala-library-2.12.10.pom [error] not found: C:\Users\yjaquier\.ivy2\local\org.scala-lang\scala-library\2.12.10\ivys\ivy.xml [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading [error] download error: Caught java.io.IOException: Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required" (Unable to tunnel through proxy. Proxy returns "HTTP/1.1 407 Proxy Authentication Required") while downloading Project loading failed: (r)etry, (q)uit, (l)ast, or (i)gnore? q |
For file D:\foo-build\project\build.properties I had to change as follow as apparently there is an issue with sbt 1.3.3 repository:
sbt.version=1.2.8 |
This time it went well:
PS D:\foo-build> sbt [info] Loading project definition from D:\foo-build\project [info] Updating ProjectRef(uri("file:/D:/foo-build/project/"), "foo-build-build")... [info] Done updating. [info] Loading settings for project foo-build from build.sbt ... [info] Set current project to foo-build (in build file:/D:/foo-build/) [info] sbt server started at local:sbt-server-2b55615bd8de0c5ac354 sbt:foo-build> |
As suggested in sbt official documentation I have issued:
sbt:foo-build> ~compile [info] Updating ... [info] Done updating. [info] Compiling 1 Scala source to D:\foo-build\target\scala-2.12\classes ... [info] Done compiling. [success] Total time: 1 s, completed 18 nov. 2019 12:58:30 1. Waiting for source changes in project foo-build... (press enter to interrupt) |
And create the Hello.scala file where suggested that is instantly compiled:
[info] Compiling 1 Scala source to D:\foo-build\target\scala-2.12\classes ... [info] Done compiling. [success] Total time: 1 s, completed 18 nov. 2019 12:58:51 2. Waiting for source changes in project foo-build... (press enter to interrupt) |
You can run it using:
sbt:foo-build> run [info] Running example.Hello Hello [success] Total time: 1 s, completed 18 nov. 2019 13:06:23 |
Create a jar file that can be submitted via spark-submit with:
sbt:foo-build> package [info] Packaging D:\foo-build\target\scala-2.12\foo-build_2.12-0.1.0-SNAPSHOT.jar ... [info] Done packaging. [success] Total time: 0 s, completed 18 nov. 2019 16:15:06 |
Intellij IDEA from JetBrains
Java JDK is a prerequisite, I have personally installed release 1.8.0_231.
Once you have installed Intellij IDEA, the community edition does the job for basics things, the first thing you have to do is to install the Scala plugin (you will have to configure your corporate proxy):
Then create your first Scala project with Create New Project:
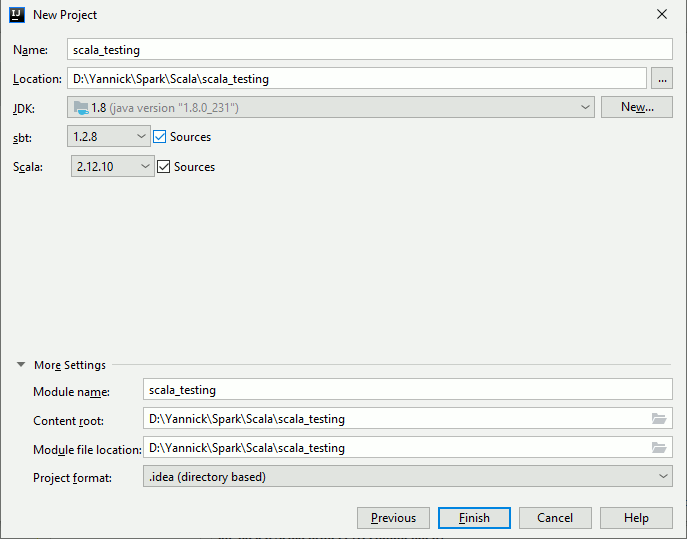
I have chosen Sbt 1.2.8 and Scala 2.12.10 as I had many issues with latest versions:
In src/main/scala folder create a new Scala Class (mouse left button click then New/Scala Class) and then select Object to create (for example) a file called scala_testing.scala. As an example:
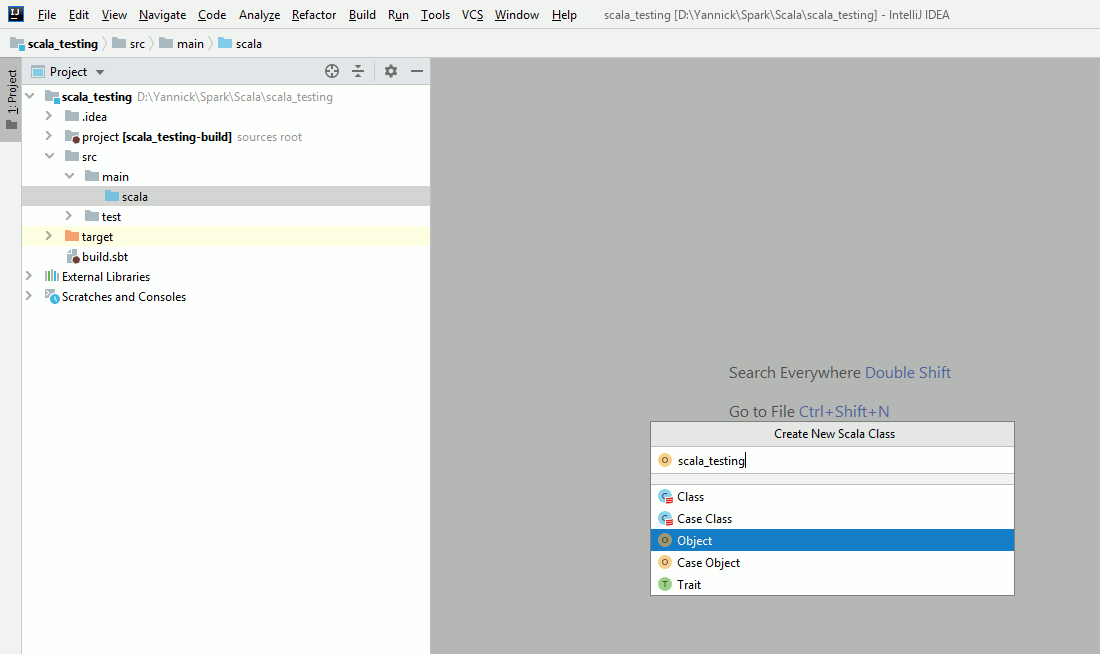
Insert (for example) below Scala code in Scala object script you have just created:
import org.apache.spark.sql.SparkSession
object scala_testing {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("spark_scala_yannick")
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
val databases=spark.sql("show databases")
databases.show(100,false)
}
}
In build.sbt file add the following dependencies to have a file looking like:
name := "scala_testing" version := "0.1" scalaVersion := "2.12.10" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.4" libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.4" libraryDependencies += "org.apache.spark" %% "spark-hive" % "2.4.4" |
Sbt proxy setting are not inherited (feature has been requested) from Intellij default proxy setting so you have to add the below VM parameters:
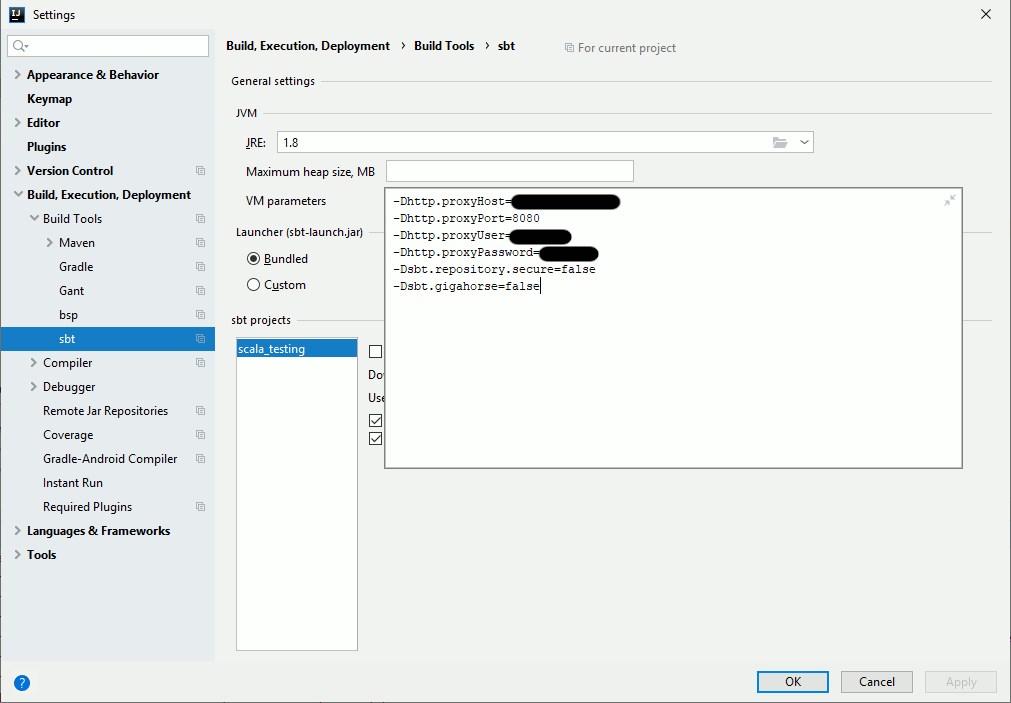
Remark:
-Dsbt.repository.secure=false is surely not the best idea of the world but I had issue configuring my proxy server in https. -Dsbt.gigahorse=false is to overcome a concurrency issue while downloading multiple packages at same time… Might not be required for you…
Once the build process is completed (dependencies download) if you execute the script you will end up with:
+------------+ |databaseName| +------------+ |default | +------------+ |
We are still lacking the Hive configuration. To add it go in File/Project Structure and a new Java library
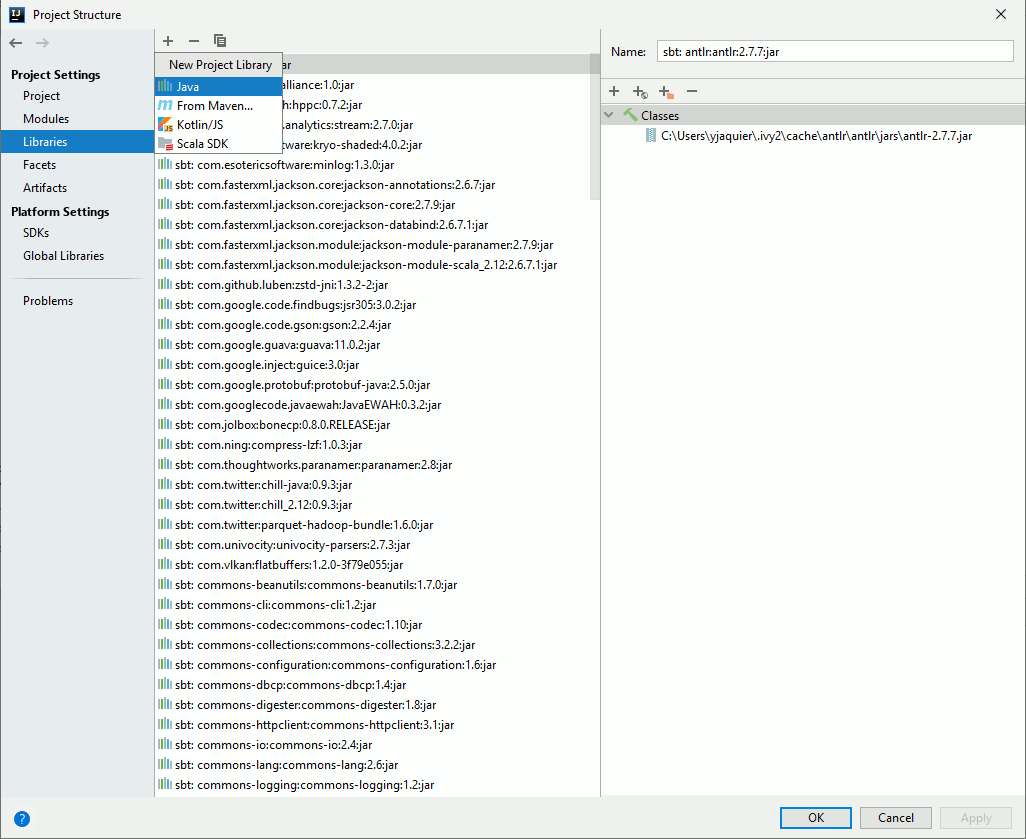
Browse to the Spark conf directory we configured in Spark installation and configuration chapter:
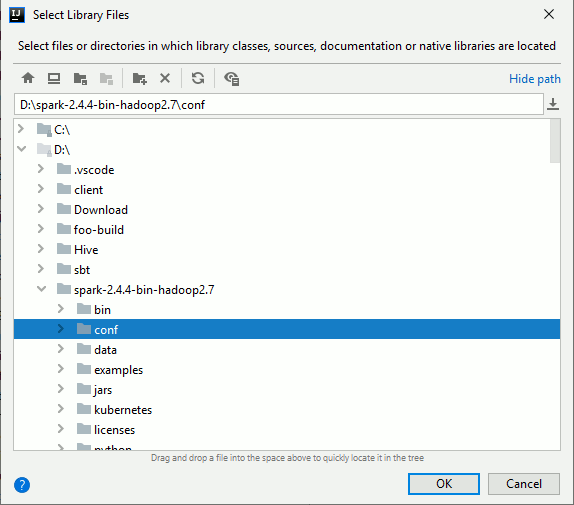
Choose Class as category:
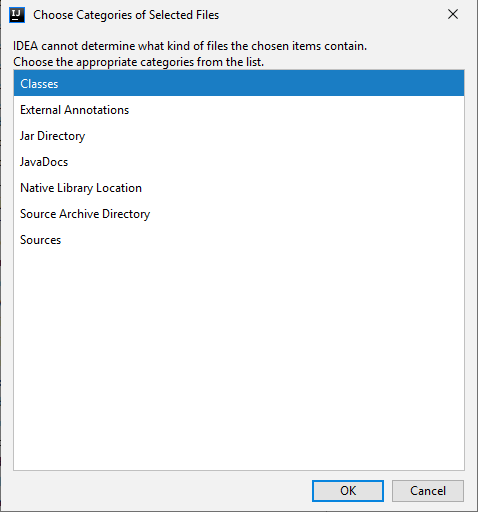
I have finally selected all modules (not fully sure it’s required):
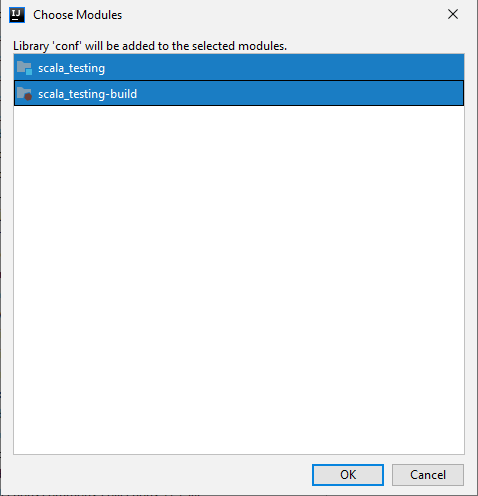
If you now re-execute the Sacala script you should now get the complete list of Hive databases of your Hadoop cluster:
+--------------------------+ |databaseName | +--------------------------+ |activity | |admin | |audit | |big_processing | |big_raw | |big_refined | |big_processing | . . |
Conclusion
I have also tried to submit directly from Intellij in YARN mode (so onto the Hadoop cluster) but even if I have been able to see my application in Resource Manager of YARN I have never succeeded to make it run normally. The YARN scheduler is taking my request but never satisfy it…
Any inputs are welcome…






Somu says:
Wonderful presentation, i can now connect to my hive cluster from Intellij on windows. But still have a problem sir, actually we connect to hive by logging in as a unix user [lh007923] and then switching to a sudo user [ sudo su runteam ], now only this sudo user has permissions to execute hadoop commands , login to hive etc, so the problem is, even though i connected to hive from my windows spark shell, because it says permission denied to user id [ windows user name ], so please help me to connect with my unix user id with the sudo user please
Yannick Jaquier says:
Thanks for comment…
We have upgraded to HDP 3 so I can share the dummy code I have written using Hive Warehouse Connector:
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark_llap import HiveWarehouseSession
spark = SparkSession.builder.appName("Python Spark SQL Hive warehouse connector ").getOrCreate()
sess = HiveWarehouseSession.session(spark)
sess.userPassword("account", "password")
hive = sess.build()
hive.setDatabase("mydb")
df = hive.executeQuery("select count(*) from table1")
df.show()
Hope it helps…