Since we have started our Hadoop journey and more particularly developing Spark jobs in Scala and Python having a efficient development environment has always been a challenge.
What we currently do is using a remote edition via SSH FS plugins in VSCode and submitting script in a shell terminal directly from one of our edge nodes.
VSCode is a wonderful tool but it lacks the code completion and suggestion as well as tips that increase your productivity, at least in PySPark and Scala language. Recently I have succeeded to configure the community edition of Intellij from IDEA to submit job on my desktop using the data from our Hadoop cluster. Aside this configuration I have also configured a local Spark environment as well as sbt compiler for Scala jobs. I will share soon an article on this…
One of my teammate suggested the use of Livy so decided to have a look even if at the end I have been a little disappointed by its capability…
Livy is a Rest interface from which you interact with a Spark Cluster. In our Hadoop HortonWorks HDP 2.6 installation the Livy server comes pre-installed and in short I had nothing to do to install or configure it. If you are in a different configuration you might have to install and configure by yourself the Livy server.
Configuration
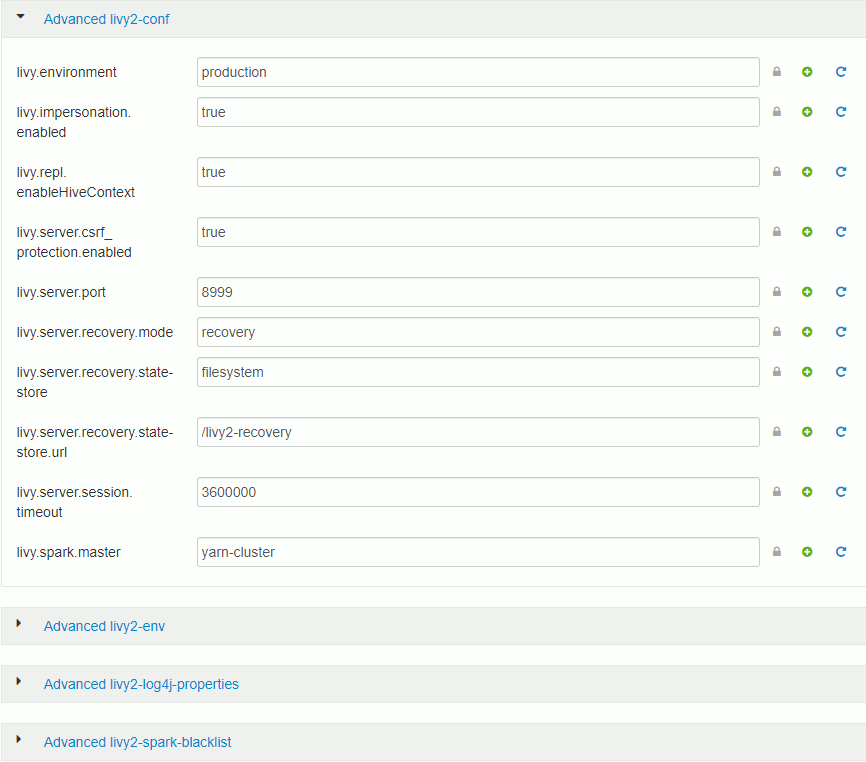
On our Hadoop cluster Livy server came with Spark installation and is already configured as such:
livy01
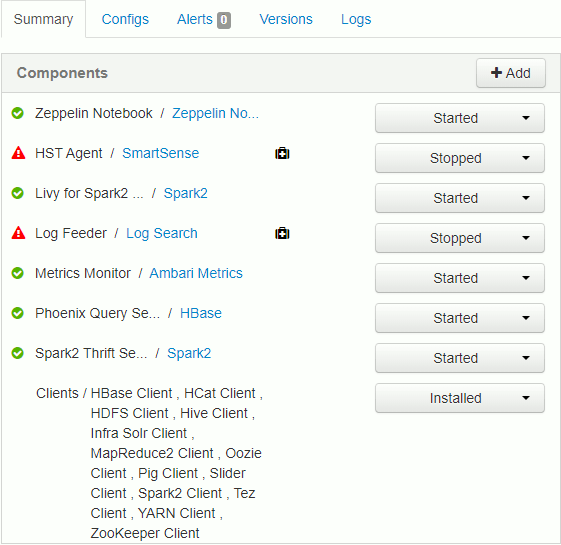
To understand on which server, and if process is running, follow the link of Spark service home page as follow:
livy02
You finnally have server name and process status where Livy server is running:
livy03
You can access it using your preferred browser:
livy04
Curl testing
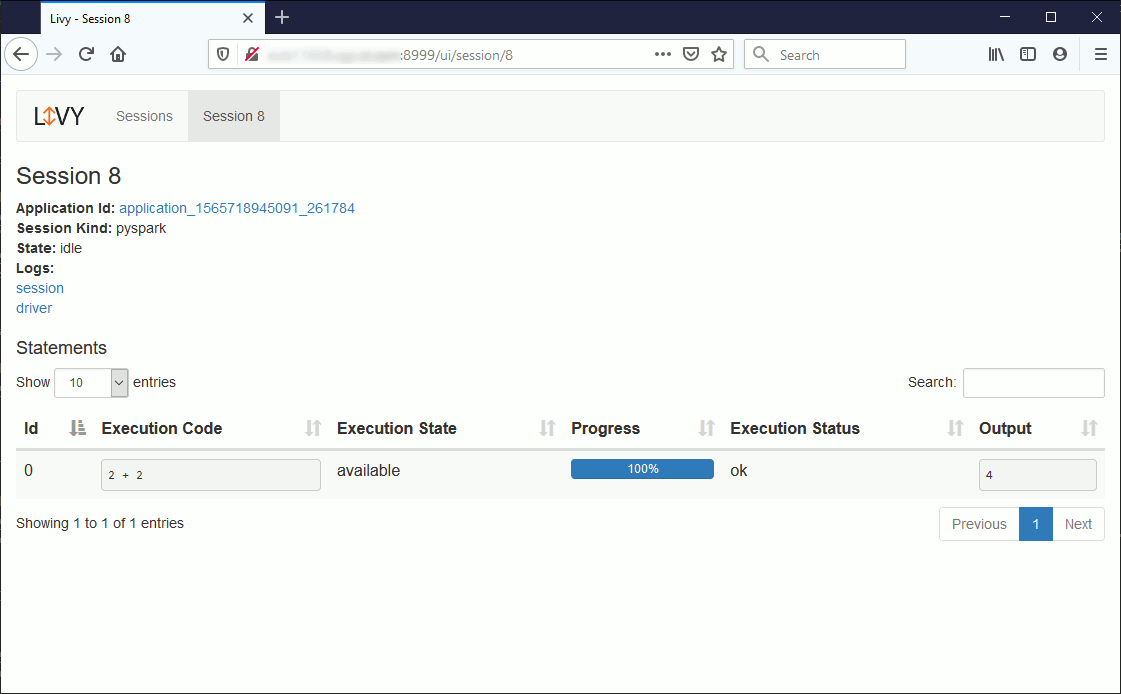
Curl is, as you know, a tool to test resources across a network. Here we will use it to access the Livy Rest API resources. Interactive commands to this REST API can be done using Scala, Python and R.
Even if the official documentation is around Python scripts I have been able to resolve an annoying error using Curl. I have started with:
I have found that livy.server.csrf_protection.enabled parameter was set to true in my configuration so I had to specify an extra parameter in header request using X-Requested-By: parameter:
Python is what Livy documentation is pushing by default to test the service. I have started by installing requests package (as well as upgrading pip):
PS D:\> python -m pip install--upgrade pip --user
Collecting pip
Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB)|████████████████████████████████| 1.4MB 2.2MB/s
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Installing collected packages: pip
Successfully installed pip-19.3.1
WARNING: You are using pip version 19.2.3, however version 19.3.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
PS D:\> python -m pip install --upgrade pip --user
Collecting pip
Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB)
|████████████████████████████████| 1.4MB 2.2MB/s
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Installing collected packages: pip
Successfully installed pip-19.3.1
WARNING: You are using pip version 19.2.3, however version 19.3.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
Requests package installation:
PS D:\> python -m pip install requests --user
Collecting requests
Downloading https://files.pythonhosted.org/packages/51/bd/23c926cd341ea6b7dd0b2a00aba99ae0f828be89d72b2190f27c11d4b7fb/requests-2.22.0-py2.py3-none-any.whl (57kB)|████████████████████████████████| 61kB 563kB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests)
Downloading https://files.pythonhosted.org/packages/b4/40/a9837291310ee1ccc242ceb6ebfd9eb21539649f193a7c8c86ba15b98539/urllib3-1.25.7-py2.py3-none-any.whl (125kB)|████████████████████████████████| 133kB 6.4MB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading https://files.pythonhosted.org/packages/18/b0/8146a4f8dd402f60744fa380bc73ca47303cccf8b9190fd16a827281eac2/certifi-2019.9.11-py2.py3-none-any.whl (154kB)|████████████████████████████████| 163kB 3.3MB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133kB)|████████████████████████████████| 143kB 6.4MB/s
Collecting idna<2.9,>=2.5(from requests)
Downloading https://files.pythonhosted.org/packages/14/2c/cd551d81dbe15200be1cf41cd03869a46fe7226e7450af7a6545bfc474c9/idna-2.8-py2.py3-none-any.whl (58kB)|████████████████████████████████| 61kB 975kB/s
Installing collected packages: urllib3, certifi, idna, chardet, requests
WARNING: The script chardetect.exe is installed in'C:\Users\yjaquier\AppData\Roaming\Python\Python38\Scripts'which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed certifi-2019.9.11 chardet-3.0.4 idna-2.8 requests-2.22.0 urllib3-1.25.7
PS D:\> python -m pip install requests --user
Collecting requests
Downloading https://files.pythonhosted.org/packages/51/bd/23c926cd341ea6b7dd0b2a00aba99ae0f828be89d72b2190f27c11d4b7fb/requests-2.22.0-py2.py3-none-any.whl (57kB)
|████████████████████████████████| 61kB 563kB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests)
Downloading https://files.pythonhosted.org/packages/b4/40/a9837291310ee1ccc242ceb6ebfd9eb21539649f193a7c8c86ba15b98539/urllib3-1.25.7-py2.py3-none-any.whl (125kB)
|████████████████████████████████| 133kB 6.4MB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading https://files.pythonhosted.org/packages/18/b0/8146a4f8dd402f60744fa380bc73ca47303cccf8b9190fd16a827281eac2/certifi-2019.9.11-py2.py3-none-any.whl (154kB)
|████████████████████████████████| 163kB 3.3MB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133kB)
|████████████████████████████████| 143kB 6.4MB/s
Collecting idna<2.9,>=2.5 (from requests)
Downloading https://files.pythonhosted.org/packages/14/2c/cd551d81dbe15200be1cf41cd03869a46fe7226e7450af7a6545bfc474c9/idna-2.8-py2.py3-none-any.whl (58kB)
|████████████████████████████████| 61kB 975kB/s
Installing collected packages: urllib3, certifi, idna, chardet, requests
WARNING: The script chardetect.exe is installed in 'C:\Users\yjaquier\AppData\Roaming\Python\Python38\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed certifi-2019.9.11 chardet-3.0.4 idna-2.8 requests-2.22.0 urllib3-1.25.7
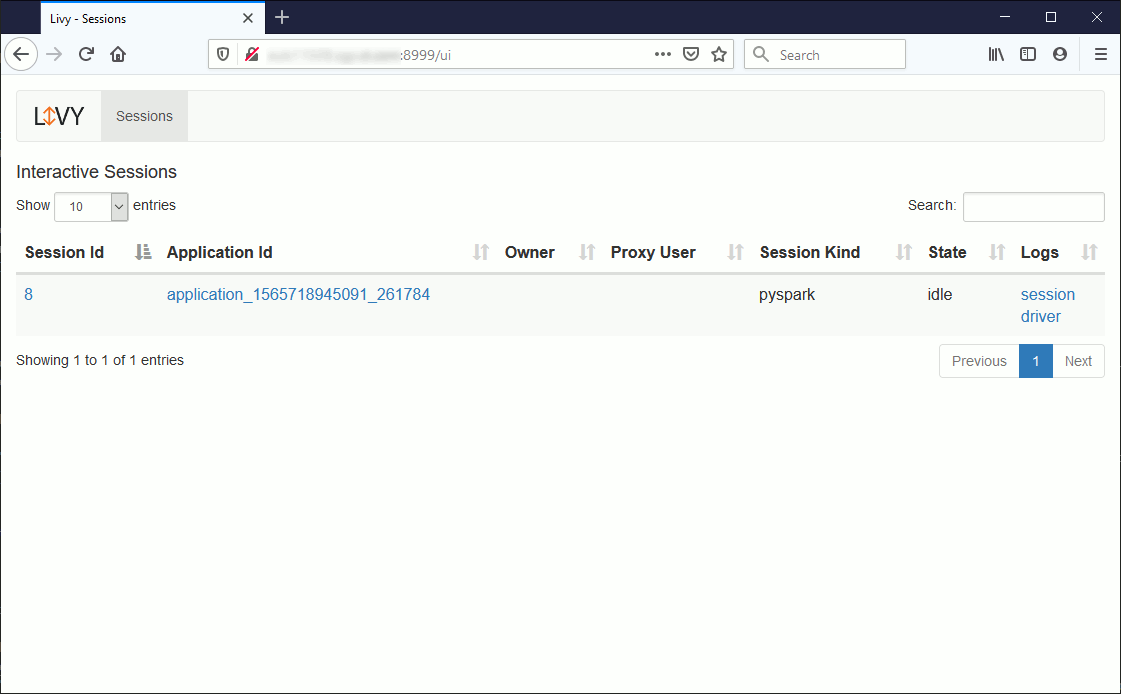
Python testing has been done using Python 3.8 installed on my Windows 10 machine. Obviously you can also see graphically what’s going on but as it is exactly the same as with curl I will not share again the output.