How to configure Hive Warehouse Connector (HWC) integration in Zeppelin Notebook ? Since we upgraded to Hortonworks Data Platform (HDP) 3.1.4 we have been obliged to fight everywhere to integrate the new way of working in Spark with HWC. The connector in itself is not very complex to use, it requires only a small modification of your Spark code (Scala or Python). What’s complex is its integration in the existing tools as well as how, now, to run Pyspark and Spark-shell (Scala) to integrate it in your environment.
On top of this, as clearly stated in the official documentation, you need HWC and LLAP (Live Long And Process or Low-Latency Analytical processing) to read Hive managed tables from Spark. Which is one of the first operation you will do in most of your Spark scripts. So in Ambari activate and configure it (number of nodes, memory, concurrent queries):
hwc01
HWC on the command line
Before jumping to Zeppelin let’s quickly see how you know execute Spark on the command line with HWC.
You should have already configured Spark below parameters (as well as reverting back hive.fetch.task.conversion value see my other article on this)
Note: Notice the F in uppercase in spark.submit.pyFiles, I have lost half a day because some blog articles on internet have misspelled it.
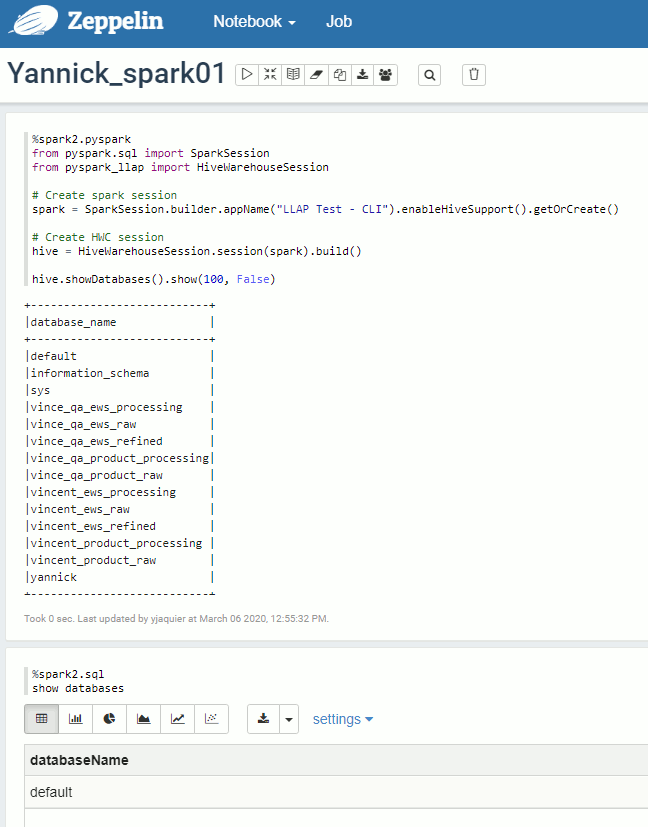
Save and restart the interpreter and it you test below code in a new Notebook you should get a result (and not the default databases name):
hwc02
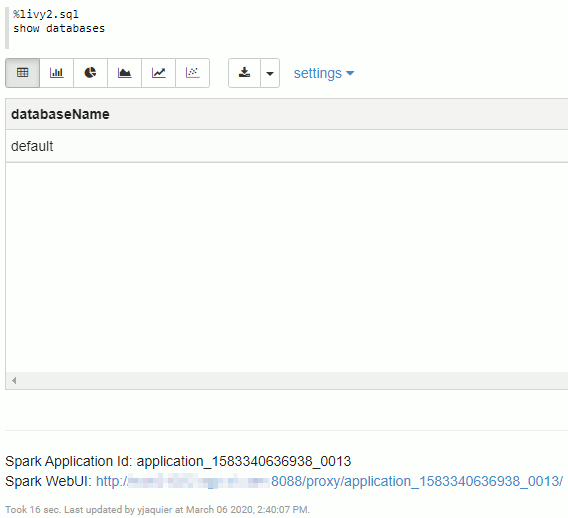
Remark: As you can see above the %spark2.sql option of the interpreter is not configured to use HWC. So far I have not found how to overcome this. This could be an issue because this interpreter option is a nice feature to make graphs from direct SQL commands…
It works also well in Scala:
hwc03
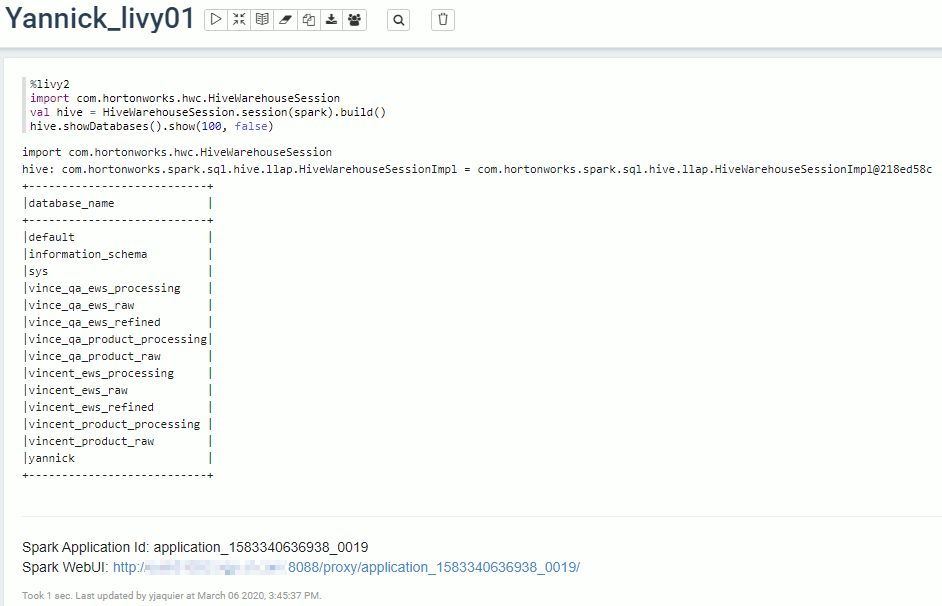
Zeppelin Livy2 interpreter configuration
You might wonder why configuring Livy2 interpreter as the first one is working fine. Well I had to configure it to for the JupyterHub Sparkmagic configuration that we will see in another blog post so here it is…
To make Livy2 Zeppelin interpreter working with HWC you need to add two parameters to its configuration:
Note: The second parameter was just a good guess from the Spark2 interpreter setting. Also note the file:// to instruct interpreter to look on local file system and not on HDFS.
Also ensure the Livy url is well setup to the server (and port) of you Livy process:
org.apache.zeppelin.livy.LivyException: Error with 400 StatusCode: "requirement failed: Local path /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-1.0.0.3.1.4.0-315.jar cannot be added to user sessions."
at org.apache.zeppelin.livy.BaseLivyInterpreter.callRestAPI(BaseLivyInterpreter.java:755)
at org.apache.zeppelin.livy.BaseLivyInterpreter.createSession(BaseLivyInterpreter.java:337)
at org.apache.zeppelin.livy.BaseLivyInterpreter.initLivySession(BaseLivyInterpreter.java:209)
at org.apache.zeppelin.livy.LivySharedInterpreter.open(LivySharedInterpreter.java:59)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:69)
at org.apache.zeppelin.livy.BaseLivyInterpreter.getLivySharedInterpreter(BaseLivyInterpreter.java:190)
at org.apache.zeppelin.livy.BaseLivyInterpreter.open(BaseLivyInterpreter.java:163)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:69)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:617)
at org.apache.zeppelin.scheduler.Job.run(Job.java:188)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:140)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
org.apache.zeppelin.livy.LivyException: Error with 400 StatusCode: "requirement failed: Local path /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-1.0.0.3.1.4.0-315.jar cannot be added to user sessions."
at org.apache.zeppelin.livy.BaseLivyInterpreter.callRestAPI(BaseLivyInterpreter.java:755)
at org.apache.zeppelin.livy.BaseLivyInterpreter.createSession(BaseLivyInterpreter.java:337)
at org.apache.zeppelin.livy.BaseLivyInterpreter.initLivySession(BaseLivyInterpreter.java:209)
at org.apache.zeppelin.livy.LivySharedInterpreter.open(LivySharedInterpreter.java:59)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:69)
at org.apache.zeppelin.livy.BaseLivyInterpreter.getLivySharedInterpreter(BaseLivyInterpreter.java:190)
at org.apache.zeppelin.livy.BaseLivyInterpreter.open(BaseLivyInterpreter.java:163)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:69)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:617)
at org.apache.zeppelin.scheduler.Job.run(Job.java:188)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:140)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
To solve it add below configuration to your Livy2 server (Custom livy2-conf in Ambari):