Table of contents
Preamble
How to find index rebuild contenders ? I usually get this question around four times a year ! The always working answer is: when you have deleted many rows from source table. Obviously if you delete many rows from source table the under line index will have its leaf blocks getting empty and so will benefit from a rebuild. Well to be honest benefit from a rebuild if you do not insert back those rows in source table or if you insert new rows with a different key (related to the index). Okay but how do we know how much leaf empty blocks have been created and how much space would we gain by rebuilding the index ?
The legacy method is based on SQL command:
ANALYZE INDEX ... VALIDATE structure; |
Which has the bad idea to set an exclusive lock on base table and so forbid any DML. As this method was quite intrusive it has rarely been used on production databases… Despite this you still have plenty of references still suggesting this method that, in my opinion, you must avoid !
Looking a bit of the subject the newest and non intrusive methods are now based on the Oracle estimation of the index size versus the size it currently has. Some more advanced methods are also now displaying the index distribution that could give you an insight of the quality of the index and if you should consider to rebuild it or not.
Legacy situation
Start by analyzing validate structure the index, again this is intrusive command that is forbidding any DML on source table:
SQL> ANALYZE INDEX <owner>.<INDEX name> VALIDATE structure; INDEX <owner>.<INDEX name> analyzed. |
Then you have access to a table called INDEX_STATS. The interesting columns are HEIGHT for index height (number of blocks required to go from the root block to a leaf block), LF_ROWS for the number of leaf rows (values in the index) and DEL_LF_ROWS for the number of deleted leaf rows in the index. The seen everywhere formula is to rebuild index when its height is greater than 3 or percentage of leaf rows deleted is greater than 20%. So here is the query:
SQL> SET lines 200 SQL> col name FOR a30 SQL> SELECT name, height, ROUND(del_lf_rows*100/lf_rows,4) AS percentage FROM index_stats; NAME HEIGHT PERCENTAGE ------------------------------ ---------- ---------- <INDEX name> 4 .0006 |
But again this is clearly a method to avoid nowadays…
Newest methods to estimate indexes size
Current methods are all coming from the feature of well known EXPLAIN PLAN command for DDL. Explaining the DDL of a create index command will feedback the estimated sire of the index. Let’s apply it to my existing index but you can also use it for an index you have not yet created. Get the DDL of your index using DBMS_METADATA.GET_DDL function:
SQL> SET LONG 1000 SQL> SELECT dbms_metadata.get_ddl('INDEX', '<index name>', '<owner>') AS ddl FROM dual; DDL -------------------------------------------------------------------------------- CREATE INDEX <owner>.<INDEX name> ON <owner>.<TABLE name> ("SO_SUB_ITEM__ID", "SO_PENDING_CAUSE__CODE") PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS NOLOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE <TABLESPACE name> |
Then explain create index statement and display related explain plan:
SQL> SET lines 150 SQL> EXPLAIN PLAN FOR 2 CREATE INDEX <owner>.<INDEX name> 3 ON <owner>.<TABLE name> (<COLUMN 1>, <COLUMN 2>) 4 PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS NOLOGGING 5 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 6 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 7 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) 8 TABLESPACE <TABLESPACE name>; Explained. SQL> SELECT * FROM TABLE(dbms_xplan.display); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------ PLAN hash VALUE: 1096024652 --------------------------------------------------------------------------------------------------- | Id | Operation | Name | ROWS | Bytes | COST (%CPU)| TIME | --------------------------------------------------------------------------------------------------- | 0 | CREATE INDEX STATEMENT | | 74M| 1419M| 156K (1)| 00:00:07 | | 1 | INDEX BUILD NON UNIQUE| <INDEX name> | | | | | | 2 | SORT CREATE INDEX | | 74M| 1419M| | | | 3 | TABLE ACCESS FULL | <TABLE name> | 74M| 1419M| 85097 (1)| 00:00:04 | --------------------------------------------------------------------------------------------------- PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------ Note ----- - estimated INDEX SIZE: 2617M bytes 14 ROWS selected. |
And what do we see at the end of the explain plan: estimated index size: 2617M bytes. Oracle is telling us the size the index would take on disk !
Since Oracle 10gR1 since has been wrapped in a procedure of DBMS_SPACE, so you got this all in one using DBMS_SPACE.CREATE_INDEX_COST procedure.
I have create below script taking owner and index name as parameters (create_index_cost.sql):
SET linesize 200 pages 1000 SET serveroutput ON SIZE 999999 SET verify off SET feedback off DECLARE used_bytes NUMBER; alloc_bytes NUMBER; FUNCTION format_size(value1 IN NUMBER) RETURN VARCHAR2 AS BEGIN CASE WHEN (value1>1024*1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024*1024),'999,999.999') || 'GB'); WHEN (value1>1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024),'999,999.999') || 'MB'); WHEN (value1>1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024),'999,999.999') || 'KB'); ELSE RETURN LTRIM(TO_CHAR(value1,'999,999.999') || 'B'); END CASE; END format_size; BEGIN dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('----------------- DBMS_SPACE.CREATE_INDEX_COST -----------------'); dbms_output.put_line('----------------------------------------------------------------'); dbms_space.create_index_cost(dbms_metadata.get_ddl('INDEX', UPPER('&2.'), UPPER('&1.')), used_bytes, alloc_bytes); dbms_output.put_line('Used: ' || format_size(used_bytes)); dbms_output.put_line('Allocated: ' || format_size(alloc_bytes)); END; / SET feedback ON |
It gives:
SQL> @create_index_cost <owner> <INDEX name> ---------------------------------------------------------------- ----------------- DBMS_SPACE.CREATE_INDEX_COST ----------------- ---------------------------------------------------------------- Used: 1.386GB Allocated: 2.438GB |
From official documentation:
- used_bytes: The number of bytes representing the actual index data
- alloc_bytes: Size of the index when created in the tablespace
So as we can see not an exactly byte to byte equivalence, 2617MB for EXPLAIN PLAN command and 2.438GB (2496MB) for DBMS_SPACE.CREATE_INDEX_COST procedure. But the procedure is far simpler to use !
In My Oracle Support (MOS) note Script to investigate a b-tree index structure (Doc ID 989186.1) Oracle claim they use undocumented SYS_OD_LBID instead of ANALYZE INDEX … VALIDATE STRUCTURE command. But looking deeper into their script, SYS_OP_LBID usage is for something completely and in fact they do not use it to list indexes that might benefit from rebuild. We will see SYS_OP_LBID function in a later chapter of this blog post.
Taking only the size estimate part of MOS note 989186.1 and modifying it to take only two parameters which would be index owner and index name it could become something like (inspect_index.sql):
SET linesize 200 pages 1000 SET serveroutput ON SIZE 999999 SET verify off SET feedback off DECLARE vtargetuse CONSTANT POSITIVE := 90; -- equates to pctfree 10 vleafestimate NUMBER; vblocksize NUMBER; voverhead NUMBER := 192; -- leaf block "lost" space in index_stats vpartitioned dba_indexes.partitioned%TYPE; vtable_owner dba_indexes.table_owner%TYPE; vtable_name dba_indexes.table_name%TYPE; vleaf_blocks dba_indexes.leaf_blocks%TYPE; vtablespace_name dba_tablespaces.tablespace_name%TYPE; vpartition_name dba_ind_partitions.partition_name%TYPE; cursor01 SYS_REFCURSOR; CURSOR cursor02 (vblocksize NUMBER, vtable_owner VARCHAR2, vtable_name VARCHAR2, vleaf_blocks NUMBER, vtablespace_name VARCHAR2, vpartition_name VARCHAR2) IS SELECT ROUND(100 / vtargetuse * -- assumed packing efficiency (ind.num_rows * (tab.rowid_length + ind.uniq_ind + 4) + SUM((tc.avg_col_len) * (tab.num_rows) )) -- column data bytes / (vblocksize - voverhead)) index_leaf_estimate FROM (SELECT /*+ no_merge */ table_name, num_rows, DECODE(partitioned,'YES',10,6) rowid_length FROM dba_tables WHERE table_name = vtable_name AND owner = vtable_owner) tab, (SELECT /*+ no_merge */ index_name, index_type, num_rows, DECODE(uniqueness,'UNIQUE',0,1) uniq_ind FROM dba_indexes WHERE table_owner = vtable_owner AND table_name = vtable_name AND owner = UPPER('&1.') AND index_name = UPPER('&2.')) ind, (SELECT /*+ no_merge */ column_name FROM dba_ind_columns WHERE table_owner = vtable_owner AND table_name = vtable_name AND index_owner = UPPER('&1.') AND index_name = UPPER('&2.')) ic, (SELECT /*+ no_merge */ column_name, avg_col_len FROM dba_tab_cols WHERE owner = vtable_owner AND table_name = vtable_name) tc WHERE tc.column_name = ic.column_name GROUP BY ind.num_rows, ind.uniq_ind, tab.rowid_length; CURSOR cursor03 (vblocksize NUMBER, vtable_owner VARCHAR2, vtable_name VARCHAR2, vleaf_blocks NUMBER, vtablespace_name VARCHAR2, vpartition_name VARCHAR2) IS SELECT ROUND(100 / vtargetuse * -- assumed packing efficiency (ind.num_rows * (tab.rowid_length + ind.uniq_ind + 4) + SUM((tc.avg_col_len) * (tab.num_rows) )) -- column data bytes / (vblocksize - voverhead)) index_leaf_estimate FROM (SELECT /*+ no_merge */ a.table_name, b.num_rows, DECODE(a.partitioned,'YES',10,6) rowid_length FROM dba_tables a, dba_tab_partitions b WHERE b.partition_name = vpartition_name AND a.table_name = b.table_name AND a.owner = b.table_owner AND a.table_name = vtable_name AND a.owner = vtable_owner) tab, (SELECT /*+ no_merge */ a.index_name, a.index_type, b.num_rows, DECODE(a.uniqueness,'UNIQUE',0,1) uniq_ind FROM dba_indexes a, dba_ind_partitions b WHERE b.partition_name = vpartition_name AND a.table_owner = vtable_owner AND a.table_name = vtable_name AND a.index_name = b.index_name AND a.owner = b.index_owner AND a.owner = UPPER('&1.') AND a.index_name = UPPER('&2.')) ind, (SELECT /*+ no_merge */ column_name FROM dba_ind_columns WHERE table_owner = vtable_owner AND table_name = vtable_name AND index_owner = UPPER('&1.') AND index_name = UPPER('&2.')) ic, (SELECT /*+ no_merge */ column_name, avg_col_len FROM dba_tab_cols WHERE owner = vtable_owner AND table_name = vtable_name) tc WHERE tc.column_name = ic.column_name GROUP BY ind.num_rows, ind.uniq_ind, tab.rowid_length; vsql VARCHAR2(5000); FUNCTION format_size(value1 IN NUMBER) RETURN VARCHAR2 AS BEGIN CASE WHEN (value1>1024*1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024*1024),'999,999.999') || 'GB'); WHEN (value1>1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024),'999,999.999') || 'MB'); WHEN (value1>1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024),'999,999.999') || 'KB'); ELSE RETURN LTRIM(TO_CHAR(value1,'999,999.999') || 'B'); END CASE; END format_size; BEGIN SELECT partitioned INTO vpartitioned FROM dba_indexes WHERE owner = UPPER('&1.') AND index_name = UPPER('&2.'); IF vpartitioned = 'YES' THEN dbms_output.put_line('This is a partitioned index.'); vsql:='select a.block_size, c.owner, c.table_name, b.leaf_blocks, a.tablespace_name, b.partition_name from dba_tablespaces a, dba_ind_partitions b, dba_part_indexes c where b.index_name = upper(''' || '&2.' || ''') and b.index_owner = upper(''' || '&1.' || ''') and a.tablespace_name = b.tablespace_name and b.index_name = c.index_name and b.index_owner = c.owner'; ELSE dbms_output.put_line('This is a non-partitioned index.'); vsql:='select a.block_size, b.table_owner, b.table_name, b.leaf_blocks, a.tablespace_name, ''N/A'' from dba_tablespaces a, dba_indexes b where b.index_name = upper(''' || '&2.' || ''') and b.owner = upper(''' || '&1.' || ''') and a.tablespace_name = b.tablespace_name'; END IF; OPEN cursor01 FOR vsql; LOOP FETCH cursor01 INTO vblocksize, vtable_owner, vtable_name, vleaf_blocks, vtablespace_name, vpartition_name; EXIT WHEN cursor01%notfound; IF vpartitioned = 'NO' THEN OPEN cursor02(vblocksize, vtable_owner, vtable_name, vleaf_blocks, vtablespace_name, vpartition_name); LOOP FETCH cursor02 INTO vleafestimate; EXIT WHEN cursor02%notfound; dbms_output.put_line('For index ' || UPPER('&1.') || '.' || UPPER('&2.') || ', source table is ' || vtable_owner || '.' || vtable_name); dbms_output.put_line('Index in tablespace ' || vtablespace_name); dbms_output.put_line('Current leaf blocks: ' || vleaf_blocks); dbms_output.put_line('Current size: ' || format_size(vleaf_blocks * vblocksize)); dbms_output.put_line('Estimated leaf blocks: ' || ROUND(vleafestimate,2)); dbms_output.put_line('Estimated size: ' || format_size(vleafestimate * vblocksize)); END LOOP; CLOSE cursor02; ELSE OPEN cursor03(vblocksize, vtable_owner, vtable_name, vleaf_blocks, vtablespace_name, vpartition_name); LOOP FETCH cursor03 INTO vleafestimate; EXIT WHEN cursor03%notfound; dbms_output.put_line('For index ' || UPPER('&1.') || '.' || UPPER('&2.') || ', source table is ' || vtable_owner || '.' || vtable_name); dbms_output.put_line('Index partition ' || vpartition_name || ' in tablespace ' || vtablespace_name); dbms_output.put_line('Current leaf blocks: ' || vleaf_blocks); dbms_output.put_line('Current size: ' || format_size(vleaf_blocks * vblocksize)); dbms_output.put_line('Estimated leaf blocks: ' || ROUND(vleafestimate,2)); dbms_output.put_line('Estimated size: ' || format_size(vleafestimate * vblocksize)); END LOOP; CLOSE cursor03; END IF; END LOOP; CLOSE cursor01; END; / SET feedback ON |
On my test index it gives:
SQL> @inspect_index <owner> <INDEX name> FOR INDEX <owner>.<INDEX name>, source TABLE IS <owner>.<TABLE name> CURRENT leaf blocks: 375382 CURRENT SIZE: 2.864GB Estimated leaf blocks: 335395 Estimated SIZE: 2.559GB |
Which is a third estimation of the size the index would take on disk… But not more explanation of the formula is given by Oracle so difficult to take it as is…
Index rebuild candidates list
Once we have the estimated size (whatever the method) of the index we can compare it with its actual size and see how much we might gain. To compute the current size of an existing index (of course) we have two methods:
- DBMS_SPACE.SPACE_USAGE procedure
- DBA_SEGMENTS view
Of course using DBA_SEGMENTS you are not only taking the real blocks used under the High Water Mark (HWM) but as you can see below it does not make a huge difference for my test index. The script I have written is taking index owner and index name as parameters (index_saving.sql):
SET linesize 200 pages 1000 SET serveroutput ON SIZE 999999 SET verify off SET feedback off DECLARE unformatted_blocks NUMBER; unformatted_bytes NUMBER; fs1_blocks NUMBER; fs1_bytes NUMBER; fs2_blocks NUMBER; fs2_bytes NUMBER; fs3_blocks NUMBER; fs3_bytes NUMBER; fs4_blocks NUMBER; fs4_bytes NUMBER; full_blocks NUMBER; full_bytes NUMBER; dbms_space_bytes NUMBER; bytes_dba_segments NUMBER; used_bytes NUMBER; alloc_bytes NUMBER; vpartitioned dba_indexes.partitioned%TYPE; CURSOR cursor01 IS SELECT NVL(partition_name,'N/A') AS partition_name, bytes AS bytes_dba_segments FROM dba_segments WHERE owner=UPPER('&1.') AND segment_name=UPPER('&2.'); item01 cursor01%ROWTYPE; FUNCTION format_size(value1 IN NUMBER) RETURN VARCHAR2 AS BEGIN CASE WHEN (value1>1024*1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024*1024),'999,999.999') || 'GB'); WHEN (value1>1024*1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024*1024),'999,999.999') || 'MB'); WHEN (value1>1024) THEN RETURN LTRIM(TO_CHAR(value1/(1024),'999,999.999') || 'KB'); ELSE RETURN LTRIM(TO_CHAR(value1,'999,999.999') || 'B'); END CASE; END format_size; BEGIN SELECT partitioned INTO vpartitioned FROM dba_indexes WHERE owner = UPPER('&1.') AND index_name = UPPER('&2.'); dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('Analyzing index &1..&2.'); OPEN cursor01; dbms_space_bytes:=0; bytes_dba_segments:=0; LOOP FETCH cursor01 INTO item01; EXIT WHEN cursor01%notfound; dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('-------------------- DBMS_SPACE.SPACE_USAGE --------------------'); dbms_output.put_line('----------------------------------------------------------------'); IF vpartitioned='NO' THEN dbms_space.space_usage(UPPER('&1.'), UPPER('&2.'), 'INDEX', unformatted_blocks, unformatted_bytes, fs1_blocks, fs1_bytes, fs2_blocks, fs2_bytes, fs3_blocks, fs3_bytes, fs4_blocks, fs4_bytes, full_blocks, full_bytes); ELSE dbms_output.put_line('Index partition: ' || item01.partition_name); dbms_space.space_usage(UPPER('&1.'), UPPER('&2.'), 'INDEX PARTITION', unformatted_blocks, unformatted_bytes, fs1_blocks, fs1_bytes, fs2_blocks, fs2_bytes, fs3_blocks, fs3_bytes, fs4_blocks, fs4_bytes, full_blocks, full_bytes, item01.partition_name); END IF; dbms_output.put_line('Total number of blocks unformatted :' || unformatted_blocks); --dbms_output.put_line('Total number of bytes unformatted: ' || unformatted_bytes); dbms_output.put_line('Number of blocks having at least 0 to 25% free space: ' || fs1_blocks); --dbms_output.put_line('Number of bytes having at least 0 to 25% free space: ' || fs1_bytes); dbms_output.put_line('Number of blocks having at least 25 to 50% free space: ' || fs2_blocks); --dbms_output.put_line('Number of bytes having at least 25 to 50% free space: ' || fs2_bytes); dbms_output.put_line('Number of blocks having at least 50 to 75% free space: ' || fs3_blocks); --dbms_output.put_line('Number of bytes having at least 50 to 75% free space: ' || fs3_bytes); dbms_output.put_line('Number of blocks having at least 75 to 100% free space: ' || fs4_blocks); --dbms_output.put_line('Number of bytes having at least 75 to 100% free space: ' || fs4_bytes); dbms_output.put_line('The number of blocks full in the segment: ' || full_blocks); --dbms_output.put_line('Total number of bytes full in the segment: ' || format_size(full_bytes)); dbms_space_bytes:=dbms_space_bytes + unformatted_bytes + fs1_bytes + fs2_bytes + fs3_bytes + fs4_bytes + full_bytes; dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('------------------------- DBA_SEGMENTS -------------------------'); dbms_output.put_line('----------------------------------------------------------------'); --select bytes into bytes_dba_segments from dba_segments where owner=upper('&1.') and segment_name=upper('&2.'); dbms_output.put_line('Size of the segment: ' || format_size(item01.bytes_dba_segments)); bytes_dba_segments:=bytes_dba_segments + item01.bytes_dba_segments; END LOOP; CLOSE cursor01; dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('----------------- DBMS_SPACE.CREATE_INDEX_COST -----------------'); dbms_output.put_line('----------------------------------------------------------------'); dbms_space.create_index_cost(dbms_metadata.get_ddl('INDEX', UPPER('&2.'), UPPER('&1.')), used_bytes, alloc_bytes); dbms_output.put_line('Used: ' || format_size(used_bytes)); dbms_output.put_line('Allocated: ' || format_size(alloc_bytes)); dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('---------------------------- Results ---------------------------'); dbms_output.put_line('----------------------------------------------------------------'); dbms_output.put_line('Potential percentage gain (DBMS_SPACE): ' || ROUND(100 * (dbms_space_bytes - alloc_bytes) / dbms_space_bytes) || '%'); dbms_output.put_line('Potential percentage gain (DBA_SEGMENTS): ' || ROUND(100 * (bytes_dba_segments - alloc_bytes) / bytes_dba_segments) || '%'); END; / SET feedback ON |
It gives for me:
SQL> @index_saving <owner> <INDEX name> ---------------------------------------------------------------- Analyzing INDEX <owner>.<INDEX name> ---------------------------------------------------------------- -------------------- DBMS_SPACE.SPACE_USAGE -------------------- ---------------------------------------------------------------- Total NUMBER OF blocks unformatted :1022 NUMBER OF blocks HAVING AT LEAST 0 TO 25% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 25 TO 50% free SPACE: 35 NUMBER OF blocks HAVING AT LEAST 50 TO 75% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 75 TO 100% free SPACE: 0 The NUMBER OF blocks full IN the SEGMENT: 365448 ---------------------------------------------------------------- ------------------------- DBA_SEGMENTS ------------------------- ---------------------------------------------------------------- SIZE OF the SEGMENT: 2.803GB ---------------------------------------------------------------- ----------------- DBMS_SPACE.CREATE_INDEX_COST ----------------- ---------------------------------------------------------------- Used: 1.386GB Allocated: 2.438GB ---------------------------------------------------------------- ---------------------------- Results --------------------------- ---------------------------------------------------------------- Potential percentage gain (DBMS_SPACE): 13% Potential percentage gain (DBA_SEGMENTS): 13% |
Let say we chose the DBMS_SPACE method, I have then tried to club this in a function for non-partitioned indexes to be able to analyze multiple indexes of a schema at same time. To handle security problem I have granted to my DBA account:
SQL> GRANT EXECUTE ON dbms_space TO yjaquier; GRANT succeeded. SQL> GRANT EXECUTE ON dbms_metadata TO yjaquier; GRANT succeeded. SQL> GRANT ANALYZE ANY TO yjaquier; GRANT succeeded. |
And DBMS_METADATA as they say in official documentation:
If you want to write a PL/SQL program that fetches metadata for objects in a different schema (based on the invoker’s possession of SELECT_CATALOG_ROLE), you must make the program invokers-rights.
So used the AUTHID CURRENT_USER as invoker’s rights clause:
CREATE OR REPLACE FUNCTION index_saving_function(index_owner IN VARCHAR2, index_name VARCHAR2) RETURN NUMBER AUTHID current_user AS unformatted_blocks NUMBER; unformatted_bytes NUMBER; fs1_blocks NUMBER; fs1_bytes NUMBER; fs2_blocks NUMBER; fs2_bytes NUMBER; fs3_blocks NUMBER; fs3_bytes NUMBER; fs4_blocks NUMBER; fs4_bytes NUMBER; full_blocks NUMBER; full_bytes NUMBER; dbms_space_bytes NUMBER; used_bytes NUMBER; alloc_bytes NUMBER; BEGIN dbms_space.space_usage(UPPER(index_owner), UPPER(index_name), 'INDEX', unformatted_blocks, unformatted_bytes, fs1_blocks, fs1_bytes, fs2_blocks, fs2_bytes, fs3_blocks, fs3_bytes, fs4_blocks, fs4_bytes, full_blocks, full_bytes); dbms_space_bytes:=unformatted_bytes+fs1_bytes+fs2_bytes+fs3_bytes+fs4_bytes+full_bytes; dbms_space.create_index_cost(dbms_metadata.get_ddl('INDEX', UPPER(index_name), UPPER(index_owner)), used_bytes, alloc_bytes); IF (dbms_space_bytes <> 0) THEN RETURN (100 * (dbms_space_bytes - alloc_bytes) / dbms_space_bytes); ELSE RETURN 0; END IF; END; / |
Finally a simple query like this gives a good first analysis of what could be potential candidates for shrink/rebuild:
SELECT owner,index_name,index_saving_function(owner,index_name) AS percentage_gain FROM dba_indexes WHERE owner='<your_owner>' AND last_analyzed IS NOT NULL AND partitioned='NO' ORDER BY 3 DESC; |
To go further
The SYS_OP_LBID internal Oracle function that has been first (I think) shared by Jonathan Lewis and that you can find on plenty of blog post as well as MOS note Script to investigate a b-tree index structure (Doc ID 989186.1) return the leaf block id where is store the source table key that is given by source table rowid parameter of the SYS_OP_LBID function. If you group by the result per leaf block id you get the number of source table keys per leaf block id.
On all the queries shared around the next idea is to order by and group by this number of keys per leaf block and see how much blocks you have to access to get them. The queries using an aggregate function to sum row by row this block required to be read are the best to make an analysis (sys_op_lbid.sql):
SET linesize 200 pages 1000 SET serveroutput ON SIZE 999999 SET verify off SET feedback off DECLARE vsql VARCHAR2(1000); v_id NUMBER; vtable_owner dba_indexes.table_owner%TYPE; vtable_name dba_indexes.table_owner%TYPE; col01 VARCHAR2(50); col02 VARCHAR2(50); col03 VARCHAR2(50); col04 VARCHAR2(50); col05 VARCHAR2(50); col06 VARCHAR2(50); col07 VARCHAR2(50); col08 VARCHAR2(50); col09 VARCHAR2(50); col10 VARCHAR2(50); TYPE IdxRec IS RECORD (keys_per_leaf NUMBER, blocks NUMBER, cumulative_blocks NUMBER); TYPE IdxTab IS TABLE OF IdxRec; l_data IdxTab; BEGIN SELECT object_id INTO v_id FROM dba_objects WHERE owner = UPPER('&1.') AND object_name = UPPER('&2.') AND object_type = 'INDEX'; SELECT table_owner, table_name INTO vtable_owner, vtable_name FROM dba_indexes WHERE owner = UPPER('&1.') AND index_name = UPPER('&2.'); SELECT NVL(MAX(DECODE(column_position, 1,column_name)),'null'), NVL(MAX(DECODE(column_position, 2,column_name)),'null'), NVL(MAX(DECODE(column_position, 3,column_name)),'null'), NVL(MAX(DECODE(column_position, 4,column_name)),'null'), NVL(MAX(DECODE(column_position, 5,column_name)),'null'), NVL(MAX(DECODE(column_position, 6,column_name)),'null'), NVL(MAX(DECODE(column_position, 7,column_name)),'null'), NVL(MAX(DECODE(column_position, 8,column_name)),'null'), NVL(MAX(DECODE(column_position, 9,column_name)),'null'), NVL(MAX(DECODE(column_position, 10,column_name)),'null') INTO col01, col02, col03, col04, col05, col06, col07, col08, col09, col10 FROM dba_ind_columns WHERE table_owner = vtable_owner AND table_name = vtable_name AND index_name = UPPER('&2.') ORDER BY column_position; vsql:='SELECT keys_per_leaf, blocks, SUM(blocks) OVER(ORDER BY keys_per_leaf) cumulative_blocks FROM (SELECT ' || 'keys_per_leaf,COUNT(*) blocks FROM (SELECT /*+ ' || 'cursor_sharing_exact ' || 'dynamic_sampling(0) ' || 'no_monitoring ' || 'no_expand ' || 'index_ffs(' || vtable_name || ',' || '&2.' || ') ' || 'noparallel_index(' || vtable_name || ',' || '&2.' || ') */ ' || 'sys_op_lbid(' || v_id || ',''L'',t1.rowid) AS block_id,' || 'COUNT(*) AS keys_per_leaf ' || 'FROM &1..' || vtable_name ||' t1 ' || 'WHERE ' || col01 || ' IS NOT NULL ' || 'OR ' || col02 || ' IS NOT NULL ' || 'OR ' || col03 || ' IS NOT NULL ' || 'OR ' || col04 || ' IS NOT NULL ' || 'OR ' || col05 || ' IS NOT NULL ' || 'OR ' || col06 || ' IS NOT NULL ' || 'OR ' || col07 || ' IS NOT NULL ' || 'OR ' || col08 || ' IS NOT NULL ' || 'OR ' || col09 || ' IS NOT NULL ' || 'OR ' || col10 || ' IS NOT NULL ' || 'GROUP BY sys_op_lbid('||v_id||',''L'',t1.rowid)) ' || 'GROUP BY keys_per_leaf) ' || 'ORDER BY keys_per_leaf'; --dbms_output.put_line(vsql); EXECUTE IMMEDIATE vsql BULK COLLECT INTO l_data; dbms_output.put_line('KEYS_PER_LEAF BLOCKS CUMULATIVE_BLOCKS'); dbms_output.put_line('------------- ---------- -----------------'); FOR i IN l_data.FIRST..l_data.LAST LOOP dbms_output.put_line(LPAD(l_data(i).keys_per_leaf,13) || ' ' || LPAD(l_data(i).blocks,10) || ' ' || LPAD(l_data(i).cumulative_blocks,17)); END LOOP; END; / SET feedback ON |
Remark:
The SYS_OP_LBID function does not work on index partition (ORA-01760: illegal argument for function) so I had to supply the object_id of the index object itself (object_type=’INDEX’). It also means that executing this script on (big) partitioned tables will take a bit of time and resources…
Then a nice trick is to copy and paste the result in Excel and do a chart on this figures. Doing this you will better see any sudden jump in number of blocks required to read key lea blocks. In a well balanced index the progression should be as much linear as possible:
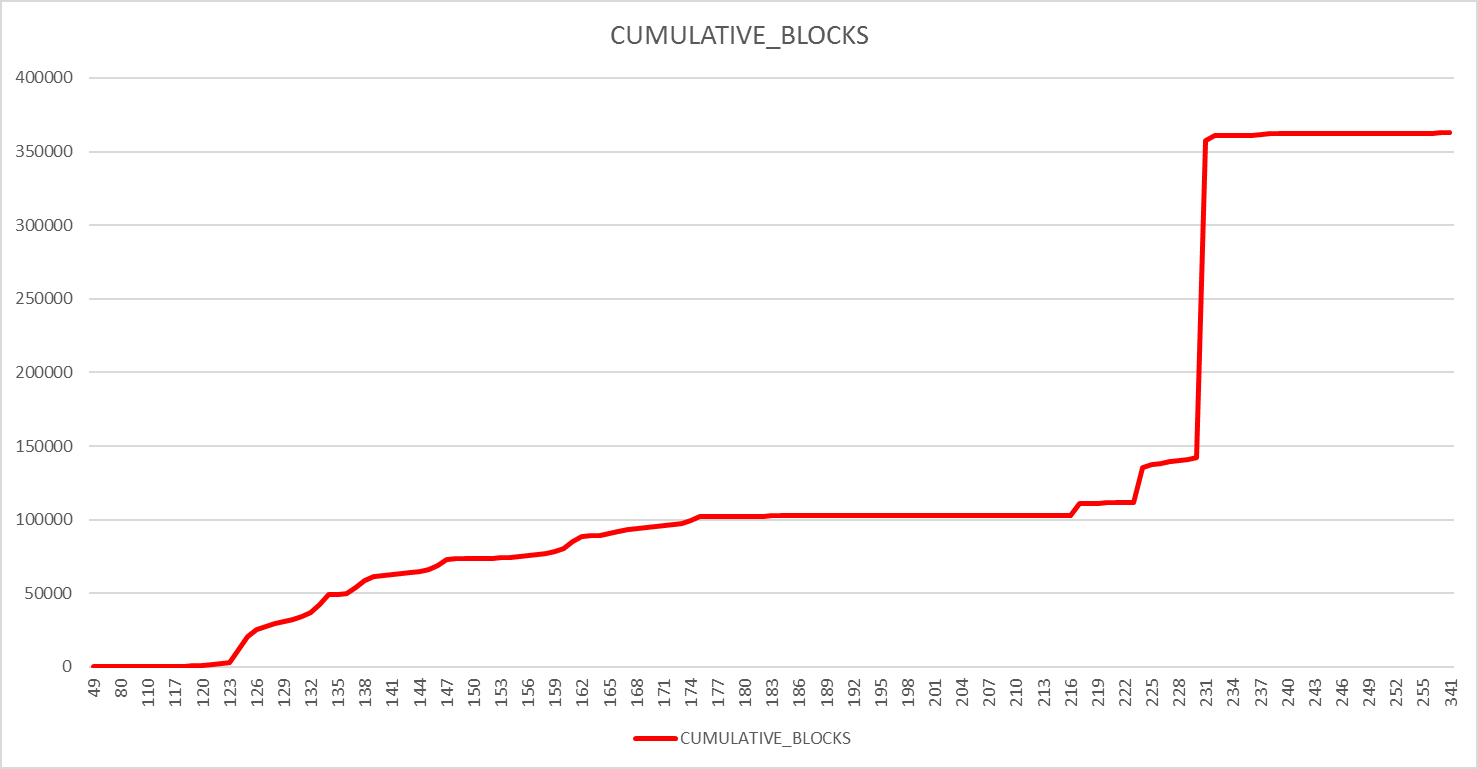
I initially thought that any sudden jump in the number of block required to be read to get the keys is an indication of a index that would benefit from rebuild. But I was wrong (see below why after the index has been rebuilt) ! In this chart what you have to try to identify if the number of cumulative blocks increasing rapidly while the number of keys read is moving slowly. In my chart it start well has number of key read is increasing while number of blocks is flat. But then after number of blocks is constantly increasing while the number of keys read is moving slowly. Said differently the list should be more condensed. The issue is here…
If we are back to the raw figures we see the jump here below:
KEYS_PER_LEAF BLOCKS CUMULATIVE_BLOCKS ------------- ---------- ----------------- . . 117 196 202 118 289 491 119 347 838 120 205 1043 121 502 1545 122 690 2235 123 851 3086 124 9629 12715 125 11104 23819 126 5773 29592 127 1991 31583 128 1148 32731 129 956 33687 130 982 34669 131 1036 35705 132 1946 37651 133 4435 42086 134 6254 48340 135 2265 50605 136 26 50631 137 27 50658 138 30 50688 139 21 50709 140 72 50781 141 57 50838 142 95 50933 143 211 51144 144 483 51627 145 408 52035 . . 228 823 140172 229 795 140967 230 1111 142078 231 215514 357592 232 3212 360804 . . |
Rebuild or shrink ?
One of the drawback of rebuilding an index is that you need double index space on disk, this is also a little bit longer than coalescing it… If you run an enterprise edition of the Oracle database then the ONLINE keyword keep you safe from DML locking.
For an index or index-organized table, specifying ALTER [INDEX | TABLE] … SHRINK SPACE COMPACT is equivalent to specifying ALTER [INDEX | TABLE ] … COALESCE.
Few people have tried to compare REBUIL and SHRINK and draw some conclusions (see references), but to be honest it looks difficult to give precise rules on what to do. If your index is not too much fragmented SHRINK should give good result, if not then you have to go for REBUILD. It also depends on which overhead you would like to put on your database. I have tried both on my test index:
I have firstly tried using SHRINK SPACE COMPACT with very low result and found in Oracle official documentation:
If you specify COMPACT, then Oracle Database only defragments the segment space and compacts the table rows for subsequent release. The database does not readjust the high water mark and does not release the space immediately. You must issue another ALTER TABLE … SHRINK SPACE statement later to complete the operation. This clause is useful if you want to accomplish the shrink operation in two shorter steps rather than one longer step.
Even if they explain COMPACT option only for tables I have feeling that it behaves almost the same for indexes (I have been able to perform multiple tests as my test database got refreshed from live one that remained unchanged):>/p>
SQL> ALTER INDEX <owner>.<INDEX name> shrink SPACE compact; INDEX <owner>.<INDEX name> altered. SQL> @index_saving <owner> <INDEX name> ---------------------------------------------------------------- Analyzing INDEX <owner>.<INDEX name> ---------------------------------------------------------------- -------------------- DBMS_SPACE.SPACE_USAGE -------------------- ---------------------------------------------------------------- Total NUMBER OF blocks unformatted :1022 NUMBER OF blocks HAVING AT LEAST 0 TO 25% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 25 TO 50% free SPACE: 3 NUMBER OF blocks HAVING AT LEAST 50 TO 75% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 75 TO 100% free SPACE: 13865 The NUMBER OF blocks full IN the SEGMENT: 351615 ---------------------------------------------------------------- ------------------------- DBA_SEGMENTS ------------------------- ---------------------------------------------------------------- SIZE OF the SEGMENT: 2.803GB ---------------------------------------------------------------- ----------------- DBMS_SPACE.CREATE_INDEX_COST ----------------- ---------------------------------------------------------------- Used: 1.386GB Allocated: 2.438GB ---------------------------------------------------------------- ---------------------------- Results --------------------------- ---------------------------------------------------------------- Potential percentage gain (DBMS_SPACE): 9% Potential percentage gain (DBA_SEGMENTS): 13% SQL> @inspect_index <owner> <INDEX name> FOR INDEX <owner>.<INDEX name>, source TABLE IS <owner>.<TABLE name> CURRENT leaf blocks: 375382 CURRENT SIZE: 2.864GB Estimated leaf blocks: 335395 Estimated SIZE: 2.559GB SQL> @sys_op_lbid <owner> <INDEX name> KEYS_PER_LEAF BLOCKS CUMULATIVE_BLOCKS ------------- ---------- ----------------- . . 119 10 21 120 8 29 121 18 47 122 36 83 123 34 117 124 522 639 125 537 1176 126 253 1429 127 90 1519 . . 230 1238 91459 231 267907 359366 232 1562 360928 . . |
Does not provide a very good result the index remained almost unchanged ! Without COMPACT keywords (figures slightly different as index evolve on live database:):
SQL> ALTER INDEX <owner>.<INDEX name> shrink SPACE; INDEX <owner>.<INDEX name> altered. SQL> @index_saving <owner> <INDEX name> ---------------------------------------------------------------- Analyzing INDEX <owner>.<INDEX name> ---------------------------------------------------------------- -------------------- DBMS_SPACE.SPACE_USAGE -------------------- ---------------------------------------------------------------- Total NUMBER OF blocks unformatted :0 NUMBER OF blocks HAVING AT LEAST 0 TO 25% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 25 TO 50% free SPACE: 3 NUMBER OF blocks HAVING AT LEAST 50 TO 75% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 75 TO 100% free SPACE: 0 The NUMBER OF blocks full IN the SEGMENT: 368842 ---------------------------------------------------------------- ------------------------- DBA_SEGMENTS ------------------------- ---------------------------------------------------------------- SIZE OF the SEGMENT: 2.821GB ---------------------------------------------------------------- ----------------- DBMS_SPACE.CREATE_INDEX_COST ----------------- ---------------------------------------------------------------- Used: 1.526GB Allocated: 2.688GB ---------------------------------------------------------------- ---------------------------- Results --------------------------- ---------------------------------------------------------------- Potential percentage gain (DBMS_SPACE): 4% Potential percentage gain (DBA_SEGMENTS): 5% |
A bit better without COMPACT keyword, we see that blocks have been de-fragmented but not released and index is still not in its optimal form. Which could be satisfactory versus the load you want to put on your database. let’s try rebuilding it which is a bit more resource consuming:
SQL> ALTER INDEX <owner>.<INDEX name> rebuild ONLINE; INDEX <owner>.<INDEX name> altered. SQL> @index_saving <owner> <INDEX name> ---------------------------------------------------------------- Analyzing INDEX <owner>.<INDEX name> ---------------------------------------------------------------- -------------------- DBMS_SPACE.SPACE_USAGE -------------------- ---------------------------------------------------------------- Total NUMBER OF blocks unformatted :0 NUMBER OF blocks HAVING AT LEAST 0 TO 25% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 25 TO 50% free SPACE: 1 NUMBER OF blocks HAVING AT LEAST 50 TO 75% free SPACE: 0 NUMBER OF blocks HAVING AT LEAST 75 TO 100% free SPACE: 0 The NUMBER OF blocks full IN the SEGMENT: 325098 ---------------------------------------------------------------- ------------------------- DBA_SEGMENTS ------------------------- ---------------------------------------------------------------- SIZE OF the SEGMENT: 2.507GB ---------------------------------------------------------------- ----------------- DBMS_SPACE.CREATE_INDEX_COST ----------------- ---------------------------------------------------------------- Used: 1.386GB Allocated: 2.438GB ---------------------------------------------------------------- ---------------------------- Results --------------------------- ---------------------------------------------------------------- Potential percentage gain (DBMS_SPACE): 2% Potential percentage gain (DBA_SEGMENTS): 3% SQL> @inspect_index <owner> <INDEX name> FOR INDEX <owner>.<INDEX name>, source TABLE IS <owner>.<TABLE name> CURRENT leaf blocks: 323860 CURRENT SIZE: 2.471GB Estimated leaf blocks: 330825 Estimated SIZE: 2.524GB SQL> @sys_op_lbid <owner> <INDEX name> KEYS_PER_LEAF BLOCKS CUMULATIVE_BLOCKS ------------- ---------- ----------------- 56 1 1 217 10086 10087 218 146 10233 219 120 10353 220 70 10423 221 64 10487 222 65 10552 223 76 10628 224 29037 39665 225 1566 41231 226 1268 42499 227 1077 43576 228 861 44437 229 928 45365 230 1245 46610 231 277246 323856 248 1 323857 341 3 323860 |
Graphically it gives:
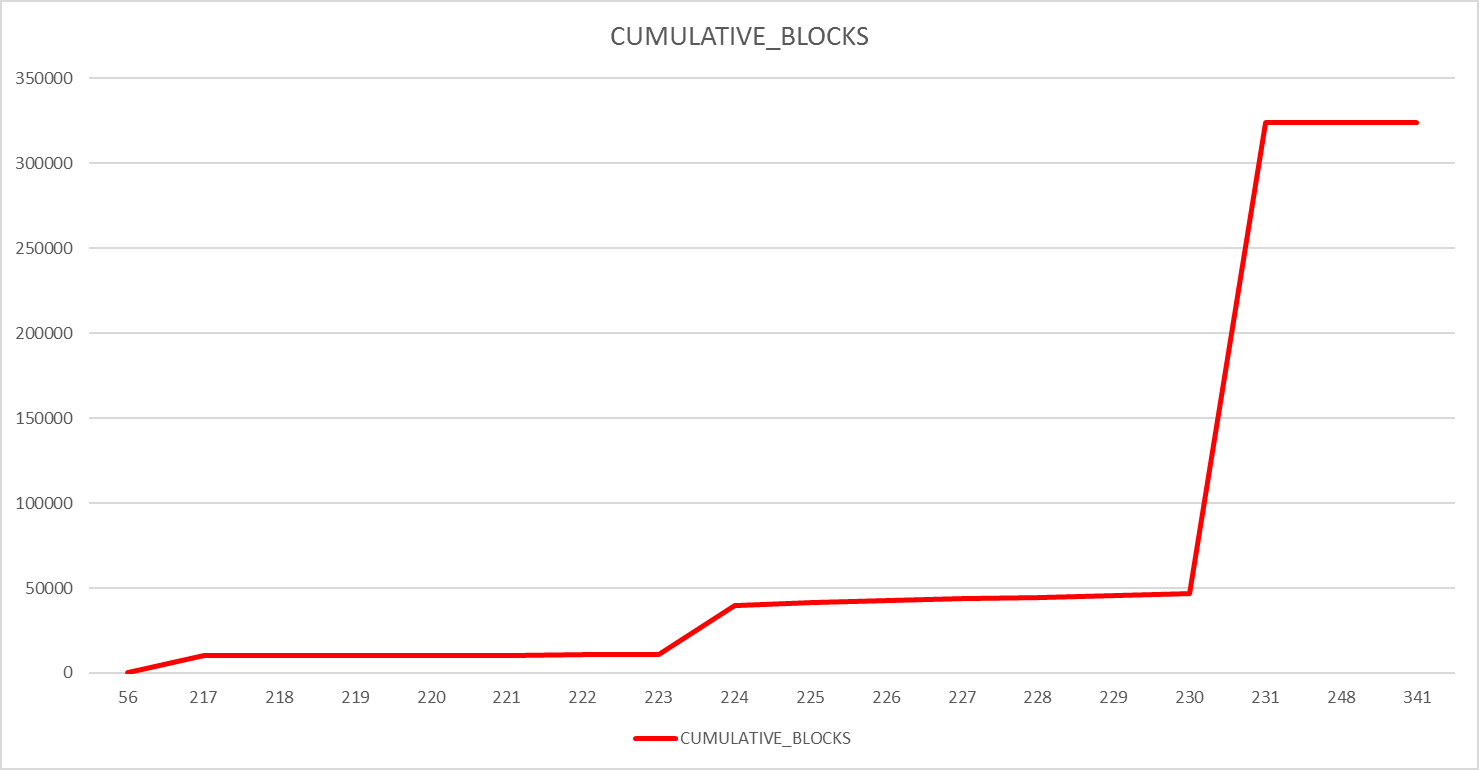
Much better ! I still have a big jump is number of blocks required to be read when number of keys is increasing but I suppose it comes from a key that has high frequency in my source table. Which demonstrate that it is not abnormal to have such big jump in queries with SYS_OP_LBID internal function.
The process you could apply is to try to shrink your index by default. If you are unhappy with the result try to afford a rebuild. The good thing now is that checking the index is not locking anything and you can launch it multiple time even on a production database…
References
- Script to identify index rebuild candidates on 12c
- Index Efficiency 3
- Index Rebuild, the Need vs the Implications (Doc ID 989093.1)
- Script to investigate a b-tree index structure (Doc ID 989186.1)
- Index size
- How to Estimate the Size of Tables and Indexes Before Being Created and Populated in the Database? (Doc ID 1585326.1)
- SYS_OP_LBID
- Index Rebuild vs. Coalesce vs. Shrink Space (Pigs – 3 Different Ones)
- What about ALTER INDEX … SHRINK SPACE ?





Damir Vadas says:
Hi,
not a single script works against partitioned indexes.
8(
Brg
Damir
Yannick Jaquier says:
Hi,
Nice catch ! I have tried to update the scripts to handle partitioned indexes. I anyways noticed that it is not providing accurate results on BITMAP indexes. By the way if you check Oracle support note 989186.1 you will see that Oracle exclude partitioned, temporary and index type not in ‘NORMAL’,’NORMAL/REV’,’FUNCTION-BASED NORMAL’. There might be a reason…
Give a try and let me know…
Yannick.