Table of contents
Preamble
One of our three JournalNodes was constantly failing for an alert on JournalNode Web UI saying the connection to http://journalnode3.domain.com:8480 has timed out.
In Ambari the configured alert is this one:
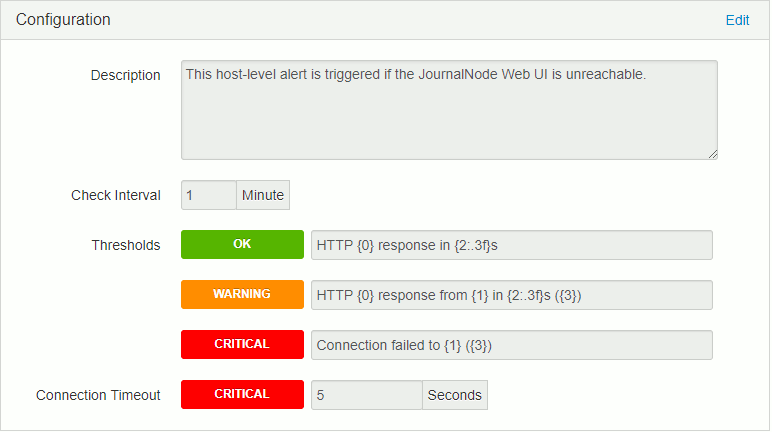
JournalNodes is:
High-availabilty clusters use JournalNodes to synchronize active and standby NameNodes. The active NameNode writes to each JournalNode with changes, or “edits,” to HDFS namespace metadata. During failover, the standby NameNode applies all edits from the JournalNodes before promoting itself to the active state.
Obviously the URL is also not responding when accessing to it through a web browser…
JournalNode Web UI time out resolution
The port was correctly use by a listening process:
[root@journalnode3 ~]# netstat -an | grep 8480 |grep LISTEN tcp 0 0 0.0.0.0:8480 0.0.0.0:* LISTEN |
Found this interesting article called Frequent journal node connection timeout alerts.
As suggested and expected curl command do not give anything and end up with a timed out:
[root@journalnode3 ~]# curl -v http://journalnode3.domain.com:8480 --max-time 4 | tail -4 |
I also had tens of CLOSE_WAIT connection to this port using below suggested command:
[root@journalnode3 ~]# netstat -putane | grep -i 8480 |
You can find the JournalNodes directory with dfs.journalnode.edits.dir HDFS variable, which is set to /var/qjn for me.
The files in the directory of the problematic node were all out of date:
. -rw-r--r-- 1 hdfs hadoop 182246 Oct 31 13:43 edits_0000000000175988225-0000000000175989255 -rw-r--r-- 1 hdfs hadoop 595184 Oct 31 13:45 edits_0000000000175989256-0000000000175992263 -rw-r--r-- 1 hdfs hadoop 216550 Oct 31 13:47 edits_0000000000175992264-0000000000175993354 -rw-r--r-- 1 hdfs hadoop 472885 Oct 31 13:49 edits_0000000000175993355-0000000000175995694 -rw-r--r-- 1 hdfs hadoop 282984 Oct 31 13:51 edits_0000000000175995695-0000000000175997143 -rw-r--r-- 1 hdfs hadoop 8 Oct 31 13:51 committed-txid -rw-r--r-- 1 hdfs hadoop 626688 Oct 31 13:51 edits_inprogress_0000000000175997144 |
Versus the directory on one of the two working well JournalNodes:
. -rw-r--r-- 1 hdfs hadoop 174901 Nov 8 11:28 edits_0000000000184771705-0000000000184772755 -rw-r--r-- 1 hdfs hadoop 418119 Nov 8 11:30 edits_0000000000184772756-0000000000184774838 -rw-r--r-- 1 hdfs hadoop 342889 Nov 8 11:32 edits_0000000000184774839-0000000000184776640 -rw-r--r-- 1 hdfs hadoop 270983 Nov 8 11:34 edits_0000000000184776641-0000000000184778154 -rw-r--r-- 1 hdfs hadoop 593676 Nov 8 11:36 edits_0000000000184778155-0000000000184781027 -rw-r--r-- 1 hdfs hadoop 1048576 Nov 8 11:37 edits_inprogress_0000000000184781028 |
in /var/log/hadoop/hdfs log directory I have also seen in hadoop-hdfs-journalnode-server1.domain.com.log file below error messages:
2018-11-08 12:18:20,949 WARN namenode.FSImage (EditLogFileInputStream.java:scanEditLog(359)) - Caught exception after scanning through 0 ops from /var/qjn/ManufacturingDataLakeHdfs/current/edits_inprogress_0000000000175997144 while determining its valid length. Position was 626688 java.io.IOException: Can't scan a pre-transactional edit log. at org.apache.hadoop.hdfs.server.namenode.FSEditLogOp$LegacyReader.scanOp(FSEditLogOp.java:4974) at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanNextOp(EditLogFileInputStream.java:245) at org.apache.hadoop.hdfs.server.namenode.EditLogFileInputStream.scanEditLog(EditLogFileInputStream.java:355) at org.apache.hadoop.hdfs.server.namenode.FileJournalManager$EditLogFile.scanLog(FileJournalManager.java:551) at org.apache.hadoop.hdfs.qjournal.server.Journal.scanStorageForLatestEdits(Journal.java:192) at org.apache.hadoop.hdfs.qjournal.server.Journal.<init>(Journal.java:152) at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:90) at org.apache.hadoop.hdfs.qjournal.server.JournalNode.getOrCreateJournal(JournalNode.java:99) at org.apache.hadoop.hdfs.qjournal.server.JournalNodeRpcServer.startLogSegment(JournalNodeRpcServer.java:165) at org.apache.hadoop.hdfs.qjournal.protocolPB.QJournalProtocolServerSideTranslatorPB.startLogSegment(QJournalProtocolServerSideTranslatorPB.java:186) at org.apache.hadoop.hdfs.qjournal.protocol.QJournalProtocolProtos$QJournalProtocolService$2.callBlockingMethod(QJournalProtocolProtos.java:25425) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1869) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2347) |
I have stopped JournalNodes process via Ambari on problematic server and moves the edits_inprogress_xxx file that was out of date:
[root@journalnode3 current]# pwd /var/qjn/Hdfsproject/current [root@journalnode3 current]# mv edits_inprogress_0000000000175997144 edits_inprogress_0000000000175997144.bak |
And restarted via Ambari the JournalNodes process on this server… It has taken a while to recover the situation but after few days the log generation have decreased and problematic JournalNodes was able to cope with latency… You might also delete the entire directory, not tested personally but should work…
Watch out the log directory size on problematic JounalNodes server as it may fill up very fast…
References
- A Journal Node is in Bad Health in Cloudera Manager with “java.io.IOException: Can’t scan a pre-transactional edit log” (Doc ID 2160881.1)
- HDFS Metadata Directories Explained






pranay says:
You are not a friend nor a teacher you are the saviour. Thank you so much.
Please keep doing this good work.
Yannick Jaquier says:
Thanks for enthusiastic comment !! 🙂