Since we have started to put Spark job in production we asked ourselves the question of how many executors, number of cores per executor and executor memory we should put. What if we put too much and are wasting resources and could we improve the response time if we put more ?
In other words those spark-submit parameters (we have an Hortonworks Hadoop cluster and so are using YARN):
–executor-memory MEM – Memory per executor (e.g. 1000M, 2G) (Default: 1G).
–executor-cores NUM – Number of cores per executor. (Default: 1 in YARN mode, or all available cores on the worker in standalone mode)
–num-executors NUM – Number of executors to launch (Default: 2). If dynamic allocation is enabled, the initial number of executors will be at least NUM.
And in fact it is written in above description of num-executors Spark dynamic allocation is partially answering to the former question.
Spark dynamic allocation is a feature allowing your Spark application to automatically scale up and down the number of executors. And only the number of executors not the memory size and not the number of cores of each executor that must still be set specifically in your application or when executing spark-submit command. So the promise is your application will dynamically be able to request more executors and release them back to cluster pool based on your application workload. Of course if using YARN you will be tightly linked to the ressource allocated to the queue to which you have submitted your application (–queue parameter of spark-submit).
This blog post has been written using Hortonworks Data Platform (HDP) 3.1.4 and so Spark2 2.3.2.
Spark dynamic allocation setup
As it is written in official documentation the shuffle jar must be added to the classpath of all NodeManagers. If like me you are running HDP 3 I have discovered that everything was already configured. The jar of this external shuffle library is:
[root@server jars]# ll /usr/hdp/current/spark2-client/jars/*shuffle*-rw-r--r--1 root root 67763 Aug 232019/usr/hdp/current/spark2-client/jars/spark-network-shuffle_2.11-2.3.2.3.1.4.0-315.jar
And in Ambari the YARN configuration was also already done:
spark_dynamic_allocation01
Remark: We still have old Spark 1 variables and you should now concentrate only on the spark2_xx variables. Same this is spark2_shuffle that must be appended to yarn.nodemanager.aux-services.
Then again quoting official documentation you have two parameters to set inside your application to have the feature activated:
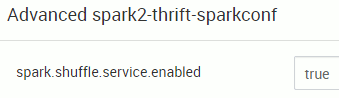
There are two requirements for using this feature. First, your application must set spark.dynamicAllocation.enabled to true. Second, you must set up an external shuffle service on each worker node in the same cluster and set spark.shuffle.service.enabled to true in your application.
This part was not obvious to me but as it is written spark.dynamicAllocation.enabled and spark.shuffle.service.enabled must not only be set at cluster level but also in your application or as a spark-submit parameter ! I would even say that setting those parameters in Ambari makes no difference but as you can see below all was done by default in my HDP 3.1.4 cluster:
For the testing code I have done a mix in PySpark of multiple test code I have seen around on Internet. Using Python is avoiding me a boring sbt compilation phase before testing…
The source code is (spark_dynamic_allocation.py):
# from pyspark.sql import SparkSession
from pyspark import SparkConf
from pyspark import SparkContext
# from pyspark_llap import HiveWarehouseSession
from time import sleep
def wait_x_seconds(x):
sleep(x*10)
conf = SparkConf().setAppName("Spark dynamic allocation").\
set("spark.dynamicAllocation.enabled", "true").\
set("spark.shuffle.service.enabled", "true").\
set("spark.dynamicAllocation.initialExecutors", "1").\
set("spark.dynamicAllocation.executorIdleTimeout", "5s").\
set("spark.executor.cores", "1").\
set("spark.executor.memory", "512m")
sc = SparkContext.getOrCreate(conf)
# spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
# spark.stop()
sc.parallelize(range(1,6), 5).foreach(wait_x_seconds)exit()
# from pyspark.sql import SparkSession
from pyspark import SparkConf
from pyspark import SparkContext
# from pyspark_llap import HiveWarehouseSession
from time import sleepdef wait_x_seconds(x):
sleep(x*10)conf = SparkConf().setAppName("Spark dynamic allocation").\
set("spark.dynamicAllocation.enabled", "true").\
set("spark.shuffle.service.enabled", "true").\
set("spark.dynamicAllocation.initialExecutors", "1").\
set("spark.dynamicAllocation.executorIdleTimeout", "5s").\
set("spark.executor.cores", "1").\
set("spark.executor.memory", "512m")sc = SparkContext.getOrCreate(conf)# spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
# spark.stop()sc.parallelize(range(1,6), 5).foreach(wait_x_seconds)exit()
So in short I run five parallel processes that will each wait x*10 seconds when x is from 1 to 5 (range(1,6)). We will start with one executor and expect Spark to scale up and then down as the shorter timers will end in order (10 seconds, 20 seconds, ..). I have also exaggerated a bit in parameters as spark.dynamicAllocation.executorIdleTimeout is changed to 5s that I see in my example the executors being killed (default is 60s).
The command to execute it is, Hive Warehouse Connector not really mandatory here but it became an habit. Notice that I do not specify anything in command line as all will be setup in Python script:
By default our spark-submit is in INFO mode, and the important part of the output is:
.
20/04/09 14:34:14 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
20/04/09 14:34:16 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor)(10.75.37.249:36332) with ID 120/04/09 14:34:16 INFO ExecutorAllocationManager: New executor 1 has registered (new total is 1)
.
.
20/04/09 14:34:17 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2)20/04/09 14:34:18 INFO ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 4)20/04/09 14:34:19 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 5)20/04/09 14:34:20 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor)(10.75.37.249:36354) with ID 220/04/09 14:34:20 INFO ExecutorAllocationManager: New executor 2 has registered (new total is 2)20/04/09 14:34:20 INFO TaskSetManager: Starting task 1.0in stage 0.0(TID 1, yarn01.domain.com, executor 2, partition 1, PROCESS_LOCAL, 7869 bytes)20/04/09 14:34:20 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:29181 with 114.6 MB RAM, BlockManagerId(2, yarn01.domain.com, 29181, None)20/04/09 14:34:20 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:29181(size: 3.7 KB, free: 114.6 MB)20/04/09 14:34:21 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor)(10.75.37.249:36366) with ID 320/04/09 14:34:21 INFO ExecutorAllocationManager: New executor 3 has registered (new total is 3)20/04/09 14:34:21 INFO TaskSetManager: Starting task 2.0in stage 0.0(TID 2, yarn01.domain.com, executor 3, partition 2, PROCESS_LOCAL, 7869 bytes)20/04/09 14:34:21 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:44000 with 114.6 MB RAM, BlockManagerId(3, yarn01.domain.com, 44000, None)20/04/09 14:34:21 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:44000(size: 3.7 KB, free: 114.6 MB)20/04/09 14:34:22 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor)(10.75.37.249:36376) with ID 520/04/09 14:34:22 INFO ExecutorAllocationManager: New executor 5 has registered (new total is 4)20/04/09 14:34:22 INFO TaskSetManager: Starting task 3.0in stage 0.0(TID 3, yarn01.domain.com, executor 5, partition 3, PROCESS_LOCAL, 7869 bytes)20/04/09 14:34:22 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:32822 with 114.6 MB RAM, BlockManagerId(5, yarn01.domain.com, 32822, None)20/04/09 14:34:22 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:32822(size: 3.7 KB, free: 114.6 MB)20/04/09 14:34:27 INFO TaskSetManager: Starting task 4.0in stage 0.0(TID 4, yarn01.domain.com, executor 1, partition 4, PROCESS_LOCAL, 7869 bytes)20/04/09 14:34:27 INFO TaskSetManager: Finished task 0.0in stage 0.0(TID 0)in10890 ms on yarn01.domain.com (executor 1)(1/5)20/04/09 14:34:27 INFO PythonAccumulatorV2: Connected to AccumulatorServer at host: 127.0.0.1 port: 3135420/04/09 14:34:29 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor)(10.75.37.248:57764) with ID 420/04/09 14:34:29 INFO ExecutorAllocationManager: New executor 4 has registered (new total is 5)20/04/09 14:34:29 INFO BlockManagerMasterEndpoint: Registering block manager worker01.domain.com:38365 with 114.6 MB RAM, BlockManagerId(4, worker01.domain.com, 38365, None)20/04/09 14:34:34 INFO ExecutorAllocationManager: Request to remove executorIds: 420/04/09 14:34:34 INFO YarnClientSchedulerBackend: Requesting to kill executor(s)420/04/09 14:34:34 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 420/04/09 14:34:34 INFO ExecutorAllocationManager: Removing executor 4 because it has been idle for5 seconds (new desired total will be 4)20/04/09 14:34:38 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 4.
20/04/09 14:34:38 INFO DAGScheduler: Executor lost: 4(epoch 0)20/04/09 14:34:38 INFO BlockManagerMasterEndpoint: Trying to remove executor 4 from BlockManagerMaster.
20/04/09 14:34:38 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(4, worker01.domain.com, 38365, None)20/04/09 14:34:38 INFO BlockManagerMaster: Removed 4 successfully in removeExecutor
20/04/09 14:34:38 INFO YarnScheduler: Executor 4 on worker01.domain.com killed by driver.
20/04/09 14:34:38 INFO ExecutorAllocationManager: Existing executor 4 has been removed (new total is 4)20/04/09 14:34:41 INFO TaskSetManager: Finished task 1.0in stage 0.0(TID 1)in20892 ms on yarn01.domain.com (executor 2)(2/5)20/04/09 14:34:46 INFO ExecutorAllocationManager: Request to remove executorIds: 220/04/09 14:34:46 INFO YarnClientSchedulerBackend: Requesting to kill executor(s)220/04/09 14:34:46 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 220/04/09 14:34:46 INFO ExecutorAllocationManager: Removing executor 2 because it has been idle for5 seconds (new desired total will be 3)20/04/09 14:34:48 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 2.
20/04/09 14:34:48 INFO DAGScheduler: Executor lost: 2(epoch 0)20/04/09 14:34:48 INFO BlockManagerMasterEndpoint: Trying to remove executor 2 from BlockManagerMaster.
20/04/09 14:34:48 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(2, yarn01.domain.com, 29181, None)20/04/09 14:34:48 INFO BlockManagerMaster: Removed 2 successfully in removeExecutor
20/04/09 14:34:48 INFO YarnScheduler: Executor 2 on yarn01.domain.com killed by driver.
20/04/09 14:34:48 INFO ExecutorAllocationManager: Existing executor 2 has been removed (new total is 3)20/04/09 14:34:52 INFO TaskSetManager: Finished task 2.0in stage 0.0(TID 2)in30897 ms on yarn01.domain.com (executor 3)(3/5)20/04/09 14:34:57 INFO ExecutorAllocationManager: Request to remove executorIds: 320/04/09 14:34:57 INFO YarnClientSchedulerBackend: Requesting to kill executor(s)320/04/09 14:34:57 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 320/04/09 14:34:57 INFO ExecutorAllocationManager: Removing executor 3 because it has been idle for5 seconds (new desired total will be 2)20/04/09 14:34:59 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 3.
20/04/09 14:34:59 INFO DAGScheduler: Executor lost: 3(epoch 0)20/04/09 14:34:59 INFO BlockManagerMasterEndpoint: Trying to remove executor 3 from BlockManagerMaster.
20/04/09 14:34:59 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(3, yarn01.domain.com, 44000, None)20/04/09 14:34:59 INFO BlockManagerMaster: Removed 3 successfully in removeExecutor
20/04/09 14:34:59 INFO YarnScheduler: Executor 3 on yarn01.domain.com killed by driver.
20/04/09 14:34:59 INFO ExecutorAllocationManager: Existing executor 3 has been removed (new total is 2)20/04/09 14:35:03 INFO TaskSetManager: Finished task 3.0in stage 0.0(TID 3)in40831 ms on yarn01.domain.com (executor 5)(4/5)20/04/09 14:35:08 INFO ExecutorAllocationManager: Request to remove executorIds: 520/04/09 14:35:08 INFO YarnClientSchedulerBackend: Requesting to kill executor(s)520/04/09 14:35:08 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 520/04/09 14:35:08 INFO ExecutorAllocationManager: Removing executor 5 because it has been idle for5 seconds (new desired total will be 1)20/04/09 14:35:10 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 5.
20/04/09 14:35:10 INFO DAGScheduler: Executor lost: 5(epoch 0)20/04/09 14:35:10 INFO BlockManagerMasterEndpoint: Trying to remove executor 5 from BlockManagerMaster.
20/04/09 14:35:10 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(5, yarn01.domain.com, 32822, None)20/04/09 14:35:10 INFO BlockManagerMaster: Removed 5 successfully in removeExecutor
20/04/09 14:35:10 INFO YarnScheduler: Executor 5 on yarn01.domain.com killed by driver.
20/04/09 14:35:10 INFO ExecutorAllocationManager: Existing executor 5 has been removed (new total is 1)20/04/09 14:35:17 INFO TaskSetManager: Finished task 4.0in stage 0.0(TID 4)in50053 ms on yarn01.domain.com (executor 1)(5/5)20/04/09 14:35:17 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
.
.
20/04/09 14:34:14 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
20/04/09 14:34:16 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.75.37.249:36332) with ID 1
20/04/09 14:34:16 INFO ExecutorAllocationManager: New executor 1 has registered (new total is 1)
.
.
20/04/09 14:34:17 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2)
20/04/09 14:34:18 INFO ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 4)
20/04/09 14:34:19 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 5)
20/04/09 14:34:20 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.75.37.249:36354) with ID 2
20/04/09 14:34:20 INFO ExecutorAllocationManager: New executor 2 has registered (new total is 2)
20/04/09 14:34:20 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, yarn01.domain.com, executor 2, partition 1, PROCESS_LOCAL, 7869 bytes)
20/04/09 14:34:20 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:29181 with 114.6 MB RAM, BlockManagerId(2, yarn01.domain.com, 29181, None)
20/04/09 14:34:20 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:29181 (size: 3.7 KB, free: 114.6 MB)
20/04/09 14:34:21 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.75.37.249:36366) with ID 3
20/04/09 14:34:21 INFO ExecutorAllocationManager: New executor 3 has registered (new total is 3)
20/04/09 14:34:21 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, yarn01.domain.com, executor 3, partition 2, PROCESS_LOCAL, 7869 bytes)
20/04/09 14:34:21 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:44000 with 114.6 MB RAM, BlockManagerId(3, yarn01.domain.com, 44000, None)
20/04/09 14:34:21 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:44000 (size: 3.7 KB, free: 114.6 MB)
20/04/09 14:34:22 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.75.37.249:36376) with ID 5
20/04/09 14:34:22 INFO ExecutorAllocationManager: New executor 5 has registered (new total is 4)
20/04/09 14:34:22 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, yarn01.domain.com, executor 5, partition 3, PROCESS_LOCAL, 7869 bytes)
20/04/09 14:34:22 INFO BlockManagerMasterEndpoint: Registering block manager yarn01.domain.com:32822 with 114.6 MB RAM, BlockManagerId(5, yarn01.domain.com, 32822, None)
20/04/09 14:34:22 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on yarn01.domain.com:32822 (size: 3.7 KB, free: 114.6 MB)
20/04/09 14:34:27 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, yarn01.domain.com, executor 1, partition 4, PROCESS_LOCAL, 7869 bytes)
20/04/09 14:34:27 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 10890 ms on yarn01.domain.com (executor 1) (1/5)
20/04/09 14:34:27 INFO PythonAccumulatorV2: Connected to AccumulatorServer at host: 127.0.0.1 port: 31354
20/04/09 14:34:29 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.75.37.248:57764) with ID 4
20/04/09 14:34:29 INFO ExecutorAllocationManager: New executor 4 has registered (new total is 5)
20/04/09 14:34:29 INFO BlockManagerMasterEndpoint: Registering block manager worker01.domain.com:38365 with 114.6 MB RAM, BlockManagerId(4, worker01.domain.com, 38365, None)
20/04/09 14:34:34 INFO ExecutorAllocationManager: Request to remove executorIds: 4
20/04/09 14:34:34 INFO YarnClientSchedulerBackend: Requesting to kill executor(s) 4
20/04/09 14:34:34 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 4
20/04/09 14:34:34 INFO ExecutorAllocationManager: Removing executor 4 because it has been idle for 5 seconds (new desired total will be 4)
20/04/09 14:34:38 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 4.
20/04/09 14:34:38 INFO DAGScheduler: Executor lost: 4 (epoch 0)
20/04/09 14:34:38 INFO BlockManagerMasterEndpoint: Trying to remove executor 4 from BlockManagerMaster.
20/04/09 14:34:38 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(4, worker01.domain.com, 38365, None)
20/04/09 14:34:38 INFO BlockManagerMaster: Removed 4 successfully in removeExecutor
20/04/09 14:34:38 INFO YarnScheduler: Executor 4 on worker01.domain.com killed by driver.
20/04/09 14:34:38 INFO ExecutorAllocationManager: Existing executor 4 has been removed (new total is 4)
20/04/09 14:34:41 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 20892 ms on yarn01.domain.com (executor 2) (2/5)
20/04/09 14:34:46 INFO ExecutorAllocationManager: Request to remove executorIds: 2
20/04/09 14:34:46 INFO YarnClientSchedulerBackend: Requesting to kill executor(s) 2
20/04/09 14:34:46 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 2
20/04/09 14:34:46 INFO ExecutorAllocationManager: Removing executor 2 because it has been idle for 5 seconds (new desired total will be 3)
20/04/09 14:34:48 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 2.
20/04/09 14:34:48 INFO DAGScheduler: Executor lost: 2 (epoch 0)
20/04/09 14:34:48 INFO BlockManagerMasterEndpoint: Trying to remove executor 2 from BlockManagerMaster.
20/04/09 14:34:48 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(2, yarn01.domain.com, 29181, None)
20/04/09 14:34:48 INFO BlockManagerMaster: Removed 2 successfully in removeExecutor
20/04/09 14:34:48 INFO YarnScheduler: Executor 2 on yarn01.domain.com killed by driver.
20/04/09 14:34:48 INFO ExecutorAllocationManager: Existing executor 2 has been removed (new total is 3)
20/04/09 14:34:52 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 30897 ms on yarn01.domain.com (executor 3) (3/5)
20/04/09 14:34:57 INFO ExecutorAllocationManager: Request to remove executorIds: 3
20/04/09 14:34:57 INFO YarnClientSchedulerBackend: Requesting to kill executor(s) 3
20/04/09 14:34:57 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 3
20/04/09 14:34:57 INFO ExecutorAllocationManager: Removing executor 3 because it has been idle for 5 seconds (new desired total will be 2)
20/04/09 14:34:59 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 3.
20/04/09 14:34:59 INFO DAGScheduler: Executor lost: 3 (epoch 0)
20/04/09 14:34:59 INFO BlockManagerMasterEndpoint: Trying to remove executor 3 from BlockManagerMaster.
20/04/09 14:34:59 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(3, yarn01.domain.com, 44000, None)
20/04/09 14:34:59 INFO BlockManagerMaster: Removed 3 successfully in removeExecutor
20/04/09 14:34:59 INFO YarnScheduler: Executor 3 on yarn01.domain.com killed by driver.
20/04/09 14:34:59 INFO ExecutorAllocationManager: Existing executor 3 has been removed (new total is 2)
20/04/09 14:35:03 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 40831 ms on yarn01.domain.com (executor 5) (4/5)
20/04/09 14:35:08 INFO ExecutorAllocationManager: Request to remove executorIds: 5
20/04/09 14:35:08 INFO YarnClientSchedulerBackend: Requesting to kill executor(s) 5
20/04/09 14:35:08 INFO YarnClientSchedulerBackend: Actual list of executor(s) to be killed is 5
20/04/09 14:35:08 INFO ExecutorAllocationManager: Removing executor 5 because it has been idle for 5 seconds (new desired total will be 1)
20/04/09 14:35:10 INFO YarnSchedulerBackend$YarnDriverEndpoint: Disabling executor 5.
20/04/09 14:35:10 INFO DAGScheduler: Executor lost: 5 (epoch 0)
20/04/09 14:35:10 INFO BlockManagerMasterEndpoint: Trying to remove executor 5 from BlockManagerMaster.
20/04/09 14:35:10 INFO BlockManagerMasterEndpoint: Removing block manager BlockManagerId(5, yarn01.domain.com, 32822, None)
20/04/09 14:35:10 INFO BlockManagerMaster: Removed 5 successfully in removeExecutor
20/04/09 14:35:10 INFO YarnScheduler: Executor 5 on yarn01.domain.com killed by driver.
20/04/09 14:35:10 INFO ExecutorAllocationManager: Existing executor 5 has been removed (new total is 1)
20/04/09 14:35:17 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 50053 ms on yarn01.domain.com (executor 1) (5/5)
20/04/09 14:35:17 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
.
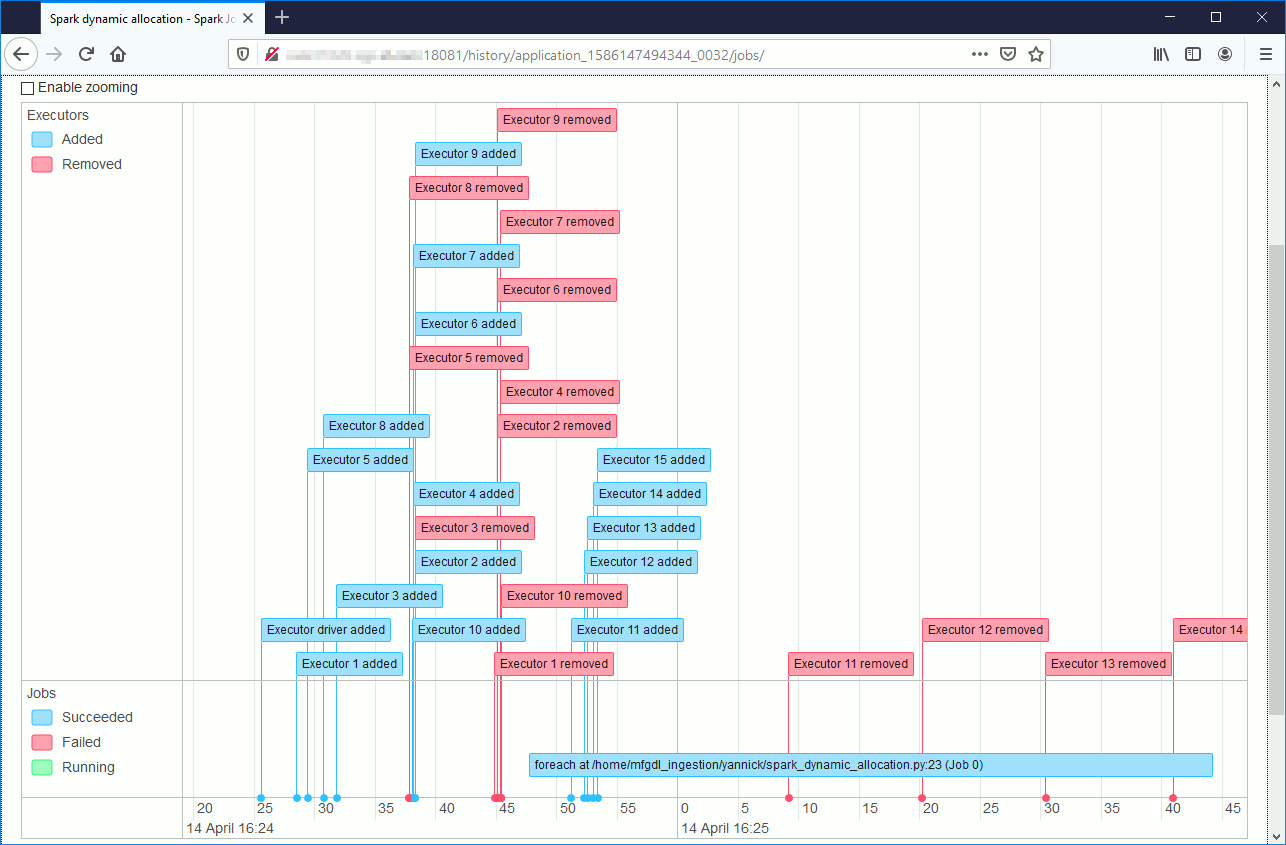
We clearly see the allocation and removal of executors but it is even more clear with the Spark UI web interface:
spark_dynamic_allocation04
The executors dynamically added in blue well contrast with the ones dynamically removed in red…
One of my colleague asked me if by mistake he allocates too many initial executors and his over allocation is wasting ressource. I have done this trial by specifying in my code: