Table of contents
Preamble
In-Memory OLTP is a feature of SQL Server (Standard and Enterprise) and Azure SQL than aim to optimize performance of transaction processing or data ingestion.
Using In-Memory OLTP in the case of data ingestion is a subject that has particular interest to me as we have plenty of use cases where we load data from Databricks to Azure SQL to build reporting application and have better response time thanks to RDBMS advanced features.
Till now I have seen plenty of code using the session and global temporary tables (#tabname and ##tabname) and this feature would be a nice replacement.
First I had the discomfiture to discover that the feature is available only in Business Critical Azure SQL tier:
Msg 40536, Level 16, State 2, Line 1 'MEMORY_OPTIMIZED tables' is not supported in this service tier of the database. See Books Online for more details on feature support in different service tiers of Windows Azure SQL Database. |
Which is a really unfortunate as you normally have your development and QA databases in General Purpose tier and only the production database in Business Critical tier…
To know if your database is compatible, On Azure SQL the server could be compatible while the database is not (General Purpose tier):
print 'Database Properties: '+choose(cast(databasepropertyex(db_name(), 'IsXTPSupported') as int)+1,'Not available','Available')+CHAR(10)+ 'Server Properties: '+choose(cast(serverproperty(N'IsXTPSupported') as int)+1,'Not available','Available'); |
On premise my test server is quite powerful with 12 cores and 64GB of memory running SQL Server 2019 and Red Hat Enterprise Linux Server release 7.9 (Maipo) and I have allocated 4GB of memory to SQL Server:
[mssql@server1 ~]$ /opt/mssql/bin/mssql-conf get memory memorylimitmb memorylimitmb : 4096 [mssql@server1 ~]$ grep memory /var/opt/mssql/mssql.conf [memory] memorylimitmb = 4096 |
For better display of queries in this blog post I have installed mssql-cli that clearly outclass sqlcmd legacy tool. installation is as simple as and connection is exactly the same:
[root@server1 ~]# yum install mssql-cli [root@server1 mssql]# su - mssql [mssql@server1 ~]$ mssql-cli -U sa -S server1.domain.com,1443 Password: master> |
In-Memory OLTP preparation
I create a test database with:
drop database test create database test containment = none on primary (name = N'test_data', filename = N'/mssql/data/test.mdf' , size = 5MB , maxsize = 100MB , filegrowth = 5MB) log on (name = N'test_log', filename = N'/mssql/log/test_log.ldf' , size = 5MB , maxsize = 100MB , filegrowth = 5MB) use test |
Then I create a dedicated filegroup for the memory data. Even with In-Memory OLTP the schema is durable (so on disk) and you have the option to make the data durable with DURABILITY = SCHEMA_AND_DATA. I specify the filename without mdf extension as it will be a directory on my Linux box:
alter database test add filegroup memory_optimized_data contains memory_optimized_data alter database test add file (name='memory_optimized_data', filename='/mssql/data/memory_optimized_data') to filegroup memory_optimized_data |
Which end up as:
[mssql@server1 ~]$ ll -d /mssql/data/memory_optimized_data drwxrwx--- 4 mssql mssql 96 Mar 23 12:20 /mssql/data/memory_optimized_data |
test> select a.name,a.type_desc,b.name,b.physical_name ..... from sys.filegroups a, sys.database_files b ..... where a.data_space_id=b.data_space_id ..... Time: 0.452s +-----------------------+---------------------------------+-----------------------+-----------------------------------+ | name | type_desc | name | physical_name | |-----------------------+---------------------------------+-----------------------+-----------------------------------| | PRIMARY | ROWS_FILEGROUP | test_data | /mssql/data/test.mdf | | memory_optimized_data | MEMORY_OPTIMIZED_DATA_FILEGROUP | memory_optimized_data | /mssql/data/memory_optimized_data | +-----------------------+---------------------------------+-----------------------+-----------------------------------+ (2 rows affected) |
In-Memory OLTP testing
Clustered indexes are not support on memory optimized tables:
Msg 12317, Level 16, State 76, Line 48 Clustered indexes, which are the default for primary keys, are not supported with memory optimized tables. Specify a NONCLUSTERED index instead. |
So did:
create table memory01 ( id int not null primary key nonclustered, descr varchar(50) not null) with (memory_optimized=on, durability = schema_only) |
I create the traditional SQL counterpart table:
create table sql01 ( id int not null primary key nonclustered, descr varchar(50) not null) |
And the session temporary table:
create table #temp01 ( id int not null primary key nonclustered, descr varchar(50) not null) |
Then I have the below insert script that must be executed with sqlcmd (or SSMS) as not working with msql-cli (switch table name between sql01 and memeory01 and replace truncate table sql01 by delete from memory01 as it is not possible to truncate an in memory optimized table):
set statistics time off; set nocount on; declare @descr varchar(50) = N'abcdefghijklmnopqrstuvwxyz'; declare @i int = 1; declare @row_count int = 100000; declare @timems int; declare @starttime datetime2 = sysdatetime(); set @i = 1; begin transaction; while @i <= @row_count begin insert into sql01 values (@i, @descr); set @i += 1; end commit; set @timems = datediff(ms, @starttime, sysdatetime()); print 'Disk-based table and interpreted Transact-SQL: ' + cast(@timems AS VARCHAR(10)) + ' ms'; truncate table sql01; |
After 6-7 runs of each process I got the below average (it is obviously not a benchmark). But we can see that it is around two times faster with In-Memory OLTP:
| sql01 | temp01 | memory01 |
|---|---|---|
| 1500 ms | 1200 ms | 600ms |
In-Memory OLTP to durable tables
Once you have quickly loaded your figures in a memory tables the next step is obviously to make those newly inserted rows durable by inserting them into a traditional table.
In the Microsoft literature they propose two way to do it.
INSERT INTO disk_based_table SELECT FROM memory_optimized_table
The process would be, in my case, something like:
begin transaction insert into sql01 (id, descr) select id, descr from memory01 with (snapshot) delete from memory01 with (snapshot) commit |
Microsoft suggest to activate Accelerated Database Recovery (ADR) when using the snapshot isolation and row versioning. Feature that is activated by default in Azure SQL Database, Azure SQL Managed Instance and Azure Synapse SQL.
To activate ADR on my test database:
alter database test add filegroup adr; alter database test add file (name='adr', filename='/mssql/data/adr.mdf', size = 5MB , maxsize = 100MB , filegrowth = 5MB) to filegroup adr; alter database test set accelerated_database_recovery = on (persistent_version_store_filegroup = adr); |
To get this under SSMS:
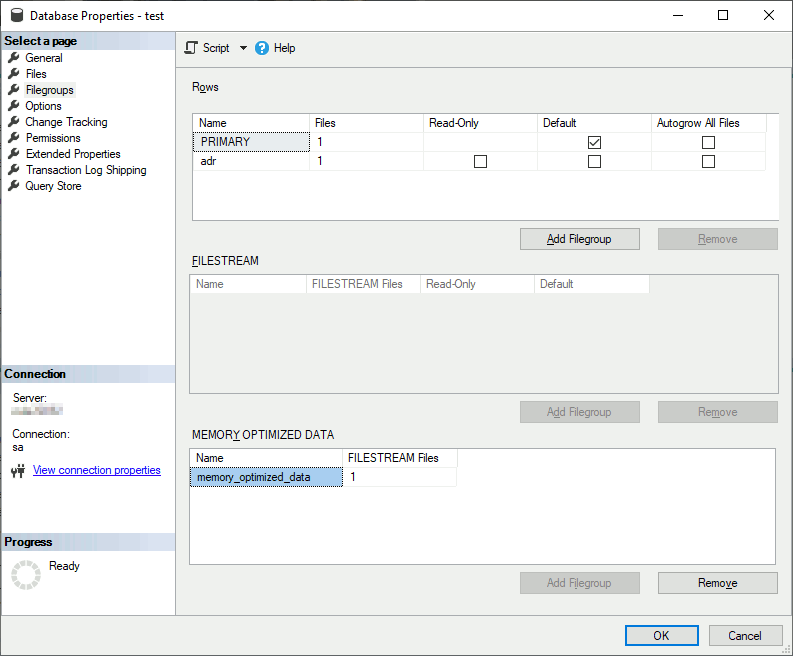
Temporal memory-optimized table
Then I thought that those temporal memory-optimized table wuld be a super idea. Means that the active part of the data in in a in-memory OLTP table (DURABILITY = SCHEMA_AND_DATA) and a background process would flush this to an historical traditional table.
My small trial. We need first an historical table:
create table test01_history ( id int not null, descr varchar(50), validfrom datetime2 not null, validto datetime2 not null ); |
The in-memory OLTP table. The validfrom and validto columns are mandatory and they must be self generated:
create table test01 ( id int primary key nonclustered, descr varchar(50), validfrom datetime2 generated always as row start hidden not null, validto datetime2 generated always as row end hidden not null, period for system_time (validfrom, validto) ) with (memory_optimized=on, durability = schema_and_data, system_versioning = on (history_table=dbo.test01_history, data_consistency_check = on)); |
Under SSMS the association between history and current table is clear:
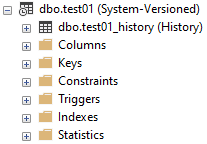
Overall it works well:
test> insert into test01 values(1,'One'); Time: 0.251s (1 row affected) test> select * from test01; Time: 0.502s +------+---------+ | id | descr | |------+---------| | 1 | One | +------+---------+ (1 row affected) test> delete from test01; Time: 0.251s (1 row affected) test> select * from test01; Time: 0.401s (0 rows affected) test> select * from test01_history; Time: 0.552s +------+---------+-----------------------------+-----------------------------+ | id | descr | validfrom | validto | |------+---------+-----------------------------+-----------------------------| | 1 | One | 2023-03-24 14:12:43.6143185 | 2023-03-24 14:13:31.9214052 | +------+---------+-----------------------------+-----------------------------+ (1 row affected) test> |
But I rate it a bit complex to insert in a data ingestion flow or maybe I have not really seen the full power of this feature…
Issues encountered
Apparently there is an on-going bug if your database contains in memory optimized tables. if the transaction log is full you are almost blocked:
Msg 9002, Level 17, State 16, Line 13 The transaction log for database 'test' is full due to 'XTP_CHECKPOINT'. |
To solve it I did increase the transaction log and then I truncated it (in a production environment make a backup instead):
alter database test set recovery simple; dbcc shrinkfile ('test_log', 5120); alter database test set recovery full dbcc sqlperf (logspace); --backup log test to disk = N'/mssql/backup/test.bak' with noformat, init, name = N'tlog backup', skip, norewind, nounload, stats = 10 |
References
- In-Memory OLTP overview and usage scenarios
- Demonstration: Performance Improvement of In-Memory OLTP
- System-Versioned Temporal Tables with Memory-Optimized Tables
- Temporal tables
- The Memory Optimized Filegroup
- Optimize performance by using in-memory technologies in Azure SQL Database and Azure SQL Managed Instance





