We have started to receive the below Ambari alerts:
Percent DataNodes With Available Space affected: [2], total: [5]
DataNode Storage Remaining Capacity:[4476139956751], Total Capacity:[77% Used, 19675609717760]
In itself the DataNode Storage alert is not super serious because, first, it is sent far in advance (> 75%) but it anyways tells you that you are reaching the storage limit of your cluster. One drawback we have seen is the impacted DataNodes are loosing contact with Ambari server and we are often obliged to restart the process.
On our small Hadoop cluster two nodes have more fill than the three others…
Should be easy to solve with below command:
[hdfs@clientnode ~]$ hdfs balancer
[hdfs@clientnode ~]$ hdfs balancer
Please note that the HDFS balance operation is a must in case you add or remove datanodes to your cluster. In upgrading number of disks of our few starting datanodes we suffered a lot from missing disk balancer command. We have been obliged to decommission and re-commission the datanodes. In latest HDP releases the command is now available:
We issued the HDFS balancer command with no options but after a very long run (almost a week) we end up with a still unbalanced situation. We even try to rerun the command but at the end the command completed very quickly (less than 2 seconds) but left us with two Datanodes still more filled than the three others.
[hdfs@clientnode ~]$ hdfs dfsadmin -report
Configured Capacity: 98378048588800(89.47 TB)
Present Capacity: 93358971611260(84.91 TB)
DFS Remaining: 31894899799432(29.01 TB)
DFS Used: 61464071811828(55.90 TB)
DFS Used%: 65.84%
Under replicated blocks: 24
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0-------------------------------------------------
Live datanodes (5):
Name: 192.168.1.3:50010(datanode03.domain.com)
Hostname: datanode03.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760(17.89 TB)
DFS Used: 11130853114413(10.12 TB)
Non DFS Used: 0(0 B)
DFS Remaining: 7534254091791(6.85 TB)
DFS Used%: 56.57%
DFS Remaining%: 38.29%
Configured Cache Capacity: 0(0 B)
Cache Used: 0(0 B)
Cache Remaining: 0(0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 25
Last contact: Tue Jan 08 12:51:44 CET 2019
Last Block Report: Tue Jan 08 06:52:34 CET 2019
Name: 192.168.1.2:50010(datanode02.domain.com)
Hostname: datanode02.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760(17.89 TB)
DFS Used: 11269739413291(10.25 TB)
Non DFS Used: 0(0 B)
DFS Remaining: 7403207769673(6.73 TB)
DFS Used%: 57.28%
DFS Remaining%: 37.63%
Configured Cache Capacity: 0(0 B)
Cache Used: 0(0 B)
Cache Remaining: 0(0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 33
Last contact: Tue Jan 08 12:51:44 CET 2019
Last Block Report: Tue Jan 08 11:30:59 CET 2019
Name: 192.168.1.4:50010(datanode04.domain.com)
Hostname: datanode04.domain.com
Rack: /AH/27
Decommission Status : Normal
Configured Capacity: 19675609717760(17.89 TB)
DFS Used: 14226431394146(12.94 TB)
Non DFS Used: 0(0 B)
DFS Remaining: 4448006323316(4.05 TB)
DFS Used%: 72.30%
DFS Remaining%: 22.61%
Configured Cache Capacity: 0(0 B)
Cache Used: 0(0 B)
Cache Remaining: 0(0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 14
Last contact: Tue Jan 08 12:51:43 CET 2019
Last Block Report: Tue Jan 08 12:12:55 CET 2019
Name: 192.168.1.1:50010(datanode01.domain.com)
Hostname: datanode01.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760(17.89 TB)
DFS Used: 10638187881052(9.68 TB)
Non DFS Used: 0(0 B)
DFS Remaining: 8035048514823(7.31 TB)
DFS Used%: 54.07%
DFS Remaining%: 40.84%
Configured Cache Capacity: 0(0 B)
Cache Used: 0(0 B)
Cache Remaining: 0(0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 20
Last contact: Tue Jan 08 12:51:43 CET 2019
Last Block Report: Tue Jan 08 09:38:50 CET 2019
Name: 192.168.1.5:50010(datanode05.domain.com)
Hostname: datanode05.domain.com
Rack: /AH/27
Decommission Status : Normal
Configured Capacity: 19675609717760(17.89 TB)
DFS Used: 14198860008926(12.91 TB)
Non DFS Used: 0(0 B)
DFS Remaining: 4474383099829(4.07 TB)
DFS Used%: 72.16%
DFS Remaining%: 22.74%
Configured Cache Capacity: 0(0 B)
Cache Used: 0(0 B)
Cache Remaining: 0(0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 29
Last contact: Tue Jan 08 12:51:45 CET 2019
Last Block Report: Tue Jan 08 11:50:32 CET 2019
[hdfs@clientnode ~]$ hdfs dfsadmin -report
Configured Capacity: 98378048588800 (89.47 TB)
Present Capacity: 93358971611260 (84.91 TB)
DFS Remaining: 31894899799432 (29.01 TB)
DFS Used: 61464071811828 (55.90 TB)
DFS Used%: 65.84%
Under replicated blocks: 24
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0-------------------------------------------------
Live datanodes (5):Name: 192.168.1.3:50010 (datanode03.domain.com)
Hostname: datanode03.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760 (17.89 TB)
DFS Used: 11130853114413 (10.12 TB)
Non DFS Used: 0 (0 B)
DFS Remaining: 7534254091791 (6.85 TB)
DFS Used%: 56.57%
DFS Remaining%: 38.29%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 25
Last contact: Tue Jan 08 12:51:44 CET 2019
Last Block Report: Tue Jan 08 06:52:34 CET 2019Name: 192.168.1.2:50010 (datanode02.domain.com)
Hostname: datanode02.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760 (17.89 TB)
DFS Used: 11269739413291 (10.25 TB)
Non DFS Used: 0 (0 B)
DFS Remaining: 7403207769673 (6.73 TB)
DFS Used%: 57.28%
DFS Remaining%: 37.63%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 33
Last contact: Tue Jan 08 12:51:44 CET 2019
Last Block Report: Tue Jan 08 11:30:59 CET 2019Name: 192.168.1.4:50010 (datanode04.domain.com)
Hostname: datanode04.domain.com
Rack: /AH/27
Decommission Status : Normal
Configured Capacity: 19675609717760 (17.89 TB)
DFS Used: 14226431394146 (12.94 TB)
Non DFS Used: 0 (0 B)
DFS Remaining: 4448006323316 (4.05 TB)
DFS Used%: 72.30%
DFS Remaining%: 22.61%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 14
Last contact: Tue Jan 08 12:51:43 CET 2019
Last Block Report: Tue Jan 08 12:12:55 CET 2019Name: 192.168.1.1:50010 (datanode01.domain.com)
Hostname: datanode01.domain.com
Rack: /AH/26
Decommission Status : Normal
Configured Capacity: 19675609717760 (17.89 TB)
DFS Used: 10638187881052 (9.68 TB)
Non DFS Used: 0 (0 B)
DFS Remaining: 8035048514823 (7.31 TB)
DFS Used%: 54.07%
DFS Remaining%: 40.84%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 20
Last contact: Tue Jan 08 12:51:43 CET 2019
Last Block Report: Tue Jan 08 09:38:50 CET 2019Name: 192.168.1.5:50010 (datanode05.domain.com)
Hostname: datanode05.domain.com
Rack: /AH/27
Decommission Status : Normal
Configured Capacity: 19675609717760 (17.89 TB)
DFS Used: 14198860008926 (12.91 TB)
Non DFS Used: 0 (0 B)
DFS Remaining: 4474383099829 (4.07 TB)
DFS Used%: 72.16%
DFS Remaining%: 22.74%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 29
Last contact: Tue Jan 08 12:51:45 CET 2019
Last Block Report: Tue Jan 08 11:50:32 CET 2019
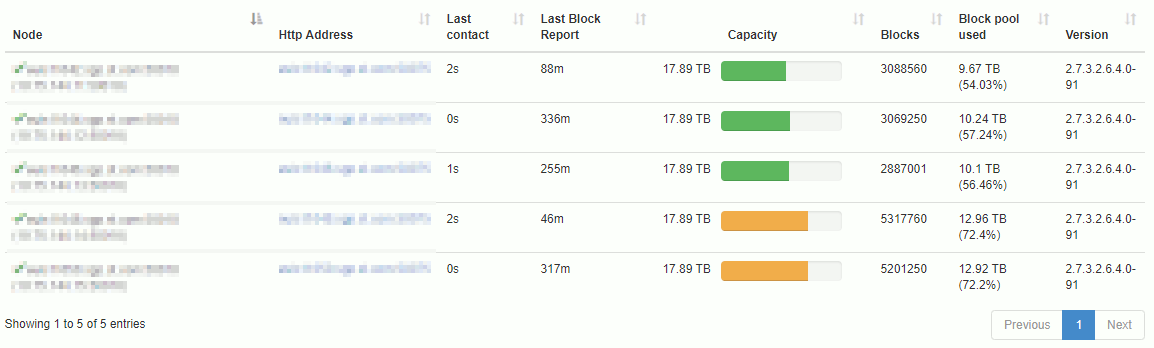
From NameNode UI it gives the clean graphical picture:
hdfs_balancer01
Two datanodes are still more filled than the three others.
Then digging inside HDFS balancer official documentation we found two interesting parameters that are -source and -threshold.
hdfs balancer
[-policy <policy>][-threshold <threshold>][-exclude [-f <hosts-file>|<comma-separated list of hosts>]][-include [-f <hosts-file>|<comma-separated list of hosts>]][-source [-f <hosts-file>|<comma-separated list of hosts>]][-blockpools <comma-separated list of blockpool ids>][-idleiterations <idleiterations>][-runDuringUpgrade]
hdfs balancer
[-policy <policy>]
[-threshold <threshold>]
[-exclude [-f <hosts-file> | <comma-separated list of hosts>]]
[-include [-f <hosts-file> | <comma-separated list of hosts>]]
[-source [-f <hosts-file> | <comma-separated list of hosts>]]
[-blockpools <comma-separated list of blockpool ids>]
[-idleiterations <idleiterations>]
[-runDuringUpgrade]
[hdfs@server ~]$ hdfs balancer -help
WARNING: HADOOP_BALANCER_OPTS has been replaced by HDFS_BALANCER_OPTS. Using value of HADOOP_BALANCER_OPTS.
Usage: hdfs balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file>|<comma-separated list of hosts>]] Excludes the specified datanodes.
[-include [-f <hosts-file>|<comma-separated list of hosts>]] Includes only the specified datanodes.
[-source [-f <hosts-file>|<comma-separated list of hosts>]] Pick only the specified datanodes assource nodes.
[-blockpools <comma-separated list of blockpool ids>] The balancer will only run on blockpools included in this list.
[-idleiterations <idleiterations>] Number of consecutive idle iterations (-1for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.
Generic options supported are:
-conf<configuration file> specify an application configuration file-D<property=value> define a value for a given property
-fs<file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt<local|resourcemanager:port> specify a ResourceManager
-files<file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars<jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives<archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command[genericOptions][commandOptions]
[hdfs@server ~]$ hdfs balancer -help
WARNING: HADOOP_BALANCER_OPTS has been replaced by HDFS_BALANCER_OPTS. Using value of HADOOP_BALANCER_OPTS.
Usage: hdfs balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | <comma-separated list of hosts>]] Excludes the specified datanodes.
[-include [-f <hosts-file> | <comma-separated list of hosts>]] Includes only the specified datanodes.
[-source [-f <hosts-file> | <comma-separated list of hosts>]] Pick only the specified datanodes as source nodes.
[-blockpools <comma-separated list of blockpool ids>] The balancer will only run on blockpools included in this list.
[-idleiterations <idleiterations>] Number of consecutive idle iterations (-1 for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machinesThe general command line syntax is:
command [genericOptions] [commandOptions]
-source is easily understandable with below example from official documentation (that I prefer to put it with the acquisition of Hortonworks by Cloudera):
The following table shows an example, where the average utilization is 25% so that D2 is within the 10% threshold. It is unnecessary to move any blocks from or to D2. Without specifying the source nodes, HDFS Balancer first moves blocks from D2 to D3, D4 and D5, since they are under the same rack, and then moves blocks from D1 to D2, D3, D4 and D5.
By specifying D1 as the source node, HDFS Balancer directly moves blocks from D1 to D3, D4 and D5.
Datanodes (with the same capacity)
Utilization
Rack
D1
95%
A
D2
30%
B
D3, D4, and D5
0%
B
This is also explained in Storage group pairing policy:
The HDFS Balancer selects over-utilized or above-average storage as source storage, and under-utilized or below-average storage as target storage. It pairs a source storage group with a target storage group (source → target) in a priority order depending on whether or not the source and the target storage reside in the same rack.
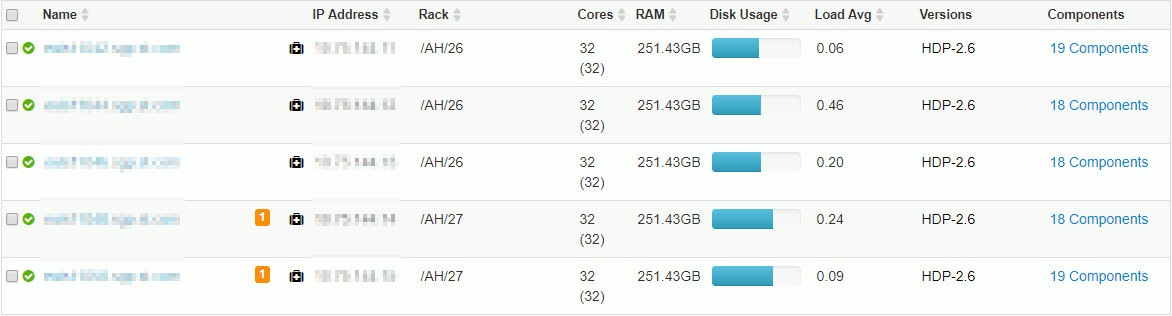
And this rack awareness story is exactly what we have as displayed in server list of Ambari:
hdfs_balancer02
-threshold is also an interesting parameter to be more strict with nodes above or below the average…
But again it did not change anything special and they have been both executed very fast…
So clearly in our case the rack awareness story is a blocking factor. One mistake we have done is to have an odd number of datanodes and this 2-3 configuration in two racks is clearly not a good idea. Of course we could remove the rack awareness configuration to have a well balanced cluster but we do not want to loose the extra high availibilty we have with it. SO only available plan is to buy new databases or add more disks to our existing nodes as we have less disks than threads…