Table of contents
Preamble
In our ramp up period we wanted to estimate already consumed HDFS size as well as how is split this used space. This would help us build HDFS capacity planning plan and know which investment would be needed. I have found tons of document on how to do it but the snapshot “issue” I had was a nice discover…
HDFS capacity planning first estimation
The real two first commands you would use are:
[hdfs@clientnode ~]$ hdfs dfs -df -h / Filesystem Size Used Available Use% hdfs://DataLakeHdfs 89.5 T 22.4 T 62.5 T 25% |
And:
[hdfs@clientnode ~]$ hdfs dfs -du -s -h / 5.9 T / |
You can drill down directories size with:
[hdfs@clientnode ~]$ hdfs dfs -du -h / 169.0 G /app-logs 466.7 M /apps 12.5 G /ats 3.1 T /data 710.4 M /hdp 0 /livy2-recovery 0 /mapred 16.8 M /mr-history 1004.4 M /spark2-history 2.1 T /tmp 479.7 G /user |
In HDFS you have dfs.datanode.du.reserved which specify a reserved space in bytes per volume. This is set to 1243,90869140625 MB in my environment.
I also have below HDFS parameters that will be part of formula:
| Parameter | Value | Description |
|---|---|---|
| dfs.datanode.du.reserved | 1304332800 bytes | Reserved space in bytes per volume. Always leave this much space free for non dfs use. |
| dfs.blocksize | 128MB | The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). |
| dfs.replication | 3 | Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. |
| fs.trash.interval | 360 (minutes) | Number of minutes after which the checkpoint gets deleted. If zero, the trash feature is disabled. This option may be configured both on the server and the client. If trash is disabled server side then the client side configuration is checked. If trash is enabled on the server side then the value configured on the server is used and the client configuration value is ignored. |
You can have a complete report with more precise number than hdfs dfs -df -h / command for all your worker nodes using below command:
[hdfs@clientnode ~]$ hdfs dfsadmin -report Configured Capacity: 98378048588800 (89.47 TB) Present Capacity: 93368566571440 (84.92 TB) DFS Remaining: 68685157293611 (62.47 TB) DFS Used: 24683409277829 (22.45 TB) DFS Used%: 26.44% Under replicated blocks: 20 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (5): Name: 10.75.144.13:50010 (worker3.domain.com) Hostname: worker3.domain.com Rack: /AH/26 Decommission Status : Normal Configured Capacity: 19675609717760 (17.89 TB) DFS Used: 3676038734820 (3.34 TB) Non DFS Used: 0 (0 B) DFS Remaining: 14998265052417 (13.64 TB) DFS Used%: 18.68% DFS Remaining%: 76.23% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 16 Last contact: Wed Oct 24 14:57:06 CEST 2018 Last Block Report: Wed Oct 24 11:48:58 CEST 2018 Name: 10.75.144.12:50010 (worker2.domain.com) Hostname: worker2.domain.com Rack: /AH/26 Decommission Status : Normal Configured Capacity: 19675609717760 (17.89 TB) DFS Used: 3884987861604 (3.53 TB) Non DFS Used: 0 (0 B) DFS Remaining: 14789450082223 (13.45 TB) DFS Used%: 19.75% DFS Remaining%: 75.17% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 14 Last contact: Wed Oct 24 14:57:06 CEST 2018 Last Block Report: Wed Oct 24 09:44:51 CEST 2018 Name: 10.75.144.14:50010 (worker4.domain.com) Hostname: worker4.domain.com Rack: /AH/27 Decommission Status : Normal Configured Capacity: 19675609717760 (17.89 TB) DFS Used: 6604991718895 (6.01 TB) Non DFS Used: 0 (0 B) DFS Remaining: 12068909438191 (10.98 TB) DFS Used%: 33.57% DFS Remaining%: 61.34% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 22 Last contact: Wed Oct 24 14:57:06 CEST 2018 Last Block Report: Wed Oct 24 12:36:28 CEST 2018 Name: 10.75.144.11:50010 (worker1.domain.com) Hostname: worker1.domain.com Rack: /AH/26 Decommission Status : Normal Configured Capacity: 19675609717760 (17.89 TB) DFS Used: 3983207846801 (3.62 TB) Non DFS Used: 0 (0 B) DFS Remaining: 14690022328249 (13.36 TB) DFS Used%: 20.24% DFS Remaining%: 74.66% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 32 Last contact: Wed Oct 24 14:57:06 CEST 2018 Last Block Report: Wed Oct 24 13:50:10 CEST 2018 Name: 10.75.144.15:50010 (worker5.domain.com) Hostname: worker5.domain.com Rack: /AH/27 Decommission Status : Normal Configured Capacity: 19675609717760 (17.89 TB) DFS Used: 6534183115709 (5.94 TB) Non DFS Used: 0 (0 B) DFS Remaining: 12138510392531 (11.04 TB) DFS Used%: 33.21% DFS Remaining%: 61.69% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 40 Last contact: Wed Oct 24 14:57:04 CEST 2018 Last Block Report: Wed Oct 24 10:41:56 CEST 2018 |
So far if I do my computation I get 5.9 TB * 3 (dfs.replication) = 17.7 TB, I am a bit below the 22.4 TB used of hdfs dfs -df -h / command… Where has gone the 4.7 TB ? Quite a few TB isn’t it ?
HDFS snapshot situation
Then after a bit on investigation I had the idea to check if HDFS snapshots have been created on my HDFS:
[hdfs@clientnode ~]$ hdfs lsSnapshottableDir -help Usage: hdfs lsSnapshottableDir: Get the list of snapshottable directories that are owned by the current user. Return all the snapshottable directories if the current user is a super user. [hdfs@clientnode ~]$ hdfs lsSnapshottableDir drwxr-xr-x 0 hdfs hdfs 0 2018-07-13 18:14 1 65536 / |
You can get snapshot(s) name(s) with:
[hdfs@clientnode ~]$ hdfs dfs -ls /.snapshot Found 1 items drwxr-xr-x - hdfs hdfs 0 2018-07-13 18:14 /.snapshot/s20180713-101304.832 |
Computing snapshot size is not possible as in case of a pointer to origial block (block not modified) the size of the original block will be added:
[hdfs@clientnode ~]$ hdfs dfs -du -h /.snapshot 3.3 T /.snapshot/s20180713-101304.832 |
You can also get a graphical access using NameNode UI in Ambari:
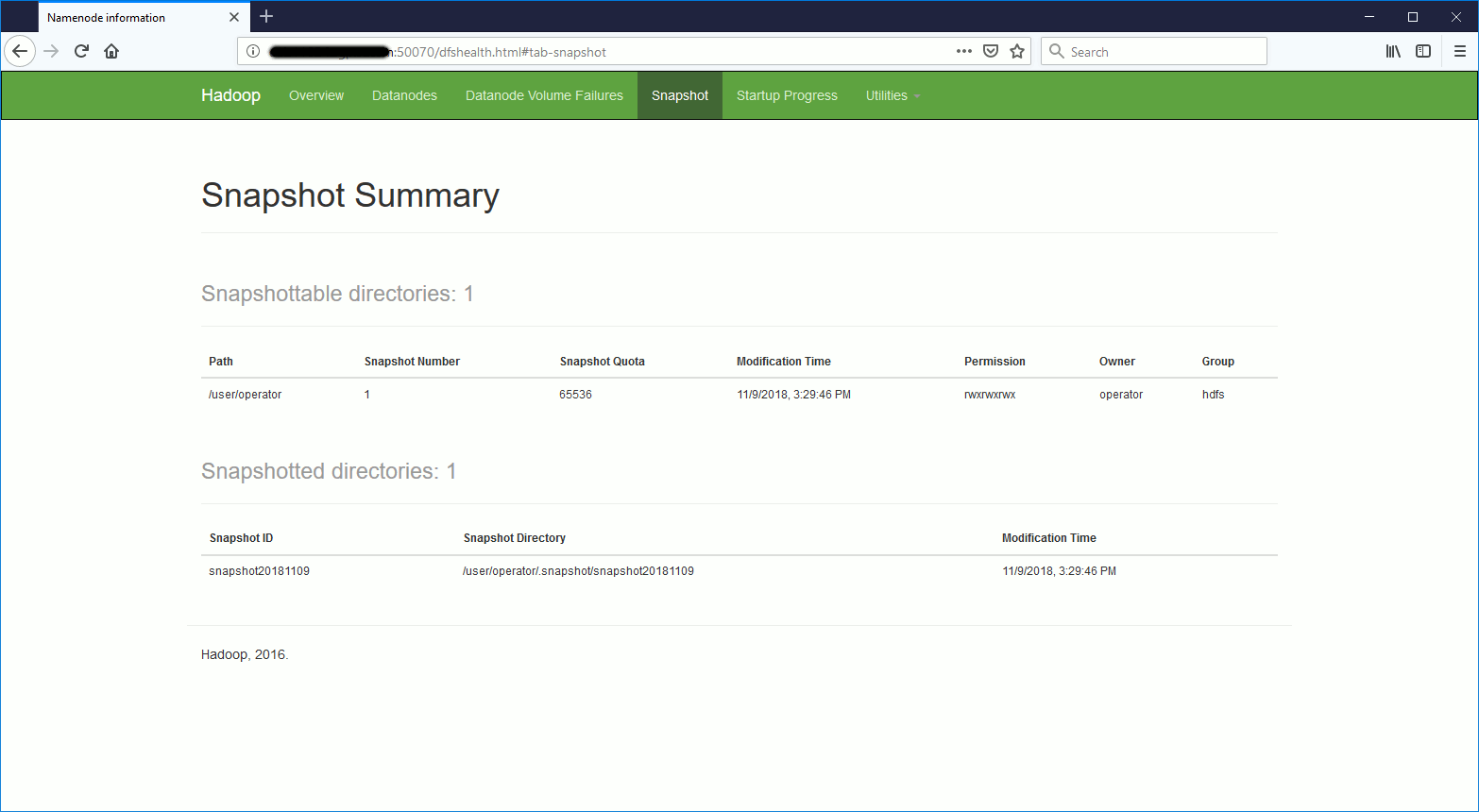
Here we are a snapshot of HDFS root directory has been created… I rated this tricky as you don’t see it with a hdfs dfs du command:
[hdfs@clientnode ~]$ hdfs dfs -du -h / 169.0 G /app-logs 466.7 M /apps 4.7 G /ats 3.1 T /data 710.4 M /hdp 0 /livy2-recovery 0 /mapred 0 /mr-history 1004.4 M /spark2-history 2.1 T /tmp 173.9 G /user |
I have also performed a HSFS filesystem check to be sure everything is fine and no blocks have been marked corrupted:
[hdfs@clientnode ~]$ hdfs fsck . . ........................ /user/training/.staging/job_1519657336782_0105/job.jar: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1073754565_13755. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). . /user/training/.staging/job_1519657336782_0105/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1073754566_13756. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1519657336782_0105/libjars/hive-hcatalog-core.jar: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1073754564_13754. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). . /user/training/.staging/job_1536057043538_0001/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085621525_11894367. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0002/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085621527_11894369. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0004/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085621593_11894435. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0023/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085622064_11894906. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0025/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085622086_11894928. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0027/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085622115_11894957. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536057043538_0028/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1085622133_11894975. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0002/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397707_12670663. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0003/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397706_12670662. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0004/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397708_12670664. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0005/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397718_12670674. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0006/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397720_12670676. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_0007/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086397721_12670677. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). ..... /user/training/.staging/job_1536642465198_2307/job.split: Under replicated BP-1711156358-10.75.144.1-1519036486930:blk_1086509846_12782817. Target Replicas is 10 but found 5 live replica(s), 0 decommissioned replica(s) and 0 decommissioning replica(s). .... Status: HEALTHY Total size: 5981414347660 B (Total open files size: 455501 B) Total dirs: 740032 Total files: 3766023 Total symlinks: 0 (Files currently being written: 17) Total blocks (validated): 3781239 (avg. block size 1581866 B) (Total open file blocks (not validated): 17) Minimally replicated blocks: 3781239 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 20 (5.2892714E-4 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 3.0000105 Corrupt blocks: 0 Missing replicas: 100 (8.8153436E-4 %) Number of data-nodes: 5 Number of racks: 2 FSCK ended at Wed Oct 17 16:12:48 CEST 2018 in 61172 milliseconds The filesystem under path '/' is HEALTHY |
After delete of HDFS snapshot
Get snapshot(s) name(s) and delete them with, I have also forbid further creation of any snapshot on root directory (does not make sense in my opinion):
[hdfs@clientnode ~]$ hdfs dfsadmin -disallowSnapshot / disallowSnapshot: The directory / has snapshot(s). Please redo the operation after removing all the snapshots. [hdfs@clientnode ~]$ hdfs dfs -ls /.snapshot Found 1 items drwxr-xr-x - hdfs hdfs 0 2018-07-13 18:14 /.snapshot/s20180713-101304.832 [hdfs@clientnode ~]$ hdfs dfs -deleteSnapshot / s20180713-101304.832 [hdfs@clientnode ~]$ hdfs dfsadmin -disallowSnapshot / Disallowing snaphot on / succeeded [hdfs@clientnode ~]$ hdfs lsSnapshottableDir |
After a cleaning phase I reach the stable below situation:
[hdfs@clientnode ~]$ hdfs dfs -df -h / Filesystem Size Used Available Use% hdfs://DataLakeHdfs 89.5 T 16.8 T 68.1 T 19% [hdfs@clientnode ~]$ hdfs dfs -du -s -h / 5.5 T / |
So the computation is more accurate as 5.5 * 3 = 16.5 # 16.8.
As you have noticed my /tmp directory is 2.1 TB which is quite a lot of space for a temporary directory. For me all occupied space was directories under /tmp/hive. It end up that it is aborted Hive queries and can be safely deleted (we currently have one directory of 1.7 TB !!!):
| Parameter | Description | Value |
|---|---|---|
| hive.exec.scratchdir | This directory is used by Hive to store the plans for different map/reduce stages for the query as well as to stored the intermediate outputs of these stages. Hive 0.14.0 and later: HDFS root scratch directory for Hive jobs, which gets created with write all (733) permission. For each connecting user, an HDFS scratch directory ${hive.exec.scratchdir}/ | /tmp/ /tmp/hive- /tmp/hive (Hive 0.14.0 and later) |





