Table of contents
Preamble
I have already tested Database Migration Assistant for Unicode (DMU) but this time I have been contacted by a teammate to understand on how we could move a WE8ISO8859P1 database to Unicode (AL32UTF8). I am not (re)entering in the story of why migrating to Unicode in a worldwide organization is a must as it is already well explained in DMU official documentation in chapter Why Unicode is the Right Choice.
Then why all the burden around the change of the character set of an Oracle Database ? Well because you CANNOT simply change the value in props$ and that you have to convert the already existing figures inside the database and mainly also because AL32UTF8 is not a fixed byte length character set:
UTF8/AL32UTF8 is a varying width characterset, which means that the code for 1 character can be 1 , 2 , 3 or 4 bytes long. This is a big difference with character sets like WE8ISO8559P1 or WE8MSWIN1252 where 1 character is always 1 byte.
In other words the database needs to be converted. In the past you had tools like csscan or expdp/impdp but now Oracle is clearly stating:
From Oracle 12c onwards, the DMU is the only tool available to migrate to Unicode.
Display the current NLS settings of your database with:
SQL> SET pages 1000 SQL> SELECT * FROM nls_database_parameters; PARAMETER VALUE __________________________ _______________________________ NLS_RDBMS_VERSION 21.0.0.0.0 NLS_NCHAR_CONV_EXCP FALSE NLS_LENGTH_SEMANTICS BYTE NLS_COMP BINARY NLS_DUAL_CURRENCY $ NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM NLS_TIME_FORMAT HH.MI.SSXFF AM NLS_SORT BINARY NLS_DATE_LANGUAGE AMERICAN NLS_DATE_FORMAT DD-MON-RR NLS_CALENDAR GREGORIAN NLS_NUMERIC_CHARACTERS ., NLS_NCHAR_CHARACTERSET AL16UTF16 NLS_CHARACTERSET AL32UTF8 NLS_ISO_CURRENCY AMERICA NLS_CURRENCY $ NLS_TERRITORY AMERICA NLS_LANGUAGE AMERICAN 20 ROWS selected. |
Another important point to understand is the value of NLS_LENGTH_SEMANTICS (BYTE | CHAR) which determine the default length semantics used for VARCHAR2 and CHAR columns. For example when you do something like:
CREATE TABLE test_table( col1 VARCHAR2(10) ); |
You column is 20 bytes long and not 20 characters long. In other word, in the case of AL32UTF8 (Unicode), when you store 4 bytes characters in this column then you will be able to store only 10/4 characters. Example with Chinese characters (that are not always 4 bytes as you can see) taken from this web site. For this trial you must use a tool like SQL Developer or you would need to change quite a log of configuration (see Storing and Checking Character Codepoints in an UTF8/AL32UTF8 (Unicode) database (Doc ID 69518.1)):
SQL> INSERT INTO test_table VALUES(UNISTR('\4E2D\56FD\8BDD\4E0D\7528') * SQL Error: ORA-12899: VALUE too large FOR COLUMN "YJAQUIER"."TEST_TABLE"."COL1" (actual: 15, maximum: 10) |
Now if I create the table like (You may also change NLS_LENGTH_SEMANTICS to CHAR with ALTER SYSTEM and specify nothing, but this is strongly NOT recommended by Oracle):
CREATE TABLE test_table( col1 VARCHAR2(10 CHAR) ); |
And insert 10 characters:
SQL> INSERT INTO test_table VALUES(UNISTR('\4E2D\56FD\8BDD\4E0D\7528\5F41\5B57\4E2D\56FD\8BDD')); 1 ROW inserted. SQL> SELECT * FROM test_table; COL1 ---------- 中国话不用彁字中国话 |
If I push to 11 characters:
SQL> INSERT INTO test_table VALUES(UNISTR('\4E2D\56FD\8BDD\4E0D\7528\5F41\5B57\4E2D\56FD\8BDD\4E0D')); SQL Error: ORA-12899: VALUE too large FOR COLUMN "YJAQUIER"."TEST_TABLE"."COL1" (actual: 15, maximum: 10) |
All the screenshots below have been made using a 19c Enterprise Edition (19.19) database running on a server with Red Hat Enterprise Linux release 8.7 (Ootpa), 256GB of memory and 8 cores. DMU version is 23.1.
Disclaimer:
DMU tool is really buggy and is freezing quite often on my Laptop, so get prepared to kill the task in Process Explorer and rerun it…
DMU preparation
You must have obsolete Java 8 on your Laptop to run DMU (quite funny for an Oracle product as Oracle is also owning Java, current Java LTS is 21), take openJDK to avoid any licensing issue. DMU is delivery as a simple zip that I have chosen to run directly from my Windows Laptop. As a pre-requisite execute on your database as SYS the @?/rdbms/admin/prvtdumi.plb script.
All DMU connection are now as SYSDBA:

So create a password file on your instance with (supply SYS password when prompted):
orapwd file=$ORACLE_HOME/dbs/orapw$ORACLE_SID force=y |
And grant SYSDBA privilege to the account you plan to use in DMU:
SQL> GRANT sysdba TO yjaquier; GRANT succeeded. |
Ensure force logging is not activated while converting to Unicode:
SQL> SELECT force_logging FROM v$database; FORCE_LOGGING ________________ NO |
And purge all recyclebin data with:
SQL> purge dba_recyclebin;
DBA Recyclebin purged. |
When you create the repository choose AL32UTF8, UTF8 is a legacy on that does not follow the latest Unicode evolution…
DMU scan the database
Right click on your connection in DMU and choose Scan Database…. I have increased a bit the allocated memory to speed up the process (do not increase too much as I have seen it unproductive). Also choose the important Collect also rowids for Update Convertible Rows conversion method. This is improving a lot the performance of manual cleaning process when you display rows:
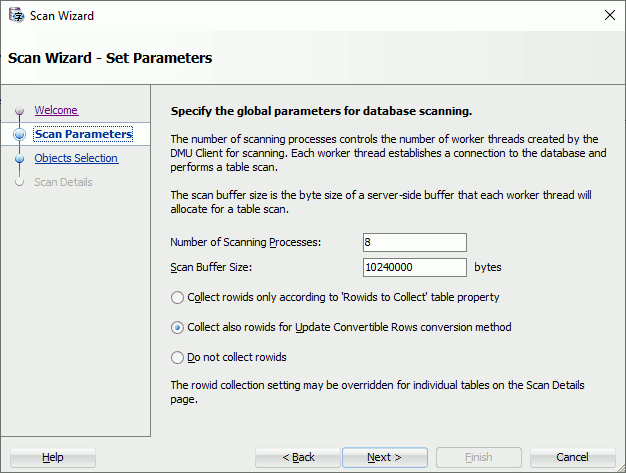
Tips:
If you cannot click on the Finish button then just press Enter on your keyboard…
At then end of the scan, again right click on your connection name (WWDC QA for me) and choose Database Scan Report…. I have issue (the yellow warning sign) only on my applicative schemas:
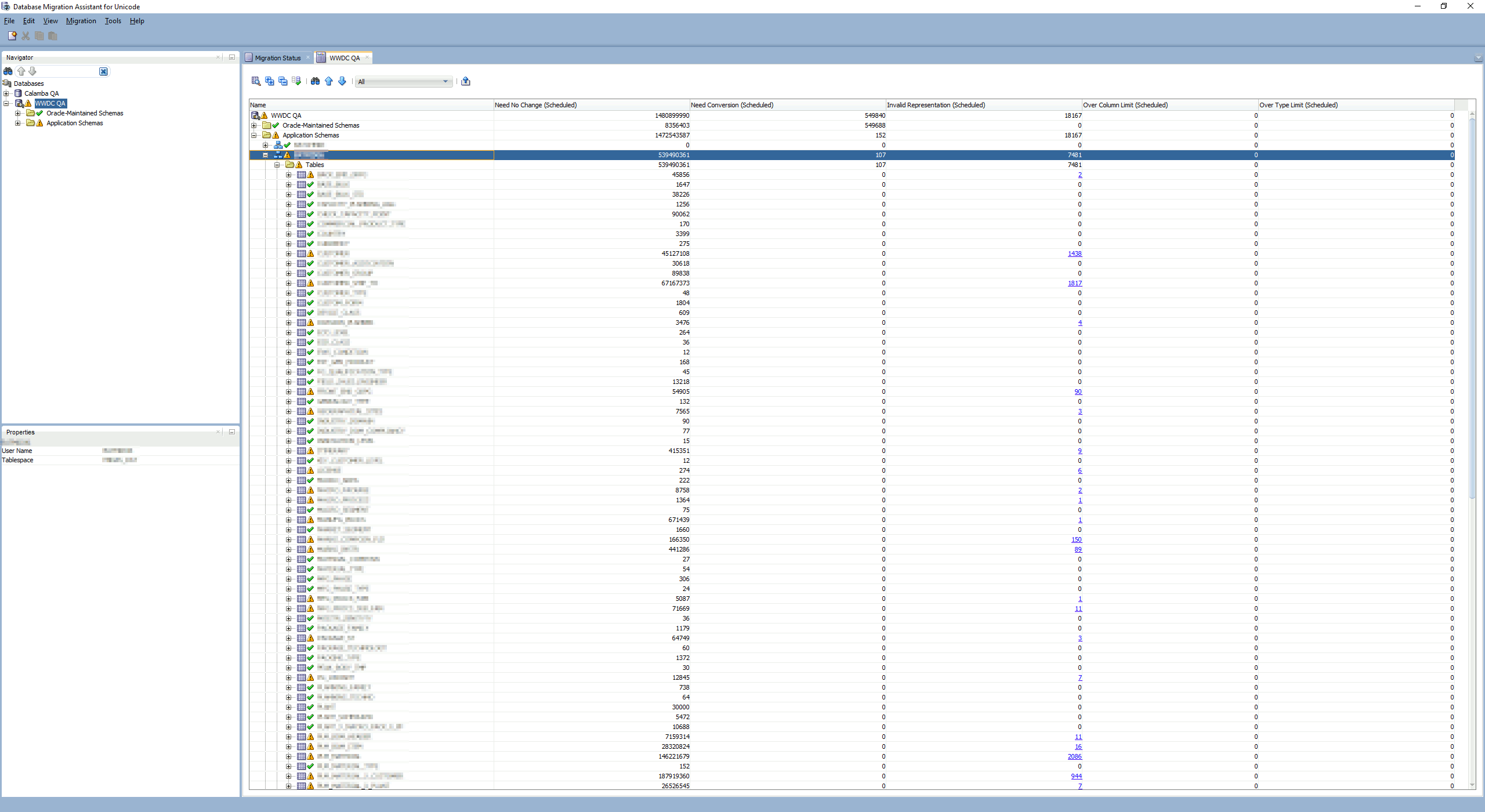
Remark:
So far I have only issue in data and I have not Over Column Limit as well as Over Type Limit…
If you right click on your connection name and choose Export Problem Data… you can generate an Excel file to be shared with your applicative team to show them where are the problems:

DMU Resolve migration issue
To go to the next step that is actually converting the database you have to handle every problem of the scan step… Means correcting every single problem, table by table and row by row… Problems can be multiples and in my example above I have wrong characters stored in my source US7ASCII database as well as string that will occupy more space in the variable length Unicode character set (AL32UTF8).
To cleanse your data either you enter in Cleansing Editor by right clicking on a object having problem (yellow alert sign), and the the nice tips is to filter by problem (I only have Invalid Binary Representation):

And then you edit the data, correcting wrong character…
Or you can expand the list of columns of a problematic object and on the problematic column right click to access properties and in four tab acknowledge you are going to convert the database knowing you have issue (issue that could be resolve by moving to Unicode):
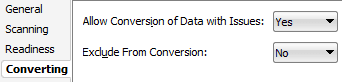
In my case for some tables I have more than 2000 rows with wrong characters… So it is not really possible for a normal human being to correct al this… Ultimately you could do it column by column but to go faster they have implemented the Bulk Cleansing, access to it by right clicking on your connection name.
Here you can acknowledge globally that you have data issue but still want to go to Unicode:
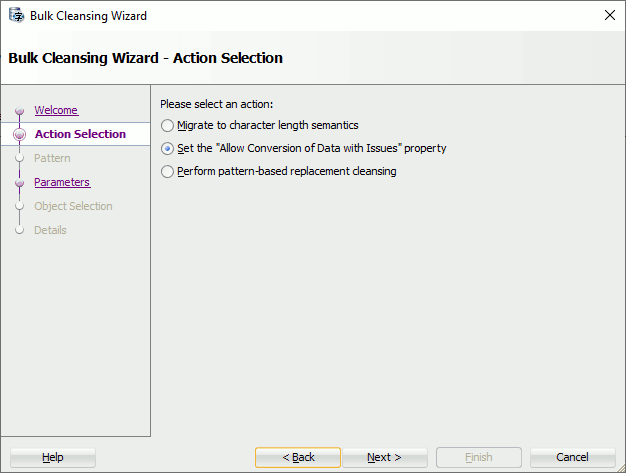
Choose yes in this panel, the No is to revert a previous wrong bulk conversion:

You can also fine select on which schema and object you want to bulk apply this option, choosing different option for different set of objects…
DMU convert the database to Unicode
After you have purged all the issue (in whatever manner) you are allowed to right click on your connection name and choose Convert Database….
The conversion is in five steps and you can access step by step all what DMU will execute:
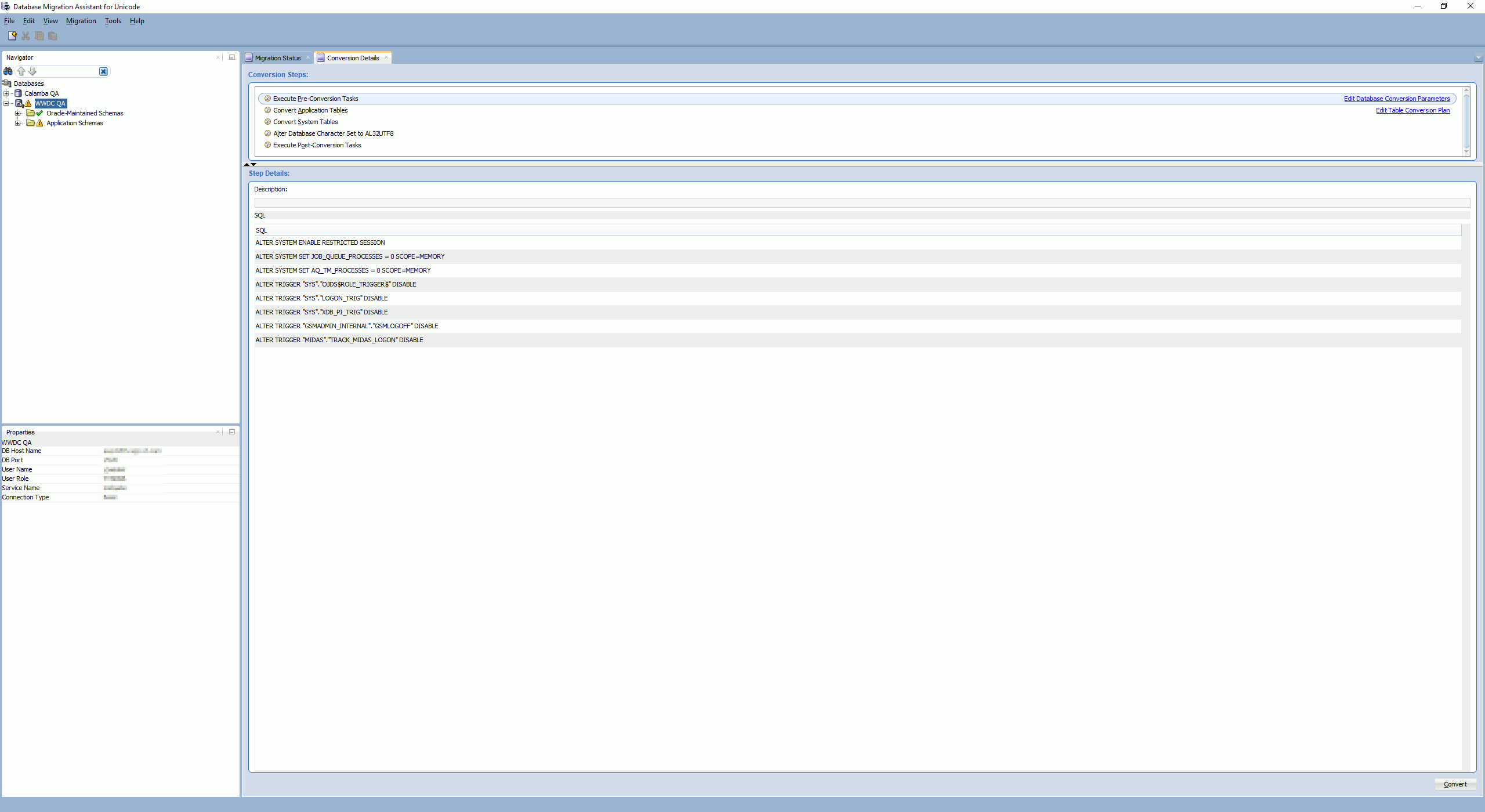
The applicative step will be a bunch of statement like this:
UPDATE /*+ PARALLEL(8)*/ "ACCOUNT"."TABLE" A SET A."COLUMN01" = SYS_OP_CSCONV(A."COLUMN01", 'AL32UTF8'), A."COLUMN02" = SYS_OP_CSCONV(A."COLUMN02", 'AL32UTF8'),... |
As well as few DROP INDEX and ALTER TABLE … MODIFY (“COLUMN01” VARCHAR2(xx byte)). All the dropped indexes will be recreated at the Execute Post-Conversion Tasks and the modified column length should be reverted too. Only in my case because I have only Binary Representation issues…
The conversion parameters, as well as for other steps, can be changed by right clicking on your connection name and choosing Properties:
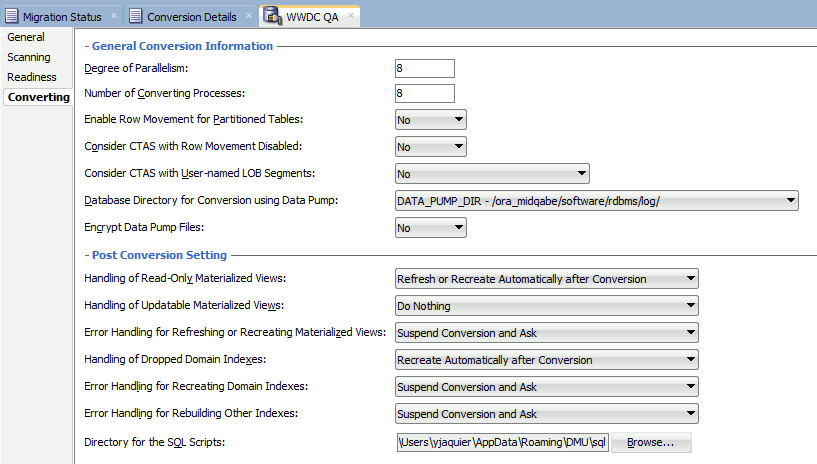
You can press the final convert button. It is anyway really important to execute this process on a copy of your production database to see:
- All is going as expected
- Allow your applicative team to test conversion has not created any issue
- Get an idea of the expected run time. Yes this process is an offline one and the database will not be accessible while converting it. All the other tasks are simply stored in the repository and can be done while the database is accessible to users
The execution has taken xxx minutes on our test database, due to the issue in AUDSYS.AUD$UNIFIED we have started it in upgrade mode…
The conversion went well but I noticed that all columns move from something like VARCAHAR2(20) to VARCAHR2(20 CHAR). This would need to be taken care in the case of objects dropped and recreated each day, which is exactly what we are doing…
References
- Changing the NLS_CHARACTERSET to AL32UTF8 / UTF8 (Unicode) in 8i, 9i , 10g and 11g (Doc ID 260192.1)
- Changing Or Choosing the Database Character Set ( NLS_CHARACTERSET ) (Doc ID 225912.1)
- AL32UTF8 / UTF8 (Unicode) Database Character Set Implications (Doc ID 788156.1)
- The Database Migration Assistant for Unicode (DMU) Tool (Doc ID 1272374.1)
- Tips For and Known Issues With The Database Migration Assistant for Unicode (DMU) Tool version (Doc ID 2018250.1)
- ORA-01401 / ORA-12899 / ORA-01461 While Importing Or Loading Data In An AL32UTF8 / UTF8 (Unicode) Or Other Multibyte NLS_CHARACTERSET Database. (Doc ID 1297961.1)
- DMU during convert database Phase hits ORA-46385 on AUDSYS.AUD$UNIFIED (Doc ID 2307747.1)




 installation and usage")
