Table of contents
Preamble
Spark Structured Streaming is a near real time processing engine using Spark APIs. The typical example is a silver or gold table feeding in the medallion architecture.
While testing the feature I have done two examples. One based on the Delta Live Table (Auto Loader) and another one based on a simple bronze table where we perform near real time a simple aggregation.
I have used Databricks Runtime 10.4 on Azure but should work with any runtime. The screenshots may also have changed at the time you see them as Databricks web interface is frequently changing…
Spark Structured Streaming first test case
For this first test case I plan to use below bronze table:
%SQL DROP TABLE IF EXISTS sales; CREATE TABLE IF NOT EXISTS sales ( customer string, sales_date DATE, sales_value DOUBLE ) USING delta comment "The sales table" tblproperties ("quality" = "bronze"); INSERT INTO sales VALUES('Peugeot','2023-01-02',1000); INSERT INTO sales VALUES('Peugeot','2023-01-05',100); INSERT INTO sales VALUES('Renault','2023-01-03',900); |
I create a Spark Structure Streaming object with:
from pyspark.sql import functions as F from pyspark.sql.types import StructType,StructField, StringType, IntegerType, DoubleType # As my source is Delta I cannot specify the schema jsonSchema = StructType([ StructField("customer", StringType(), True), StructField("month", IntegerType(), True), StructField("sales_value", DoubleType(), True) ]) sales_aggregation_per_month_stream=spark.readStream\ .format("delta")\ .load("dbfs:/user/hive/warehouse/sales")\ .select("customer", "sales_date", "sales_value")\ .withColumn("month_sales_date", F.month(F.col("sales_date")))\ .drop(F.col("sales_date"))\ .groupBy(F.col("customer"),F.col("month_sales_date"))\ .sum("sales_value")\ .writeStream\ .format("memory")\ .queryName("sales_aggregation_per_month_stream")\ .outputMode("complete")\ .trigger(processingTime='60 seconds')\ .start() |
What did I do in this long command ?:
- readStream.format(“delta”).load(“dbfs:/user/hive/warehouse/sales”): I read the delta directory of my source table
- select(“customer”, “sales_date”, “sales_value”).withColumn(“month_sales_date”, F.month(F.col(“sales_date”))).drop(F.col(“sales_date”)).groupBy(F.col(“customer”),F.col(“month_sales_date”)).sum(“sales_value”): Aggregation to compute sales per month
- writeStream.format(“memory”): I write the stream in a memory output sink, use memory for testing purpose as you cannot read it from another session
- queryName(“sales_aggregation_per_month_stream”): the name of the object that will be created and accessible with SQL
- outputMode(“complete”): the output refresh mode
- trigger(processingTime=’60 seconds’).start(): I trigger a refresh every 60 seconds and I finally start the streaming
Once you execute it you start to have a graphical representation of processed rows:
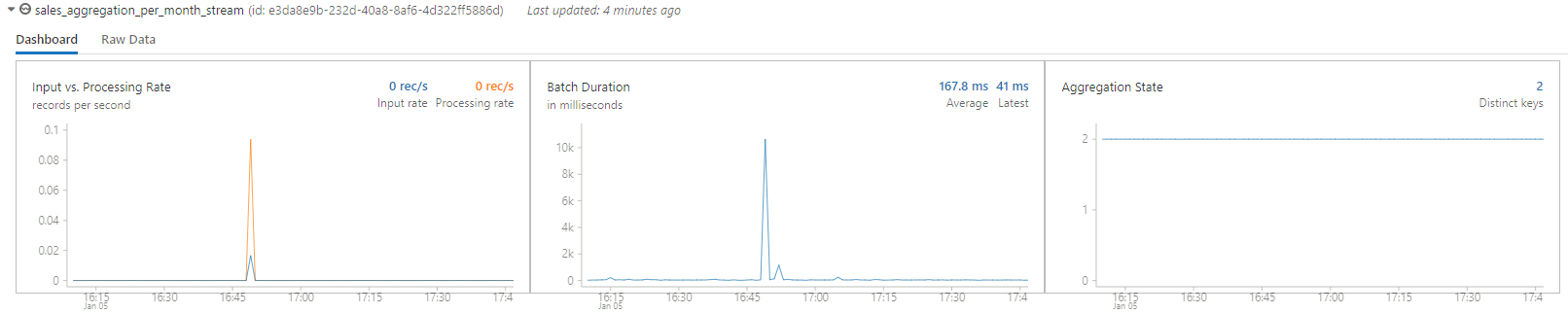
Then to play you can start to insert rows in source table with something like:
%SQL INSERT INTO sales VALUES('Peugeot','2023-01-15',100); |
The aggregation memory table is updated automatically by the stream:

It would have been more satisfactory to use update as the outputMode but with memory output sink the update option with no watermark (withWatermark()) provide a strange (expected ?) output:
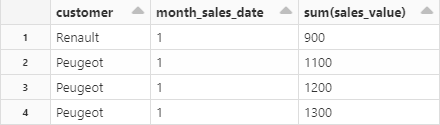
While it is not possible with a delta table as source:
AnalysisException: Data source com.databricks.sql.transaction.tahoe.sources.DeltaDataSource does not support Update output mode
This watermark keyword allow aggregation to work in append mode however the aggregation must be on event-time which is not my case… Looks like only the complete mode makes sense while working with aggregations…
Spark Structured Streaming second test case
For the second test case I will have more or less the same data source but this time with csv files.
dbutils.fs.rm("/FileStore/yjaquier/sales/one.csv") dbutils.fs.put("/FileStore/yjaquier/sales/one.csv","customer,sales_date,sales_value\r\nPeugeot,2023-01-02,1000\r\nPeugeot,2023-01-05,100\r\nRenault,2023-01-03,900") dbutils.fs.ls("/FileStore/yjaquier/sales") |
The Spark Structured Streaming script is now of the form:
from pyspark.sql import functions as F from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, DateType jsonSchema = StructType([ StructField("customer", StringType(), True), StructField("sales_date", DateType(), True), StructField("sales_value", DoubleType(), True) ]) checkpoint_dir="/tmp/yjaquier/checkpoint" sales_aggregation_per_month_stream_dir="/mnt/yjaquier/sales_aggregation_per_month_stream" csv_source_dir="/FileStore/yjaquier/sales" dbutils.fs.rm(checkpoint_dir,True) dbutils.fs.rm(sales_aggregation_per_month_stream_dir,True) sales_aggregation_per_month_stream=spark.readStream\ .format("csv")\ .option("header", True)\ .schema(jsonSchema)\ .load(csv_source_dir)\ .select("customer", "sales_date", "sales_value")\ .withColumn("month_sales_date", F.month(F.col("sales_date")))\ .drop(F.col("sales_date"))\ .groupBy(F.col("customer"),F.col("month_sales_date"))\ .sum("sales_value")\ .withColumnRenamed("sum(sales_value)","sales_value")\ .writeStream\ .format("delta")\ .option("path", sales_aggregation_per_month_stream_dir)\ .queryName("sales_aggregation_per_month_stream")\ .outputMode("complete")\ .trigger(processingTime='60 seconds')\ .option("checkpointLocation", checkpoint_dir)\ .start() |
And what’s available for all:
SELECT * FROM delta.`/mnt/yjaquier/sales_aggregation_per_month_stream` SELECT * FROM sales_aggregation_per_month_stream |
But I was still not able to use update mode. Watermarking is apparently mandatory to use it with aggregation (to be tested further):
AnalysisException: Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark;
Spark Structured Streaming third test case to prepare further ingestion
What was also not 100% satisfactory in two above streaming examples we have seen is the missing capability to be able to know what was recently added to the streaming resulting table. In incremental processes being able to identify the small part that has been recently added is highly important to work small step by small step.
Databricks has this nice feature call Change Data Feed (CDF) that I will test in a further post but with Spark Structured Streaming there is an interesting feature available with Foreach and ForeachBatch. Foreach allows to apply custom logic to each new row and ForeachBatch allows to apply custom logic to each batch.
I start with the same initial table I used in first test case and use this streaming Python script. My script for each batch add epoch_id as batch_id column and write the result in delta mode in directory I have chosen:
from pyspark.sql import functions as F sales_incremental_stream_dir="/mnt/yjaquier/sales_incremental_stream" dbutils.fs.rm(sales_incremental_stream_dir,True) def foreach_batch_function(df, epoch_id): df.withColumn('batch_id',F.lit(epoch_id)).write.mode("append").format("delta").save(sales_incremental_stream_dir) sales_incremental_stream=spark.readStream\ .format("delta")\ .load("dbfs:/user/hive/warehouse/sales")\ .writeStream\ .foreachBatch(foreach_batch_function)\ .outputMode("append")\ .trigger(processingTime='60 seconds')\ .start() |
If I select using Databricks client on my desktop we see the additional batch_id column:
>>> spark.sql("select * from delta.`/mnt/yjaquier/sales_incremental_stream`").show() +--------+----------+-----------+--------+ |customer|sales_date|sales_value|batch_id| +--------+----------+-----------+--------+ | Peugeot|2023-01-02| 1000.0| 0| | Peugeot|2023-01-05| 100.0| 0| | Renault|2023-01-03| 900.0| 0| +--------+----------+-----------+--------+ |
Remark:
If you don’t want to select directly fro the delta folder you can create a table with:
CREATE TABLE IF NOT EXISTS sales_incremental_stream USING delta location "/mnt/yjaquier/sales_aggregation_per_month_stream" |
Then I add a new row using a SQL command and when the streaming is triggered I get the new run with an incremented batch_id:
>>> spark.sql("select * from delta.`/mnt/yjaquier/sales_incremental_stream`").show() +--------+----------+-----------+--------+ |customer|sales_date|sales_value|batch_id| +--------+----------+-----------+--------+ | Peugeot|2023-01-02| 1000.0| 0| | Peugeot|2023-01-05| 100.0| 0| | Peugeot|2023-01-15| 100.0| 1| | Renault|2023-01-03| 900.0| 0| +--------+----------+-----------+--------+ |
Finally using the new batch_id column you would be able to plug incremental processes on this streaming table…
References
- Structured Streaming Programming Guide
- What is Apache Spark Structured Streaming?
- Getting Started with Apache Spark on Databricks
- Feature Deep Dive: Watermarking in Apache Spark Structured Streaming
- Streaming in Production: Collected Best Practices
- Streaming in Production: Collected Best Practices, Part 2





