Table of contents
- Preamble
- StreamSets Data Collector installation
- StreamSets Data Collector source Oracle database configuration
- StreamSets Data Collector Oracle to Oracle replication
- StreamSets Data Collector Oracle to JSON file generation
- StreamSets Data Collector Oracle to MySQL replication
-
Errors encountered
- JDBC_52 - Error starting LogMiner
- JDBC_44 - Error while getting changes due to error: java.sql.SQLRecoverableException: Closed Connection: getBigDecimal
- ORA-01291: missing logfile
- JDBC_16 - Table '' does not exist or PDB is incorrect. Make sure the correct PDB was specified
- JDBC_00 - Cannot connect to specified database: com.zaxxer.hikari.pool.PoolInitializationException: Exception during pool initialization: The server time zone value 'CEST' is unrecognized or represents more than one time zone.
- Establishing SSL connection without server's identity verification is not recommended
- JdbcGenericRecordWriter - No parameters found for record with ID
- References
Preamble
I came across a nice overview article of Franck Pachot and shared it with few teammates and they have all been interested by StreamSets Data Collector product. One of the main reason is the obvious cost cutting versus GoldenGate that we have implemented in a project deployed worldwide. The product is free but has some clearly described limitation like managing only INSERT, UPDATE, SELECT_FOR_UPDATE, and DELETE operations for one or more tables in a database. So in other words DDL are not managed as well as few data types (not an issue for us)…
To really handle DDL you would have to check “Produce Events” check box and handle the generated events on target to handle DDL, this is a little bit more complex and outside the scope of this blog post…
I have decided to give a try to the product and implement it for what we currently do with GoldenGate means building a reporting environment of our production database. Target is also an Oracle database but might be in future a MySQL one.
My testing environment is made of three servers:
- server1.domain.com (192.168.56.101) is the primary database server.
- server2.domain.com (192.168.56.102) is the secondary database server. The server hosting the databases (Oracle & MySQL) where figures should land.
- server4.domain.com (192.168.56.104) is the StreamSets server.
Oracle database release is 18c Enterprise Edition Release 18.3.0.0.0. StreamSets is release 3.4.1. MySQL release is 8.0.12 MySQL Community Server.
The three servers are in fact VirtualBox guests running Oracle Linux Server release 7.5.
StreamSets Data Collector installation
I have first created a Linux streamsets account (in users group) with a /streamsets dedicated filesystem:
[streamsets@server4 ~]$ id uid=1001(streamsets) gid=100(users) groups=100(users) [streamsets@server4 ~]$ pwd /streamsets [streamsets@server4 ~]$ ll total 246332 -rw-r--r-- 1 streamsets users 248202258 Aug 2 15:32 streamsets-datacollector-core-3.4.1.tgz |
[streamsets@server4 streamsets]$ tar xvzf streamsets-datacollector-core-3.4.1.tgz [streamsets@server4 ~]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets dc Can't find java, please set JAVA_HOME pointing to your java installation |
I have installed Java SE Development Kit 8 (jdk-8u181-linux-x64.rpm). Only release 8 is supported so far…
[streamsets@server4 streamsets]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets dc Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS Configuration of maximum open file limit is too low: 1024 (expected at least 32768). Please consult https://goo.gl/LgvGFl |
At the end of /etc/security/limits.conf I have added:
streamsets soft nofile 32768 streamsets hard nofile 32768 |
Now I can launch the process with:
[streamsets@server4 streamsets]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets dc Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS Logging initialized @1033ms to org.eclipse.jetty.util.log.Slf4jLog Running on URI : 'http://server4:18630' |
Then from any browser (at this url for me, http://server4.domain.com:18630) you should get this login windows (admin/admin as default username/password):
Once logged you get:

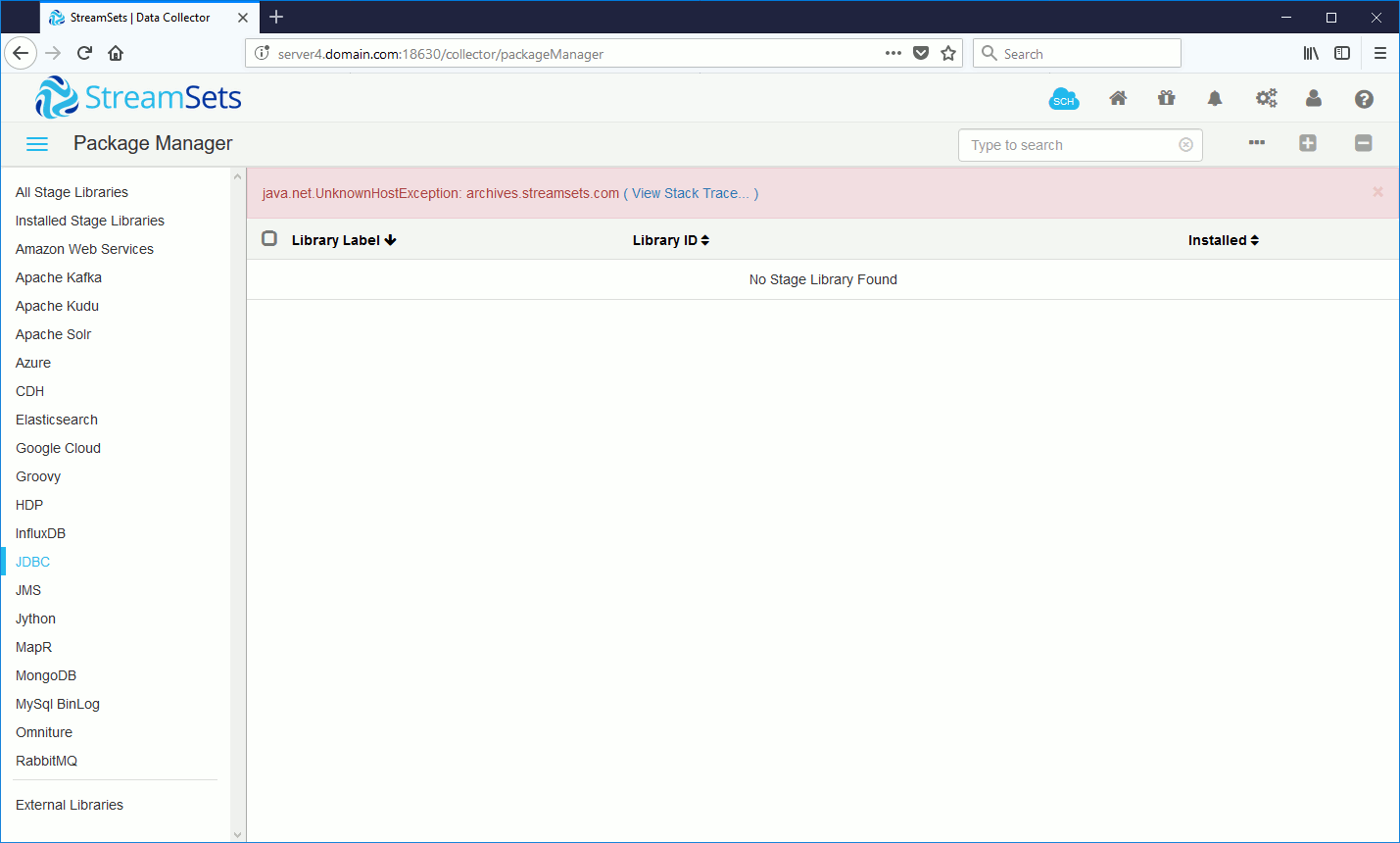
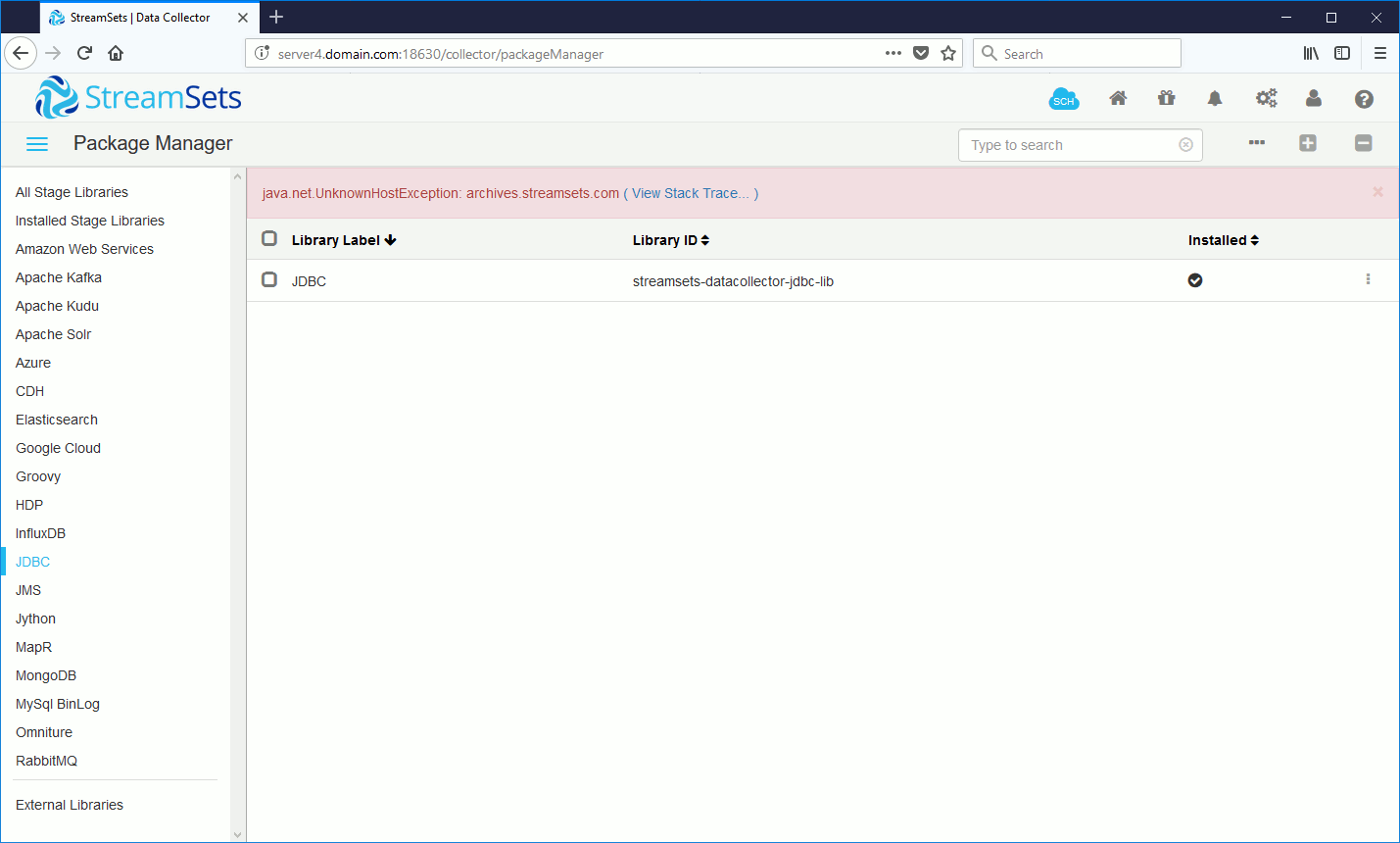
By default Oracle CDC (Change Data Capture) client requires Oracle JDBC thin driver, in top left tool bar click on Package Manager (third icon). If you go in JDBC you see that nothing is there (the error message is because I’m behind a company proxy):
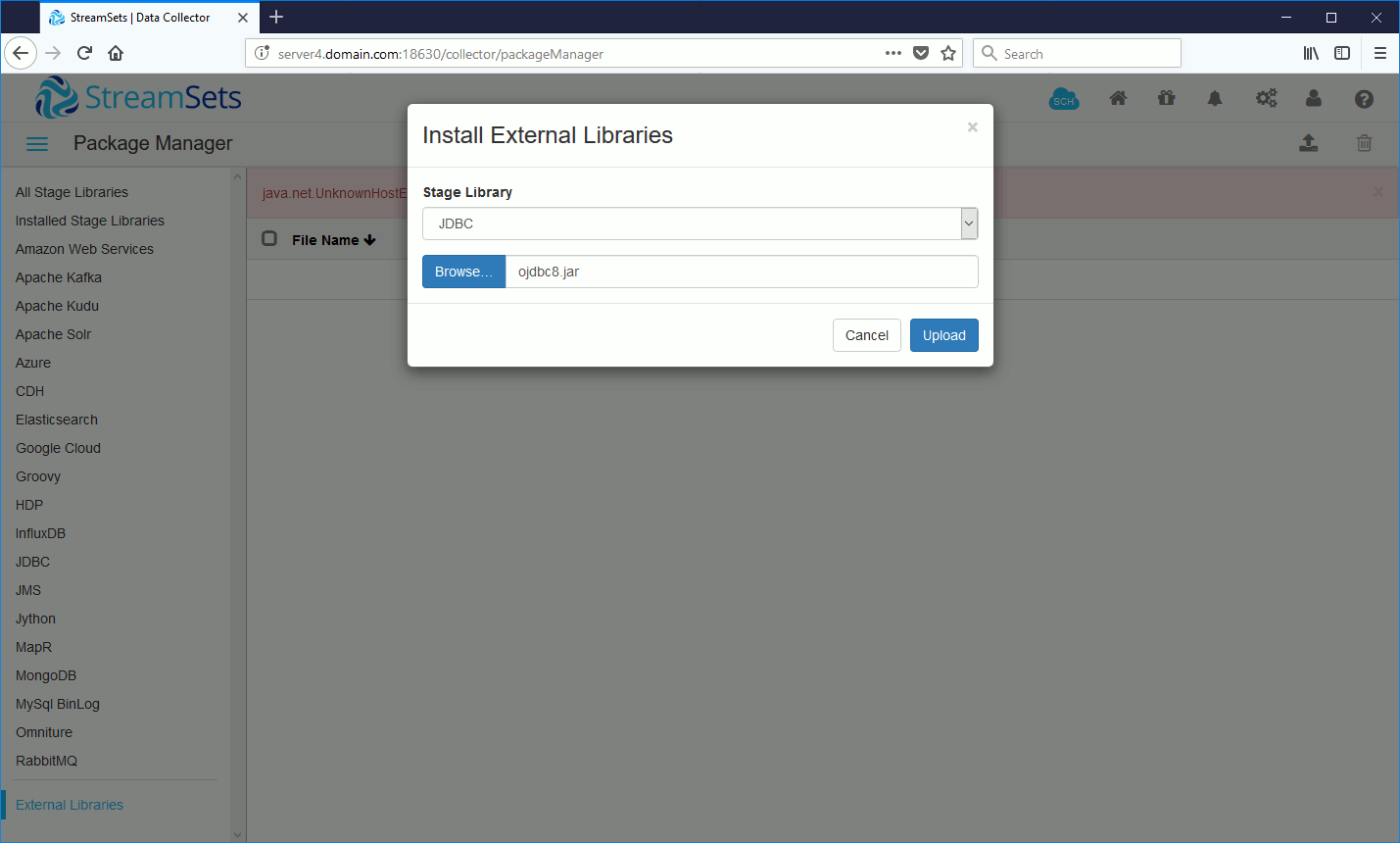
When I tried to import my JDBC thin driver file (ojdbc8.jar, the name for 18c (18.3) is the same as for 12.2.0.1, but the size differ) I have seen that JDBC category is not there:
I have spent a bit of time to see that everything was on StreamSets Data Collector download page:
[streamsets@server4 ~]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets stagelibs -list curl: (6) Could not resolve host: archives.streamsets.com; Unknown error Failed! running curl -s -f https://archives.streamsets.com/datacollector/3.4.1/tarball/stage-lib-manifest.properties.sha1 -SL -o /tmp/sdc-setup-20988/stage-lib-manifest.properties.sha1 in /home/streamsets [streamsets@server4 ~]$ export https_proxy='http://proxy_account:proxy_password@proxy_host:proxy_port' [streamsets@server4 ~]$ echo $https_proxy http://proxy_account:proxy_password@proxy_host:proxy_port [streamsets@server4 streamsets]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets stagelibs -list StreamSets Data Collector Stage Library Repository: https://archives.streamsets.com/datacollector/3.4.1/tarball ID Name Installed ================================================================================================================= streamsets-datacollector-aerospike-lib Aerospike 3.15.0.2 NO streamsets-datacollector-apache-kafka_0_10-lib Apache Kafka 0.10.0.0 NO streamsets-datacollector-apache-kafka_0_11-lib Apache Kafka 0.11.0.0 NO streamsets-datacollector-apache-kafka_0_9-lib Apache Kafka 0.9.0.1 NO streamsets-datacollector-apache-kafka_1_0-lib Apache Kafka 1.0.0 NO streamsets-datacollector-apache-kudu_1_3-lib Apache Kudu 1.3.0 NO streamsets-datacollector-apache-kudu_1_4-lib Apache Kudu 1.4.0 NO . . streamsets-datacollector-jdbc-lib JDBC NO . . |
[streamsets@server4 streamsets]$ /streamsets/streamsets-datacollector-3.4.1/bin/streamsets stagelibs -install=streamsets-datacollector-jdbc-lib Downloading: https://archives.streamsets.com/datacollector/3.4.1/tarball/streamsets-datacollector-jdbc-lib-3.4.1.tgz ######################################################################## 100.0% Stage library streamsets-datacollector-jdbc-lib installed |
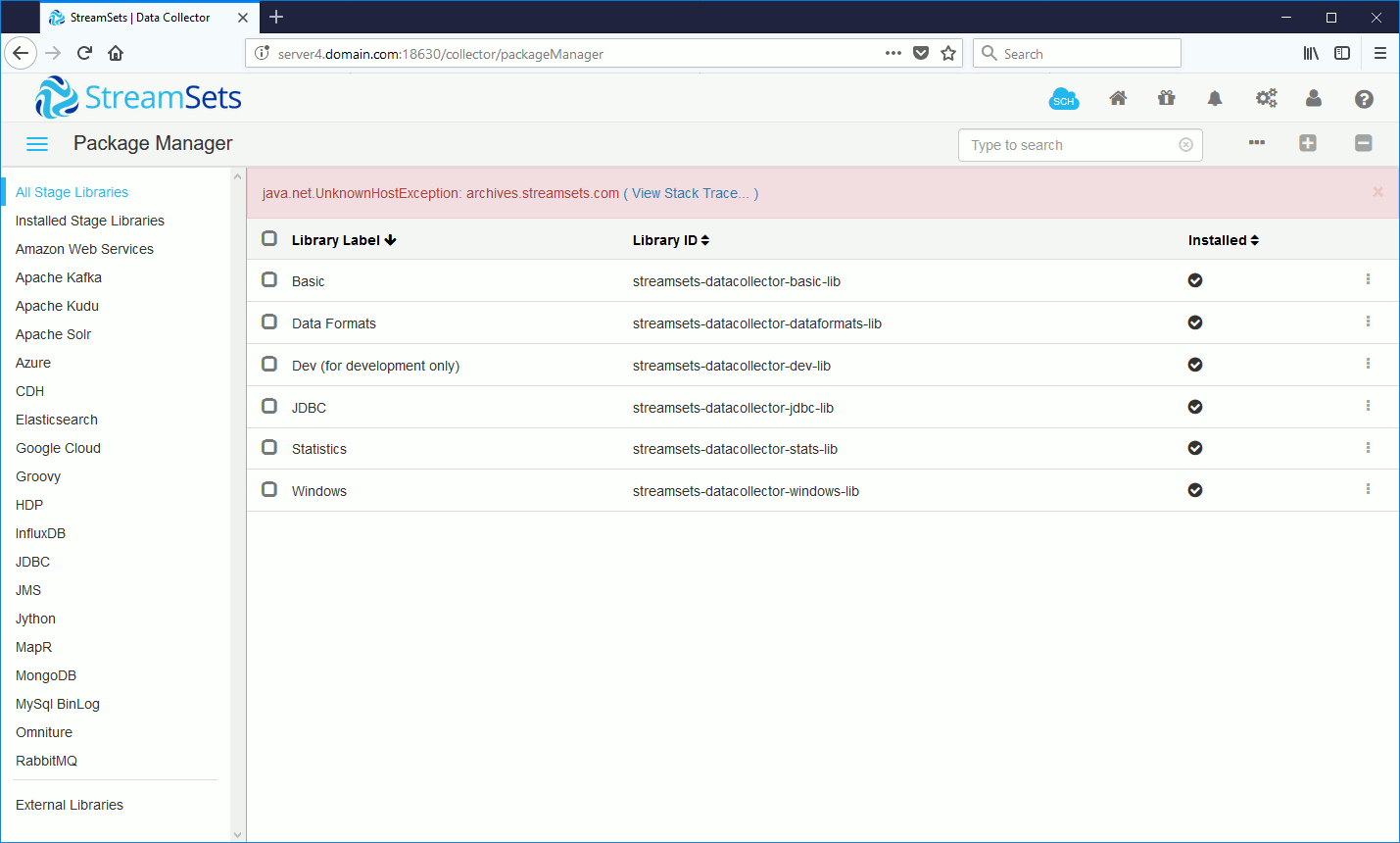
Relaunch StreamSets Data Collector and back to web interface I have now seen JDBC as possible library:
So imported JDBC driver:
You should be prompt to restart StreamSets Data Collector and see below screen:
StreamSets Data Collector source Oracle database configuration
This source multitenant Oracle database is common for the three scenario I have decided to test so you have to do it only once. On this source Oracle database you have to create a global account able to manage LogMiner (global because LogMiner is accessible from root pluggable database in a multitenant architecture):
SQL> ALTER SESSION SET container=cdb$root; SESSION altered. SQL> CREATE USER c##streamsets IDENTIFIED BY "streamsets" container=ALL; USER created. SQL> GRANT CREATE SESSION, ALTER SESSION, SET container, SELECT ANY dictionary, logmining, execute_catalog_role TO c##streamsets container=ALL; GRANT succeeded. SQL> ALTER SESSION SET container=pdb1; SESSION altered. |
Change source Oracle database to archivelog mode and activate default supplemental log:
SQL> shutdown IMMEDIATE; DATABASE closed. DATABASE dismounted. ORACLE instance shut down. SQL> startup mount; ORACLE instance started. Total SYSTEM Global Area 1048575184 bytes Fixed SIZE 8903888 bytes Variable SIZE 729808896 bytes DATABASE Buffers 301989888 bytes Redo Buffers 7872512 bytes DATABASE mounted. SQL> ALTER DATABASE archivelog; DATABASE altered. SQL> ALTER DATABASE OPEN; DATABASE altered. SQL> SELECT supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all FROM v$database; SUPPLEME SUP SUP -------- --- --- NO NO NO SQL> ALTER DATABASE ADD supplemental LOG data; DATABASE altered. SQL> SELECT supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all FROM v$database; SUPPLEME SUP SUP -------- --- --- YES NO NO SQL> ALTER SYSTEM switch logfile; SYSTEM altered. |
I have also created a test schema on my pluggable database (pdb1) to handle my test table:
SQL> CREATE USER test01 IDENTIFIED BY test01; USER created. SQL> GRANT CONNECT,RESOURCE TO test01; GRANT succeeded. SQL> ALTER USER test01 quota unlimited ON users; USER altered. |
Create a test table and add supplemental log:
SQL> CREATE TABLE test01.table01 ( id NUMBER NOT NULL, descr VARCHAR2(50), CONSTRAINT table01_pk PRIMARY KEY (id) enable ); TABLE created. SQL> ALTER TABLE test01.table01 ADD supplemental LOG data (PRIMARY KEY) columns; TABLE altered. SQL> SET lines 200 pages 1000 SQL> col table_name FOR a15 SQL> col log_group_name FOR a15 SQL> col owner FOR a15 SQL> SELECT * FROM dba_log_groups WHERE owner='TEST01'; OWNER LOG_GROUP_NAME TABLE_NAME LOG_GROUP_TYPE ALWAYS GENERATED --------------- --------------- --------------- ------------------- ----------- -------------- TEST01 SYS_C007365 TABLE01 PRIMARY KEY LOGGING ALWAYS GENERATED NAME |
And insert few rows in it to simulate an already existing environment:
SQL> INSERT INTO test01.table01 VALUES(1,'One'); 1 ROW created. SQL> INSERT INTO test01.table01 VALUES(2,'Two'); 1 ROW created. SQL> COMMIT; COMMIT complete. |
On source database generate a dictionary in redo log. If you choose to set “Dictionary Source” to Online Catalog then this step is not mandatory. It is also much faster on small ressources to use from Online Catalog so really up to you:
SQL> ALTER SESSION SET container=cdb$root; SESSION altered. SQL> EXECUTE dbms_logmnr_d.build(options=> dbms_logmnr_d.store_in_redo_logs); PL/SQL PROCEDURE successfully completed. SQL> col name FOR a60 SQL> SET lines 200 pages 1000 SQL> SELECT name,dictionary_begin,dictionary_end FROM v$archived_log WHERE name IS NOT NULL ORDER BY recid DESC; NAME DIC DIC ------------------------------------------------------------ --- --- /u01/app/oracle/oradata/ORCL/arch/1_135_983097959.dbf YES YES /u01/app/oracle/oradata/ORCL/arch/1_134_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_133_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_132_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_131_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_130_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_129_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_128_983097959.dbf YES YES /u01/app/oracle/oradata/ORCL/arch/1_127_983097959.dbf NO NO /u01/app/oracle/oradata/ORCL/arch/1_126_983097959.dbf NO NO |
StreamSets Data Collector Oracle to Oracle replication
Oracle prerequisites
On target Oracle database I have created an account in my target pluggable database (pdb1):>/p>
SQL> CREATE USER test01 IDENTIFIED BY test01; USER created. SQL> GRANT CONNECT,RESOURCE TO test01; GRANT succeeded. SQL> ALTER USER test01 quota unlimited ON users; USER altered. |
On source database create an export directory and grant read and write on it to test01 account:
SQL> ALTER SESSION SET container=pdb1; SESSION altered. SQL> CREATE OR REPLACE DIRECTORY tmp AS '/tmp'; DIRECTORY created. SQL> GRANT read,WRITE ON DIRECTORY tmp TO test01; GRANT succeeded. |
Get the current System Change Number (SCN) on source database with:
SQL> SELECT current_scn FROM v$database; CURRENT_SCN ----------- 5424515 |
Finally export the figures with:
[oracle@server1 ~]$ expdp test01/test01@pdb1 dumpfile=table01.dmp directory=tmp tables=table01 flashback_scn=5424515 Export: Release 18.0.0.0.0 - Production on Wed Sep 5 13:02:23 2018 Version 18.3.0.0.0 Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production Starting "TEST01"."SYS_EXPORT_TABLE_01": test01/********@pdb1 dumpfile=table01.dmp directory=tmp tables=table01 flashback_scn=5424515 Processing object type TABLE_EXPORT/TABLE/TABLE_DATA Processing object type TABLE_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Processing object type TABLE_EXPORT/TABLE/STATISTICS/MARKER Processing object type TABLE_EXPORT/TABLE/TABLE Processing object type TABLE_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT Processing object type TABLE_EXPORT/TABLE/CONSTRAINT/CONSTRAINT . . exported "TEST01"."TABLE01" 5.492 KB 2 rows Master table "TEST01"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded ****************************************************************************** Dump file set for TEST01.SYS_EXPORT_TABLE_01 is: /tmp/table01.dmp Job "TEST01"."SYS_EXPORT_TABLE_01" successfully completed at Wed Sep 5 13:04:25 2018 elapsed 0 00:01:09 [oracle@server1 ~]$ ll /tmp/table01.dmp -rw-r----- 1 oracle dba 200704 Sep 5 13:04 /tmp/table01.dmp [oracle@server1 ~]$ scp /tmp/table01.dmp server2.domain.com:/tmp The authenticity of host 'server2.domain.com (192.168.56.102)' can't be established. ECDSA key fingerprint is SHA256:hduqTIePPHF3Y+N/ekuZKnnXbocm+PNS7yU/HCf1GEw. ECDSA key fingerprint is MD5:13:dc:e3:27:bc:4b:08:b8:bf:53:2a:15:3c:86:d7:c4. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'server2.domain.com' (ECDSA) to the list of known hosts. oracle@server2.domain.com's password: table01.dmp 100% 196KB 19.0MB/s 00:00 |
Import the figures on target database with something like (in pdb1 pluggable database):
[oracle@server2 ~]$ impdp test01/test01@pdb1 file=table01.dmp directory=tmp Import: Release 18.0.0.0.0 - Production on Wed Sep 5 13:06:46 2018 Version 18.3.0.0.0 Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production Legacy Mode Active due to the following parameters: Legacy Mode Parameter: "file=table01.dmp" Location: Command Line, Replaced with: "dumpfile=table01.dmp" Master table "TEST01"."SYS_IMPORT_FULL_01" successfully loaded/unloaded Starting "TEST01"."SYS_IMPORT_FULL_01": test01/********@pdb1 dumpfile=table01.dmp directory=tmp Processing object type TABLE_EXPORT/TABLE/TABLE Processing object type TABLE_EXPORT/TABLE/TABLE_DATA . . imported "TEST01"."TABLE01" 5.492 KB 2 rows Processing object type TABLE_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT ORA-39083: Object type OBJECT_GRANT failed to create with error: ORA-01917: user or role 'C##STREAMSETS' does not exist Failing sql is: GRANT SELECT ON "TEST01"."TABLE01" TO "C##STREAMSETS" Processing object type TABLE_EXPORT/TABLE/CONSTRAINT/CONSTRAINT Processing object type TABLE_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Processing object type TABLE_EXPORT/TABLE/STATISTICS/MARKER Job "TEST01"."SYS_IMPORT_FULL_01" completed with 1 error(s) at Wed Sep 5 13:07:47 2018 elapsed 0 00:00:46 |
StreamSets Data Collector configuration
Create the pipeline:
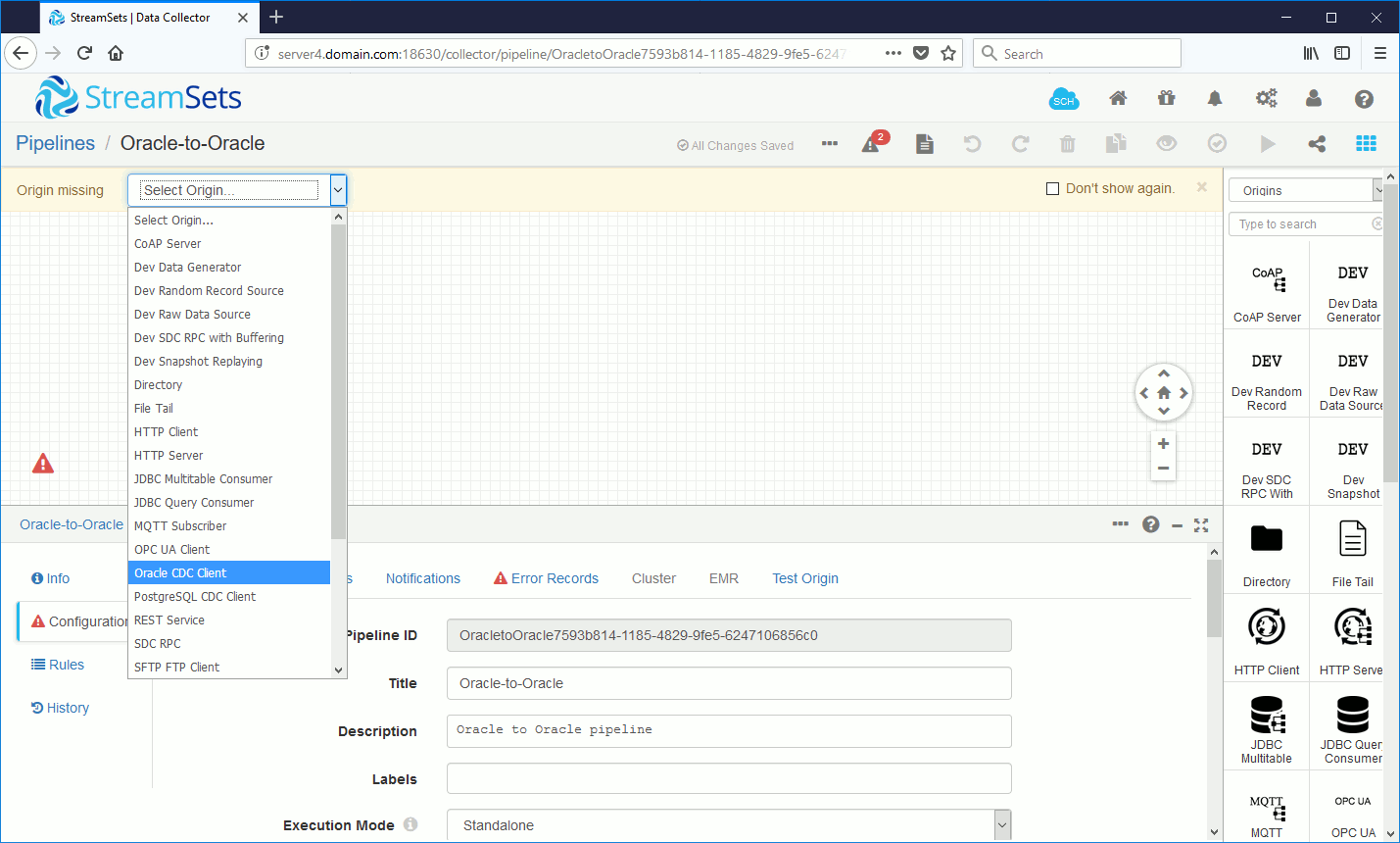
Choose Oracle CDC Client as a source (from replicating from Oracle this is the de facto option to choose):
Configure all parameters. I have chosen the most reliable solution to get dictionary from redo in case we want to test schema change (DDL). As the simplest test I have chosen From Latest Change – Processes changes that arrive after you start the pipeline. I will re-configure it after the database settings:
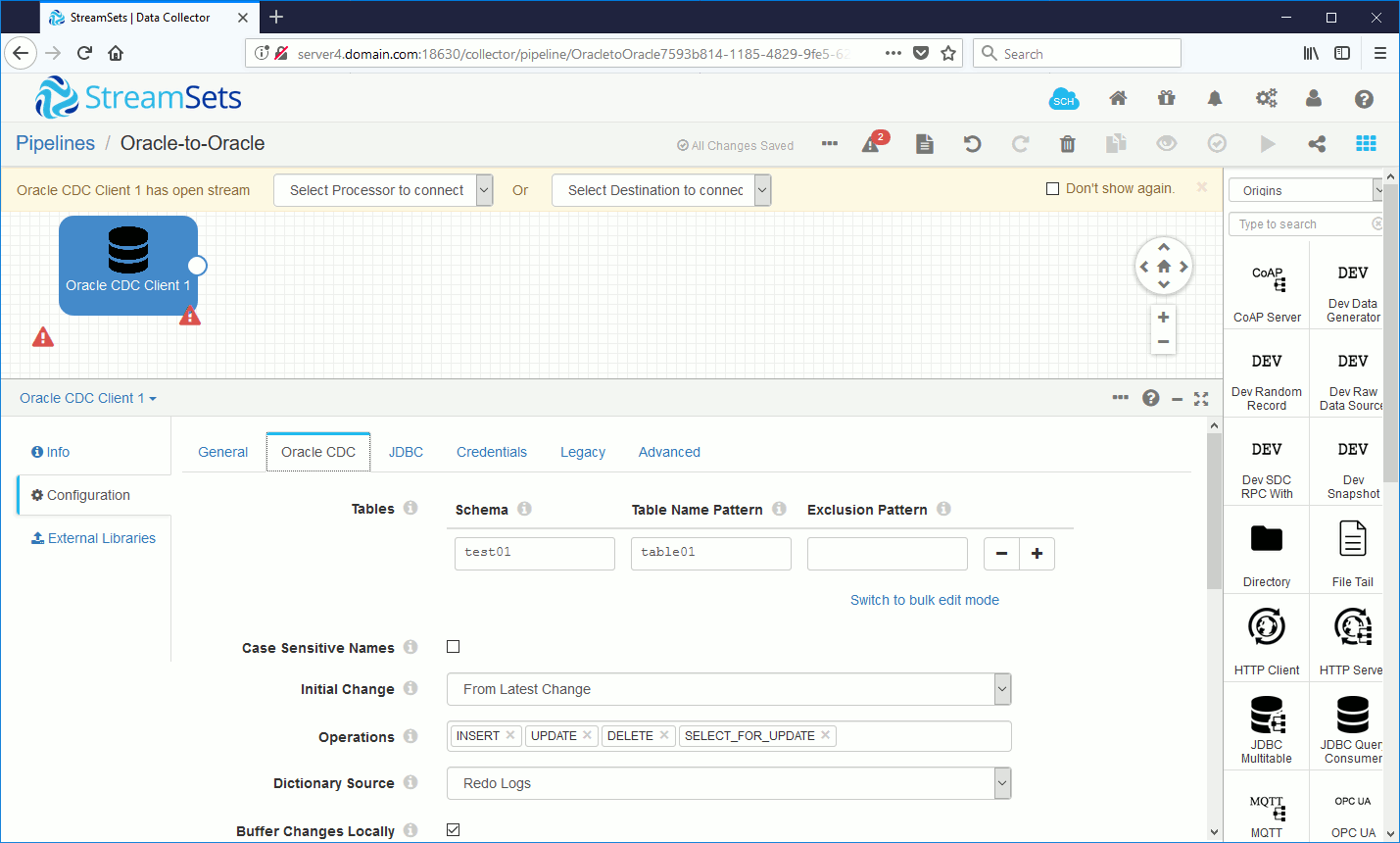
Below query can help you to choose correct database time zone:
SQL> SELECT DBTIMEZONE FROM DUAL; DBTIME ------ +00:00 |
Set JDBC connection string (I am in a multitenant configuration):
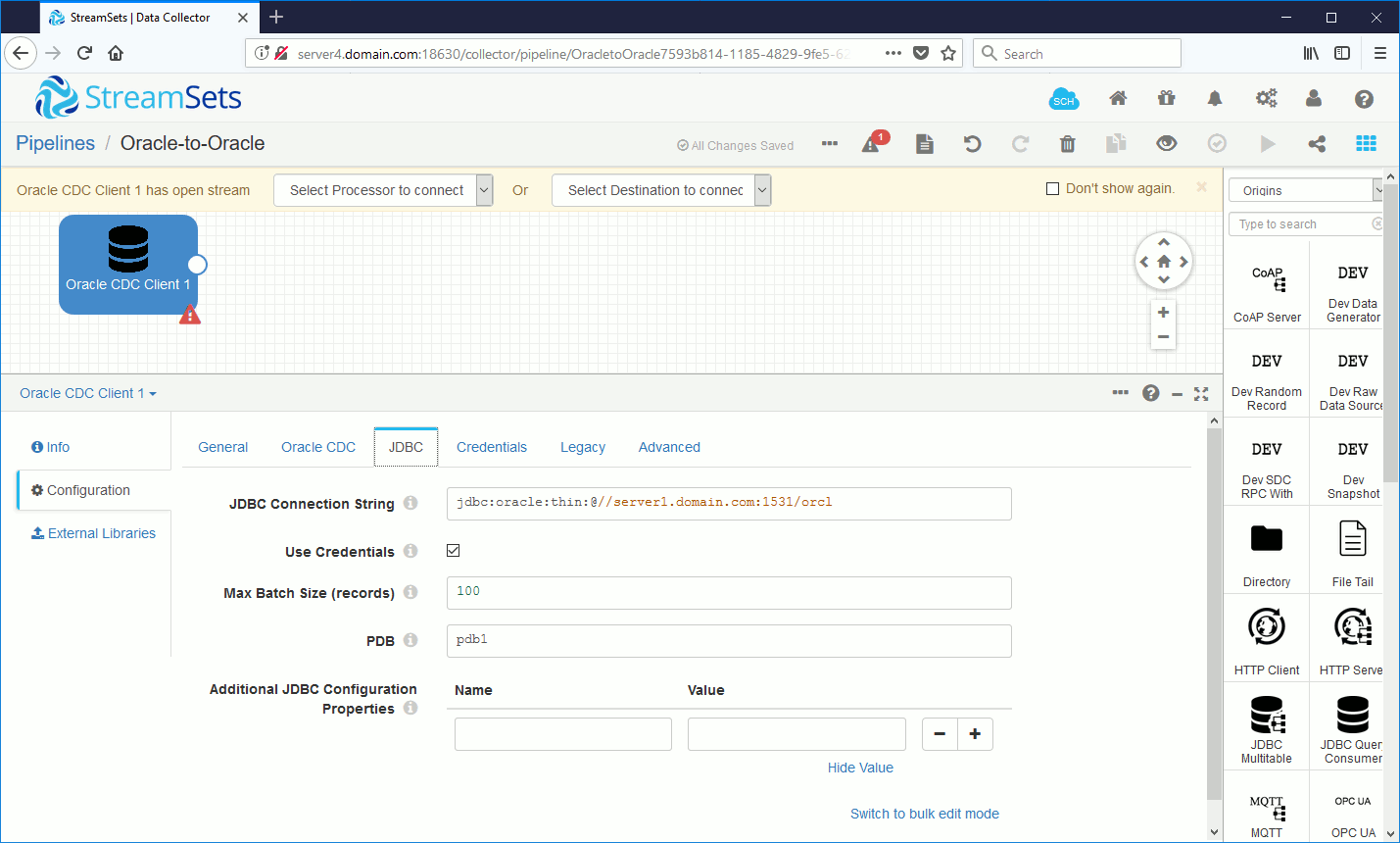
Use the global account we have define earlier:
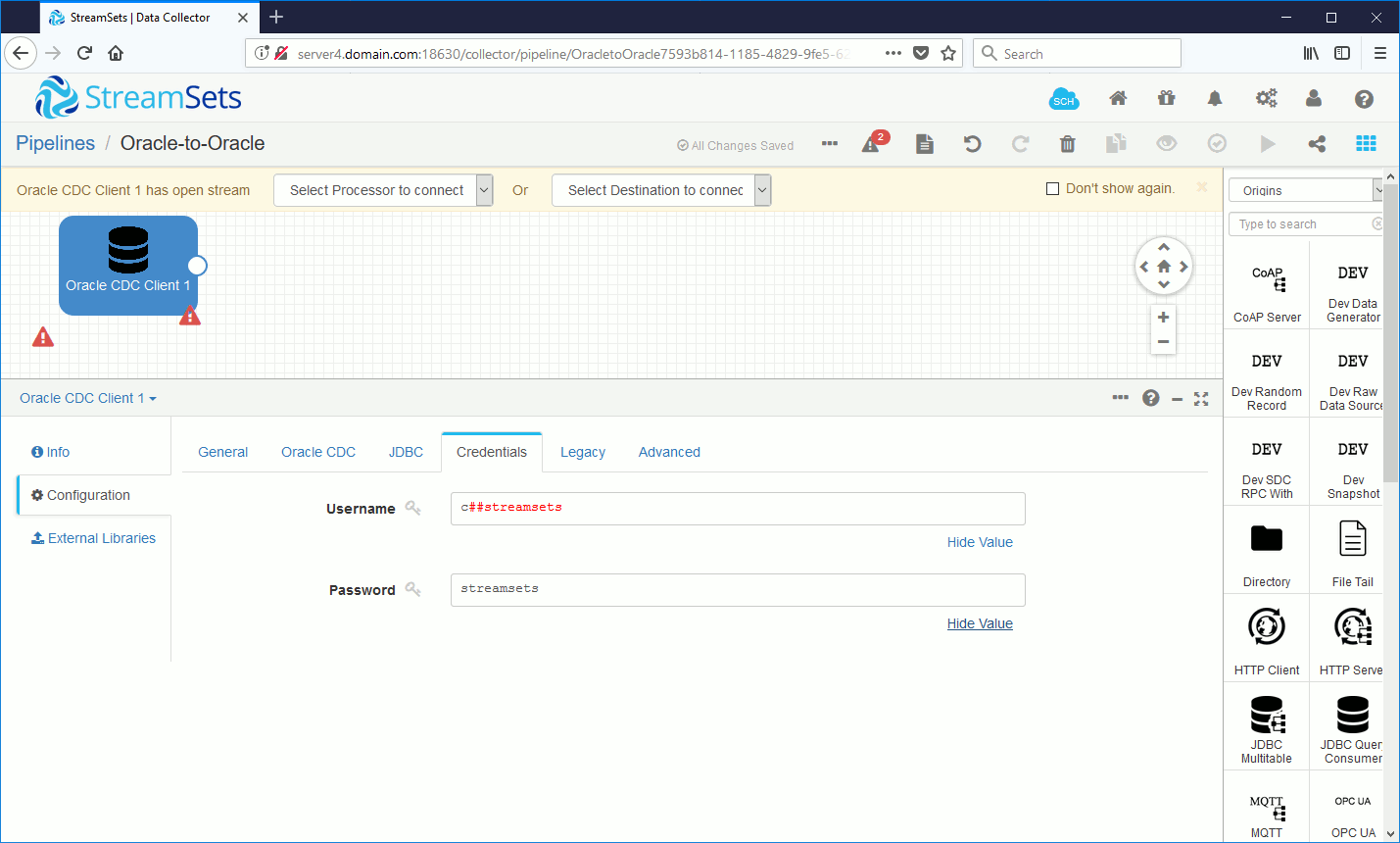
Not defining a Processor to modify figures between source and target but obviously this is possible:

Set JDBC connection string. I am in a multitenant configuration but here I just connect to the pluggable destination database directly:
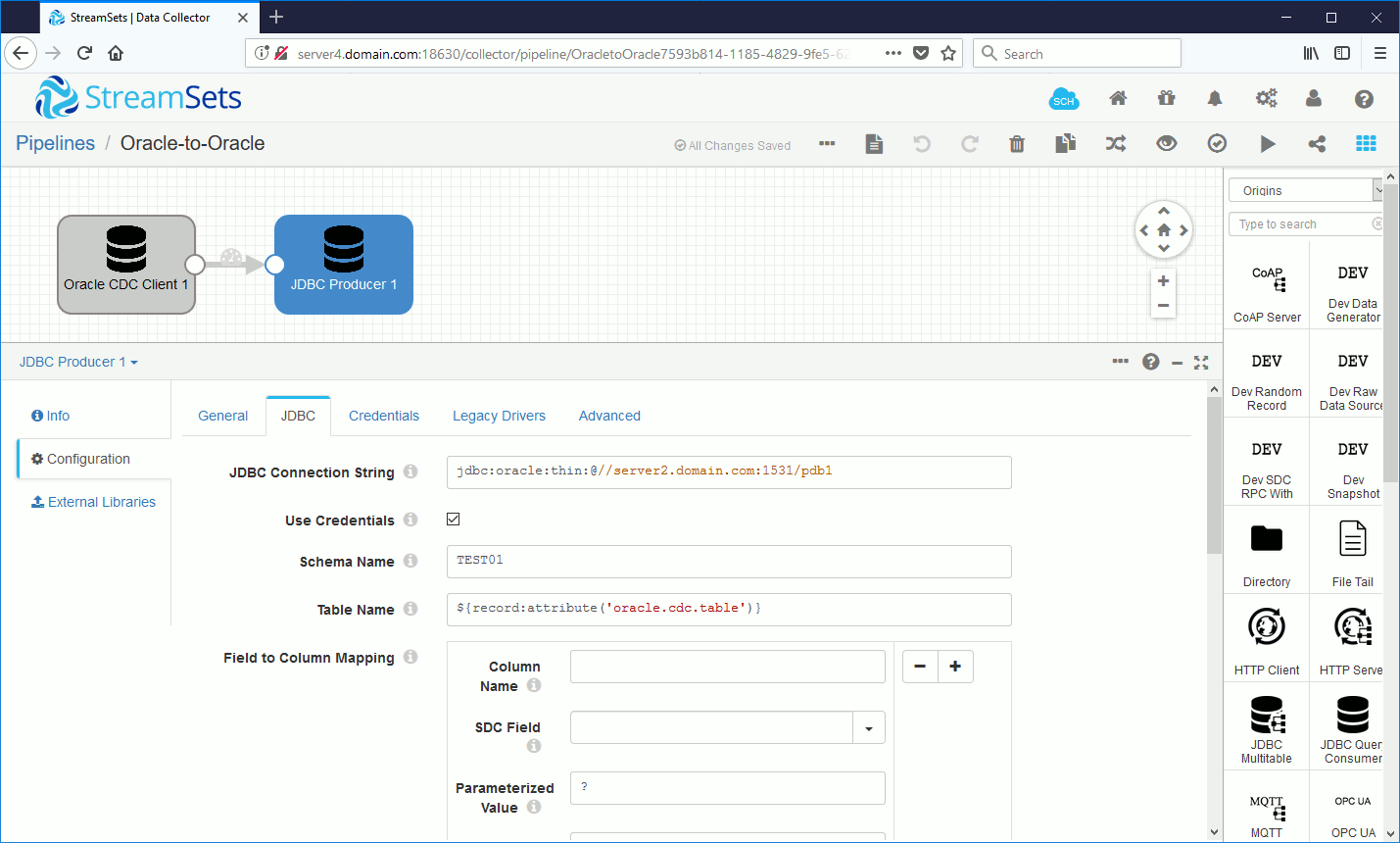
Local pluggable database user to connect with:
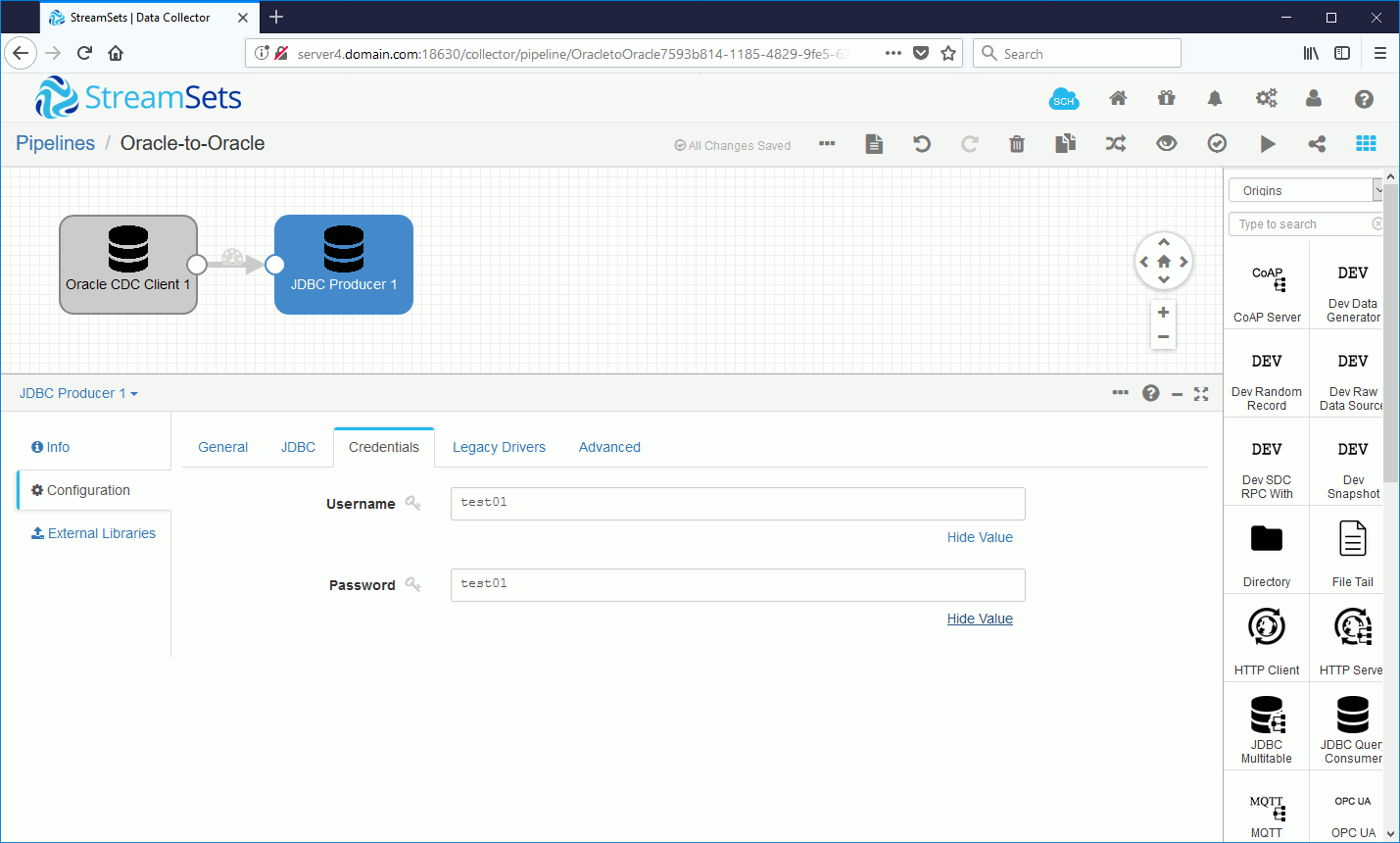
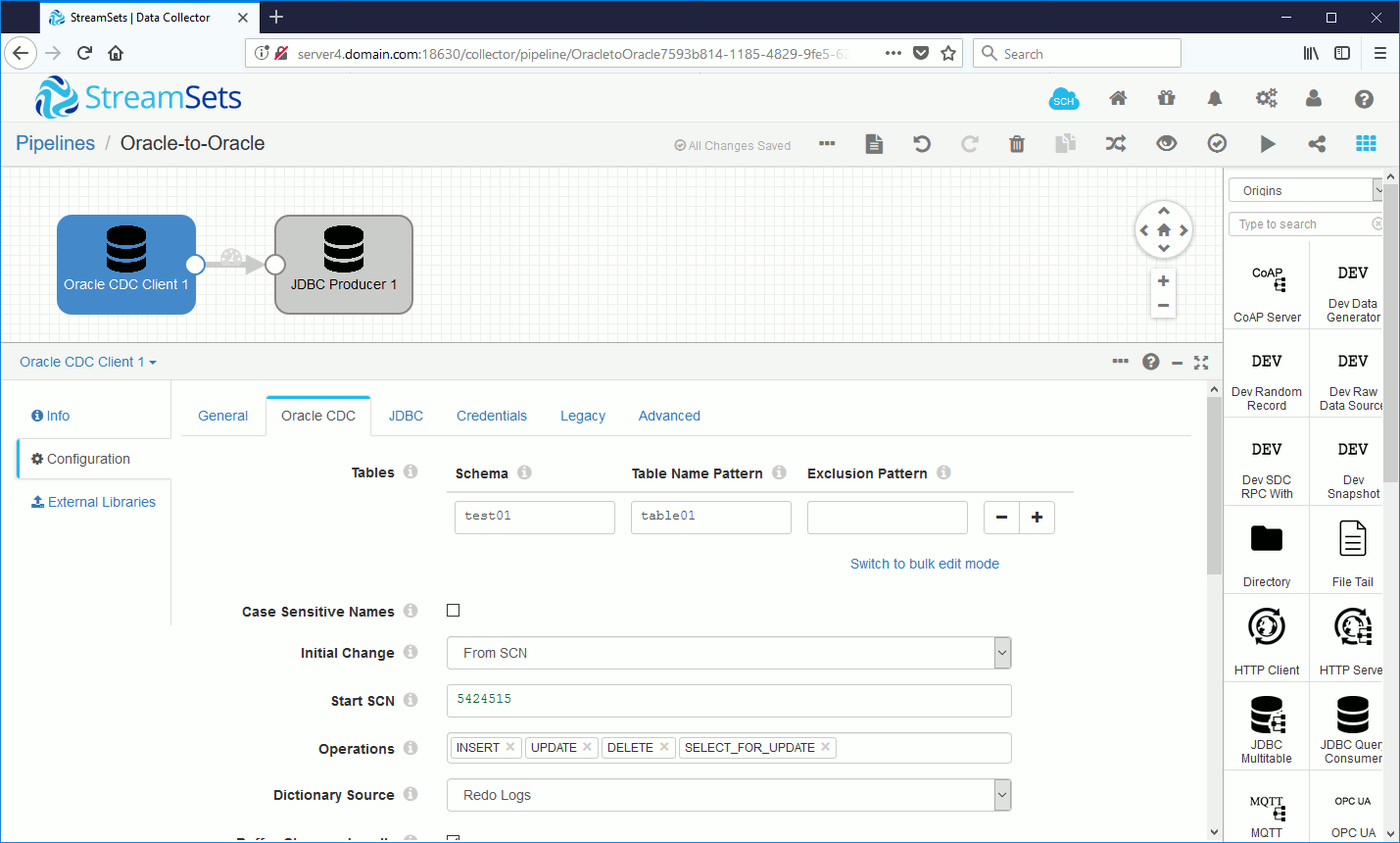
In StreamSets configuration I change Oracle CDC Client configuration to instruct to start at a particular SCN (the one we have extracted above):
StreamSets Data Collector Oracle to Oracle replication testing
Then on source database I can start inserting new figures:
SQL> ALTER SESSION SET container=pdb1; SESSION altered. SQL> INSERT INTO test01.table01 VALUES(3,'Three'); 1 ROW created. SQL> COMMIT; COMMIT complete. |
And you should see them on target database as well as having a nice monitoring screen of the pipeline:
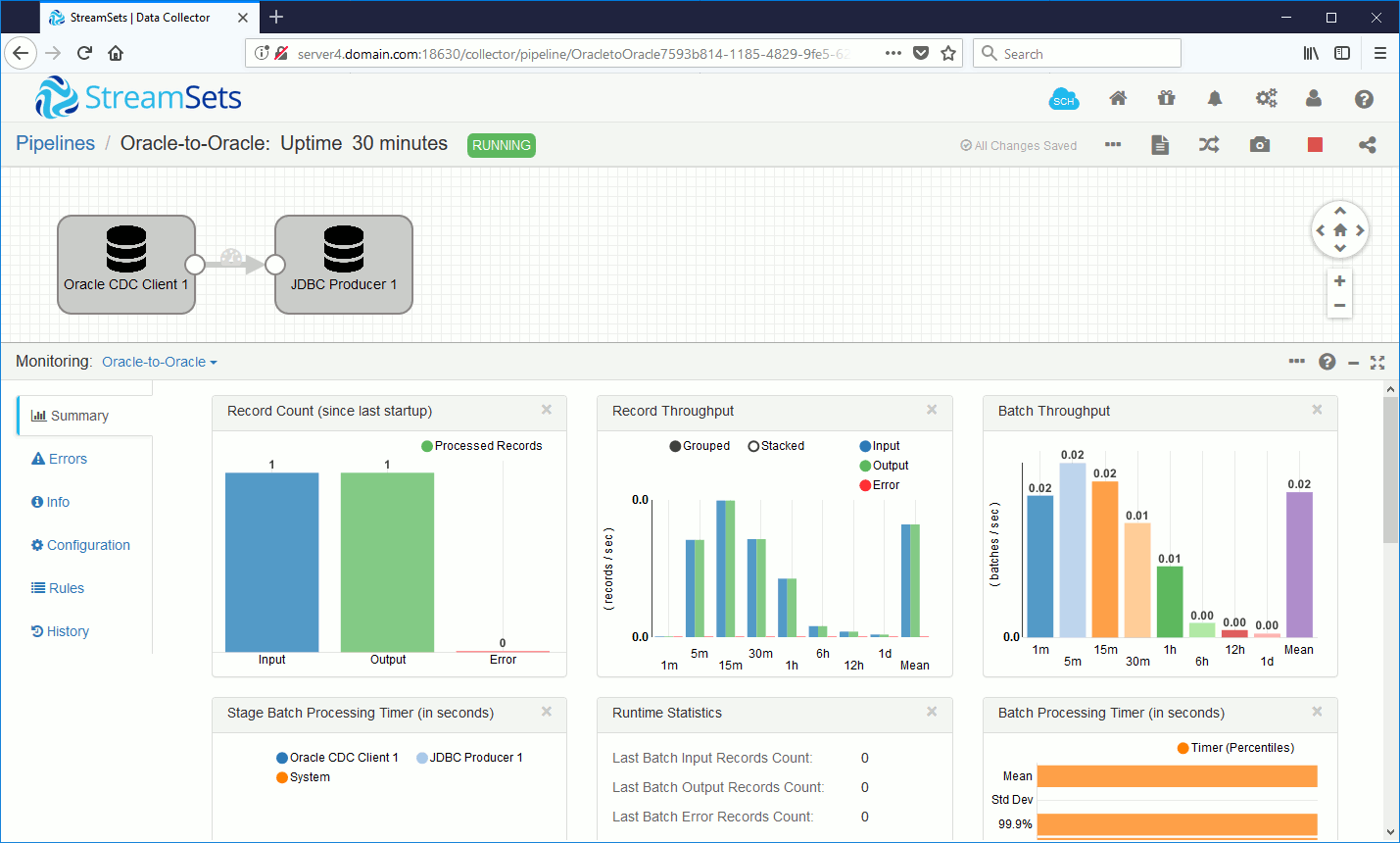
Then to generate a bit of traffic I have used below PL/SQL script (number of inserted rows is up to you and I have personally done multiple test):
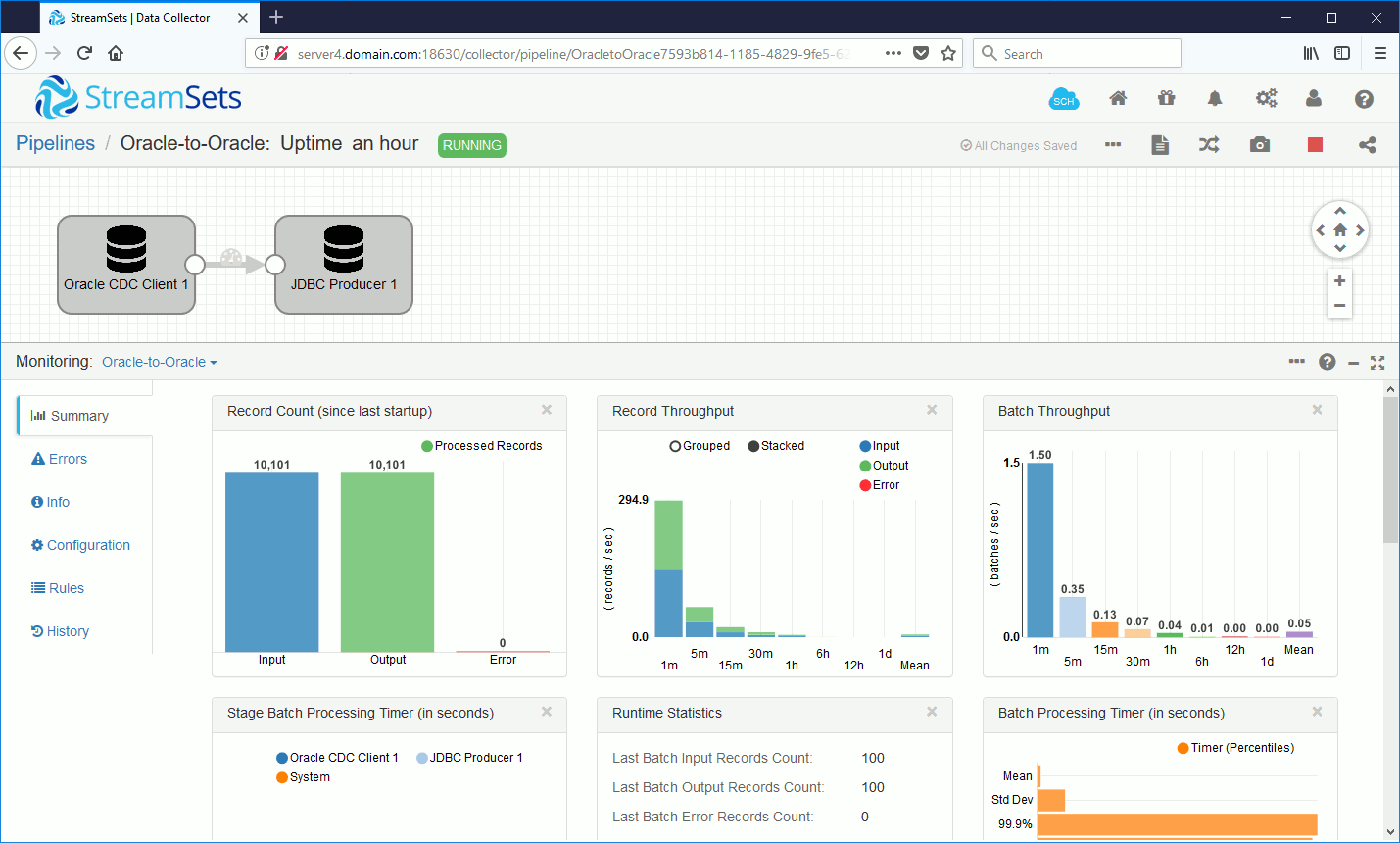
DECLARE max_id NUMBER; i NUMBER; inserted_rows NUMBER:=10000; BEGIN SELECT MAX(id) INTO max_id FROM test01.table01; i:=max_id+1; LOOP INSERT INTO test01.table01 VALUES(i,dbms_random.string('U', 20)); COMMIT; i:=i+1; EXIT WHEN i>max_id + inserted_rows; END LOOP; END; / |
And if you capture the monitoring screen while it’s running you should be able to see transfer rate figures:
StreamSets Data Collector Oracle to JSON file generation
In this extra testing I wanted to test the capability on top of JDBC insertion in a target Oracle database the capability to generate a JSON file. I have started by adding a new destination called Local FS and then draw with the mouse in the GUI interface a new line between the Oracle CDC Client and the Local FS. The only parameter I have changed is generated Data Format as classical JSON:
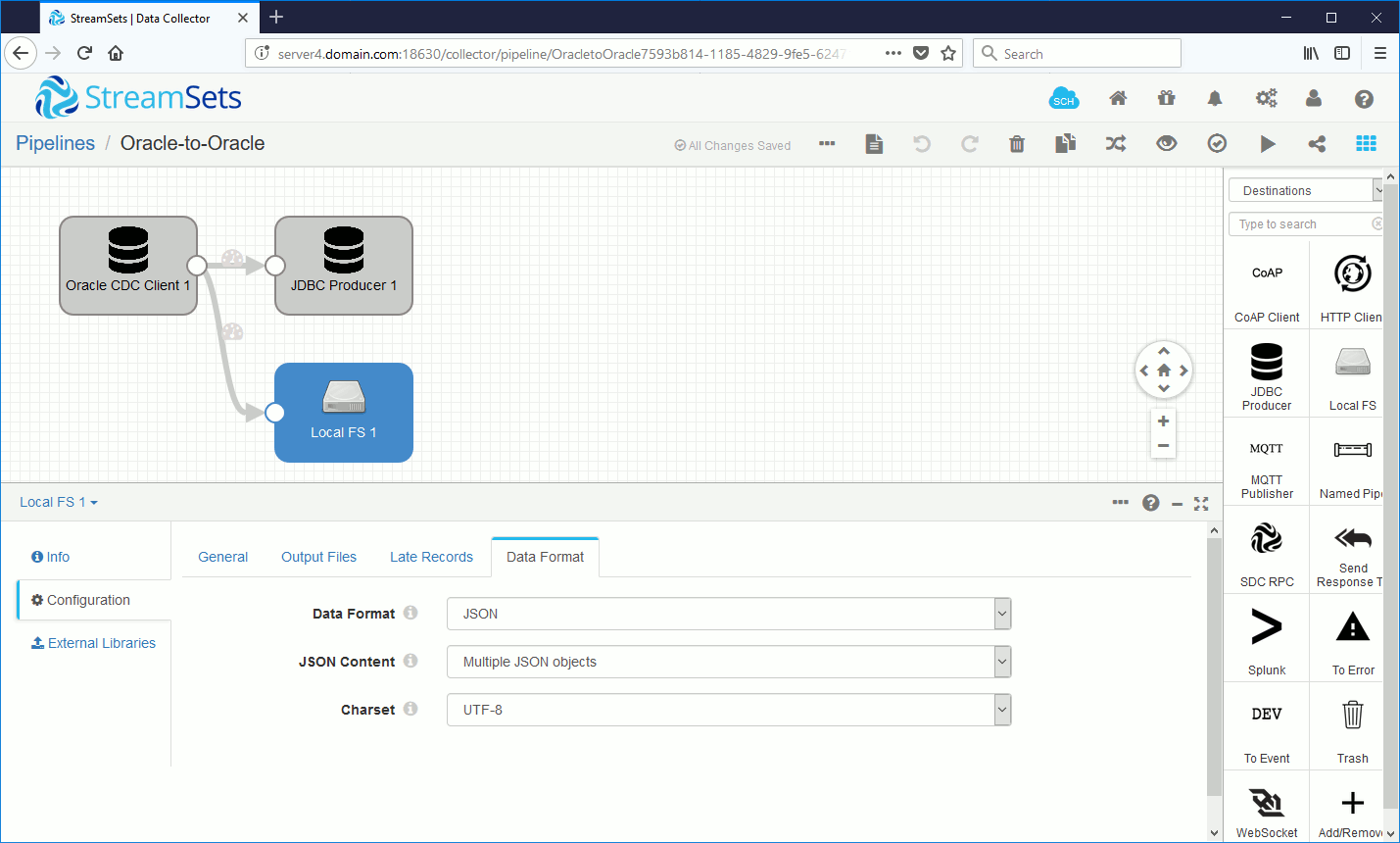
Once I insert a row in source table (I have restarted from an empty table) the record is duplicated in:
- The same target Oracle database, same as above.
- A text file, on StreamSets Data Collector server, in JSON format.
We can see the output generated records is equal to two:
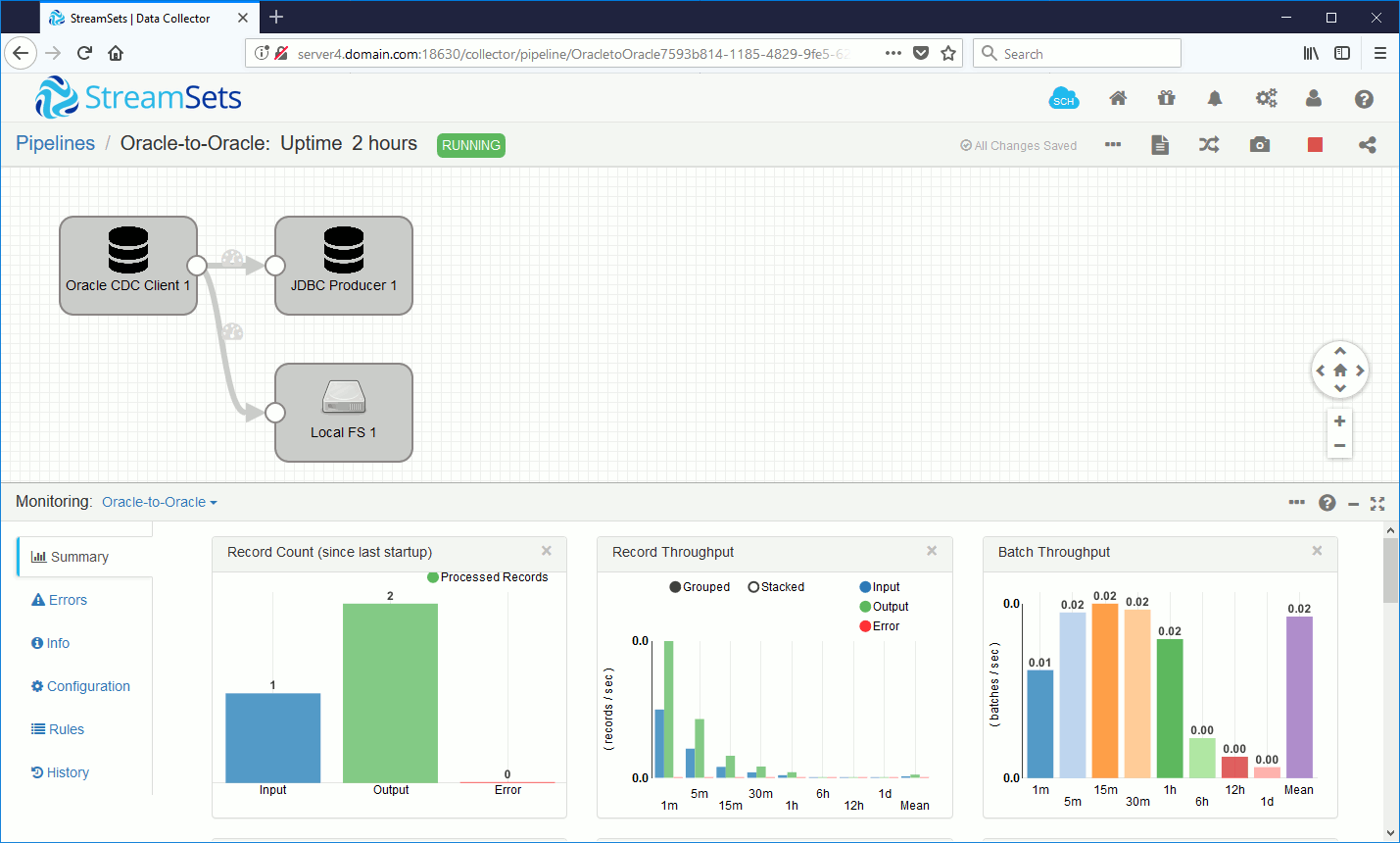
The output file (located on server where StreamSets Data Collector is running i.e. server4.domain.com):
[root@server4 ~]# cat /tmp/out/2018-09-11-15/_tmp_sdc-2622d297-ac69-11e8-bf06-e301dabcb2ba_0 {"ID":1,"DESCR":"One"} |
StreamSets Data Collector Oracle to MySQL replication
I have obviously created a small MySQL 8 instance. I have used my personal account to connect to it and created a test01 database to map schema name of source Oracle pluggable database:
mysql> create user 'yjaquier'@'%' identified by 'secure_password'; Query OK, 0 rows affected (0.31 sec) mysql> grant all privileges on *.* to 'yjaquier'@'%' with grant option; Query OK, 0 rows affected (0.33 sec) |
mysql> create database if not exists test01 -> CHARACTER SET = utf32 -> COLLATE = utf32_general_ci; Query OK, 1 row affected (0.59 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | test01 | +--------------------+ 5 rows in set (0.00 sec) |
I create the target table same as the one of source Oracle table:
mysql> create table test01.table01 ( -> id int not null, -> descr varchar(50) null, -> primary key (id)); Query OK, 0 rows affected (1.30 sec) |
Remark:
I have started from an empty table, but if it’s not the case then an export and an import of pre-existing figures should be handle…
The JDBC connect string for MySQL is (3322 is my MySQL listening port):
jdbc:mysql://server2.domain.com:3322 |
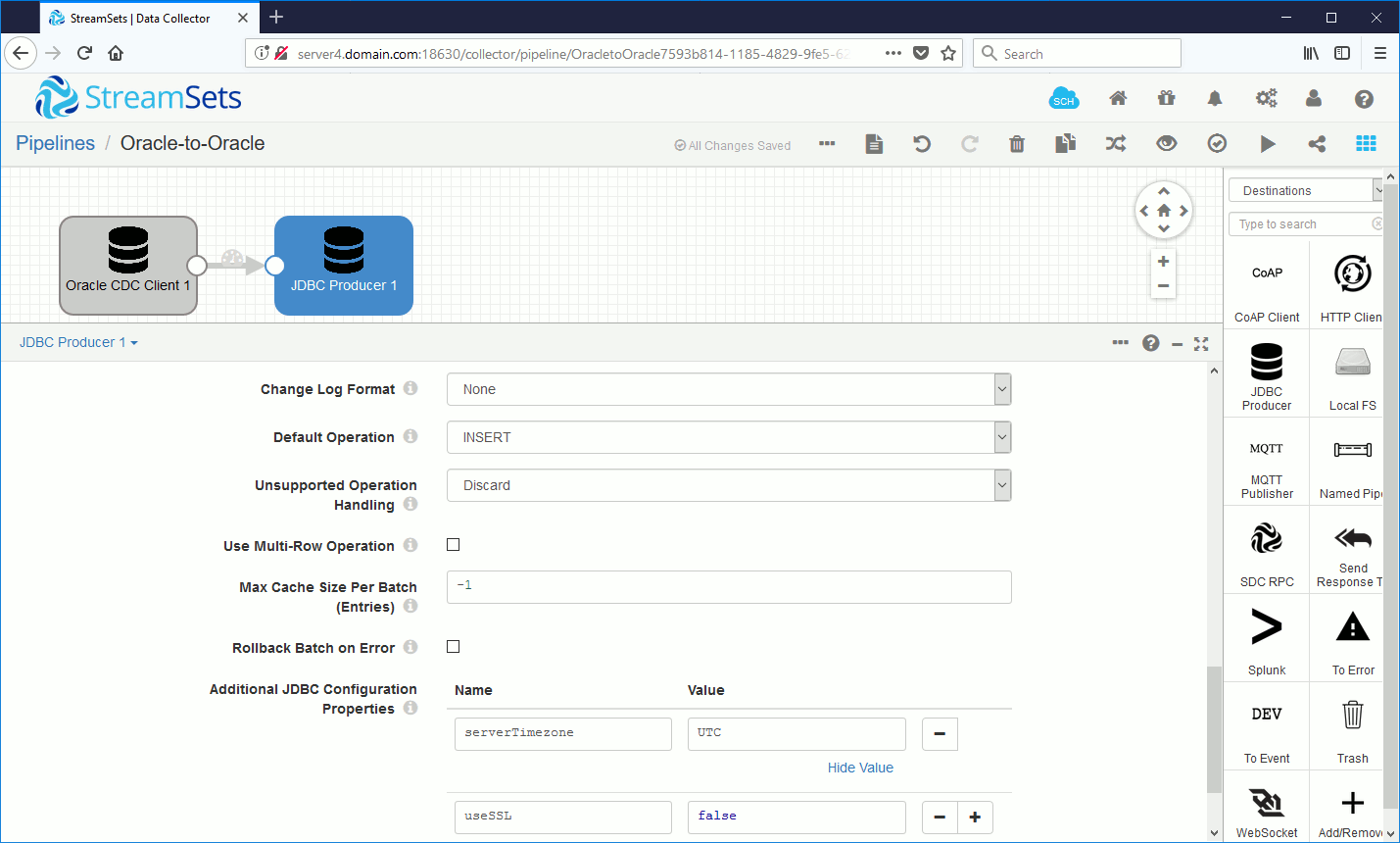
I have also set two below JDBC parameters (see Errors encountered section):
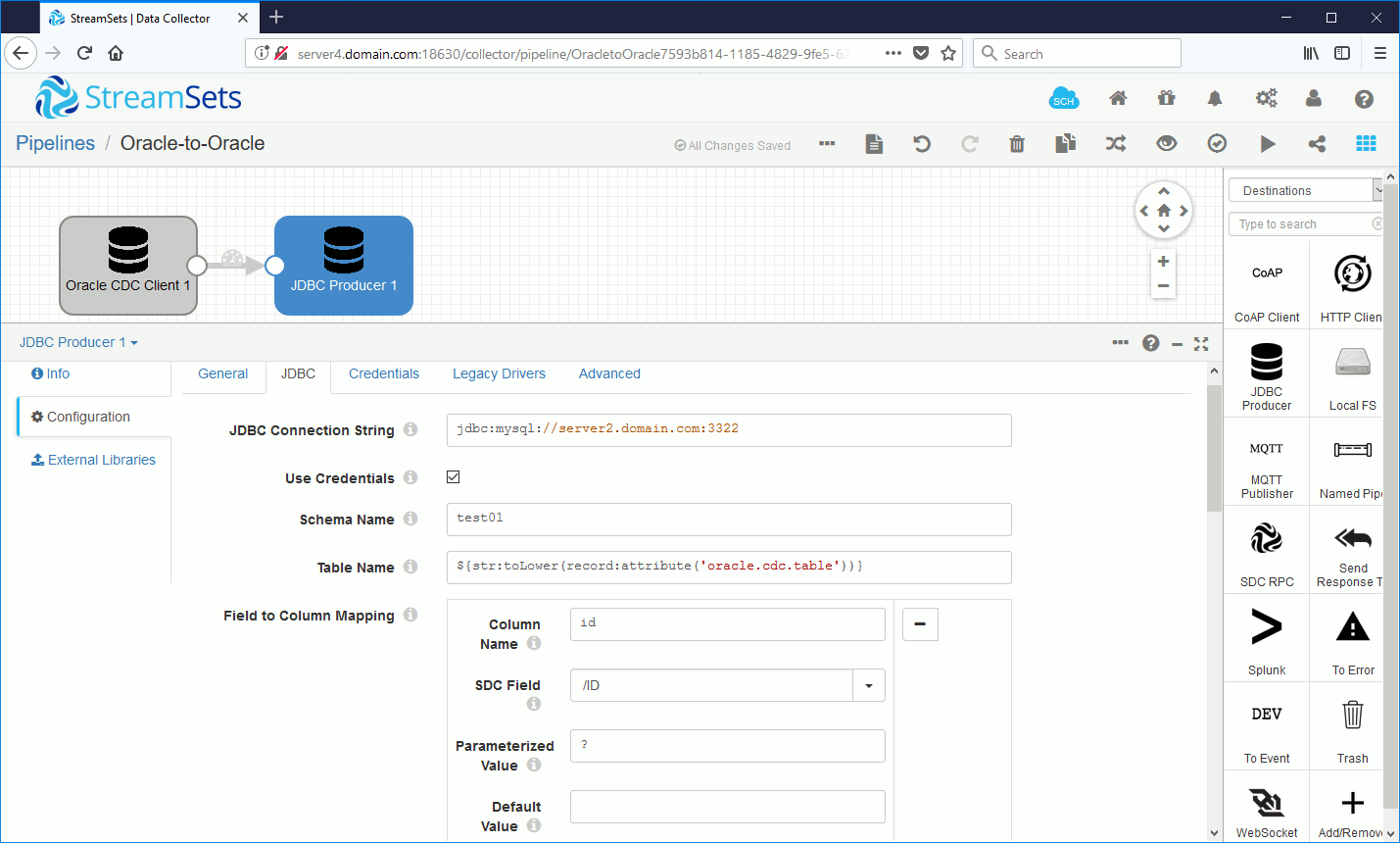
The Schema Name parameter for MySQL must be inserted in lower case so test01 in my case and Table Name must also be in lowercase so use below formula (str:toLower function) to convert uppercase Oracle table name to lower case:
${str:toLower(record:attribute('oracle.cdc.table'))} |
Finally records have also been inserted in MySQL target table:
mysql> select * from test01.table01; +----+-------+ | id | descr | +----+-------+ | 1 | One | | 2 | Two | | 3 | Three | +----+-------+ 3 rows in set (0.00 sec) |
Errors encountered
JDBC_52 – Error starting LogMiner
In sdc.log or in View Logs of interface file you should see something like:
LOGMINER - CONTINUOUS_MINE - failed to add logfile /u01/app/oracle/oradata/ORCL/arch/1_4_983097959.dbf because of status 1284 2018-08-07T17:19:02.844615+02:00 |
It was a mistake from my side where I have deleted archived log file directly on disk. Recovered the situation with:
RMAN> crosscheck archivelog all; released channel: ORA_DISK_1 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=277 device type=DISK validation failed for archived log archived log file name=/u01/app/oracle/oradata/ORCL/arch/1_4_983097959.dbf RECID=1 STAMP=983191889 validation failed for archived log . . RMAN> list archivelog all; using target database control file instead of recovery catalog List of Archived Log Copies for database with db_unique_name ORCL ===================================================================== Key Thrd Seq S Low Time ------- ---- ------- - --------- 1 1 4 X 02-AUG-18 Name: /u01/app/oracle/oradata/ORCL/arch/1_4_983097959.dbf . . RMAN> delete noprompt expired archivelog all; allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=271 device type=DISK List of Archived Log Copies for database with db_unique_name ORCL ===================================================================== Key Thrd Seq S Low Time ------- ---- ------- - --------- 1 1 4 X 02-AUG-18 Name: /u01/app/oracle/oradata/ORCL/arch/1_4_983097959.dbf |
I also had the brother of above one with:
JDBC_44 - Error while getting changes due to error: com.streamsets.pipeline.api.StageException: JDBC_52 - Error starting LogMiner |
It was simply because no archived log file was containing a dictionary log. This can happen when you purge archived log files. Generate one with:
SQL> execute dbms_logmnr_d.build(options=> dbms_logmnr_d.store_in_redo_logs); PL/SQL procedure successfully completed. |
JDBC_44 – Error while getting changes due to error: java.sql.SQLRecoverableException: Closed Connection: getBigDecimal
When validating pipeline I got:
JDBC_44 - Error while getting changes due to error: java.sql.SQLRecoverableException: Closed Connection: getBigDecimal |
And found in sdc.log file below error:
2018-08-31 10:53:35,754 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:] [thread:preview-pool-1-thread-4] WARN OracleCDCSource - Error while stopping LogMiner java.sql.SQLRecoverableException: Closed Connection |
From what I have seen around it looks like my test server is too slow and if you get this you might need to increase the timeout parameters in Advanced tab of Oracle CDC client…
ORA-01291: missing logfile
This one has kept me busy for a while:
106856c0-Oracle-to-Oracle] INFO JdbcUtil - Driver class oracle.jdbc.OracleDriver (version 18.3) 2018-09-03 17:50:48,069 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:0] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-6247 106856c0-Oracle-to-Oracle] INFO HikariDataSource - HikariPool-1 - is starting. 2018-09-03 17:50:49,354 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-62471 06856c0-Oracle-to-Oracle] INFO OracleCDCSource - Trying to start LogMiner with start date: 31-08-2018 10:40:33 and end date: 31-08-2018 12:40:33 2018-09-03 17:50:49,908 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-62471 06856c0-Oracle-to-Oracle] ERROR OracleCDCSource - SQLException while trying to setup record generator thread java.sql.SQLException: ORA-01291: missing logfile ORA-06512: at "SYS.DBMS_LOGMNR", line 58 ORA-06512: at line 1 at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:494) at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:446) at oracle.jdbc.driver.T4C8Oall.processError(T4C8Oall.java:1052) at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:537) at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:255) at oracle.jdbc.driver.T4C8Oall.doOALL(T4C8Oall.java:610) at oracle.jdbc.driver.T4CCallableStatement.doOall8(T4CCallableStatement.java:249) at oracle.jdbc.driver.T4CCallableStatement.doOall8(T4CCallableStatement.java:82) at oracle.jdbc.driver.T4CCallableStatement.executeForRows(T4CCallableStatement.java:924) at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1136) at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement. |
One of the reason I have identified is because StreamSets start LogMiner two hours in the past even when you choose from latest changes:
2018-08-31 12:53:00,846 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-62471 06856c0-Oracle-to-Oracle] INFO OracleCDCSource - Trying to start LogMiner with start date: 31-08-2018 10:40:33 and end date: 31-08-2018 12:40:33 |
I suspect it occurs because Oracle CDC Client LogMiner Session Window parameter is set to 2 hours you must have the archived log files from last 2 hours available when starting the pipeline. So never ever purge archivelog file with:
RMAN> delete noprompt archivelog all; |
But use:
RMAN> delete noprompt archivelog all completed before 'sysdate-3/24'; |
But even when applying this I also noticed StreamSets was always starting LogMiner from the time where the pipeline has failed or when you have stopped it. This is saved in offset.json file:
[root@server4 0]# pwd /streamsets/streamsets-datacollector-3.4.1/data/runInfo/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0/0 [root@server4 0]# ll total 472 -rw-r--r-- 1 streamsets users 100 Sep 3 18:20 offset.json -rw-r--r-- 1 streamsets users 257637 Sep 3 18:20 pipelineStateHistory.json -rw-r--r-- 1 streamsets users 20316 Sep 3 18:20 pipelineState.json [root@server4 0]# cat offset.json { "version" : 2, "offsets" : { "$com.streamsets.datacollector.pollsource.offset$" : "v3::1535715633::3661001::1" } } |
If this is expected and you know what you are doing (first setup, testing, ..) you can reset the pipeline with graphical interface:
Confirm you will not capture what happened in meanwhile:
Which emtpy offset.json file:
[root@server4 0]# cat offset.json { "version" : 2, "offsets" : { } } |
JDBC_16 – Table ” does not exist or PDB is incorrect. Make sure the correct PDB was specified
In JDBC Producer replace for Table Name field:
${record:attribute('tablename')} |
By
${record:attribute('oracle.cdc.table')} |
Then it failed for:
JDBC_16 - Table 'TABLE01' does not exist or PDB is incorrect. Make sure the correct PDB was specified |
In JDBC Producer Errors section I noticed:
oracle.cdc.user: SYS |
Because I inserted the record on master database with SYS account, tried with TEST01 account but failed for exact same error…
Finally found the solution when setting Schema Name field to TEST01, in uppercase, because as suggested in Oracle CDC Client documentation Oracle uses all caps for schema, table, and column names by default.
JDBC_00 – Cannot connect to specified database: com.zaxxer.hikari.pool.PoolInitializationException: Exception during pool initialization: The server time zone value ‘CEST’ is unrecognized or represents more than one time zone.
The full error message also contains:
You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specific time zone value if you want to utilize time zone support. |
I have been obliged to add an additional JDBC property to set server time zone:
serverTimezone = UTC |
Establishing SSL connection without server’s identity verification is not recommended
Thu Sep 13 09:53:39 CEST 2018 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. |
To solve this set in JDBC driver parameters:
useSSL = false |
JdbcGenericRecordWriter – No parameters found for record with ID
Complete error message is:
2018-09-12 15:26:41,696 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:0] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-6247 106856c0-Oracle-to-Oracle] WARN JdbcGenericRecordWriter - No parameters found for record with ID 0x0000bc.0001bec8.0018 ::0; skipping 2018-09-12 15:41:31,650 [user:*admin] [pipeline:Oracle-to-Oracle/OracletoOracle7593b814-1185-4829-9fe5-6247106856c0] [runner:0] [thread:ProductionPipelineRunnable-OracletoOracle7593b814-1185-4829-9fe5-6247 106856c0-Oracle-to-Oracle] WARN JdbcGenericRecordWriter - No parameters found for record with ID 0x0000bd.000057e7.0010 ::1; skipping |
For Oracle to MySQL replication I had to manually do column mapping explicitly like this:
References
- Change Data Capture from Oracle with StreamSets Data Collector
- Oracle Database 18c (18.3) JDBC driver
- Data Collector User Guide
- StreamSets Documentation


Pat Patterson says:
Wow – really great job – very comprehensive! With your permission, I’d like to repost this as a guest post (attributed to you, of course) in the StreamSets blog. Would that be ok with you?
Yannick Jaquier says:
Thanks for nice comment !! And yes, of course, you are more than welcome to share on StreamSets blog !!