For their open source position we have chosen to install an Hortonworks HDP 2.6 Hadoop cluster. At the initial phase of our Hadoop project ORC storage has been chosen as the default storage engine for our very first Hive tables.
Performance of our queries is, obviously, a key factor we consider. This is why we have started to consider Live Long And Process (LLAP) and realized it was not so easy to handle in our small initial cluster. Then the merge between Hortonworks and Cloudera happened and we decided to move all our tables to Parquet storage engine with the clear objective to use Impala from Cloudera.
But at a point in time we have started to study a bit the disk space usage (again linked to our small initial cluster) and realized that Parquet tables were much bigger than their ORC counterpart. All our Hive tables are highly using partitioning for performance and to ease cleaning by simply dropping old partitions…
There are plenty of articles comparing Parquet and ORC (and others) storage engines but if you read them carefully till the end there will most probably be a disclaimer stating that the comparison is tightly linked to data nature. In other words your data model and figures is unique and you have really no other option than testing it by yourself and this blog post is here to provide few tricks to achieve this…
Our cluster is running HDP-2.6.4.0 with Ambari version 2.6.1.0.
ORC versus Parquet compression
On one partition of one table we observed:
Parquet = 33.9 G
ORC = 2.4 G
Digging further we saw that ORC compression can be easily configured in Ambari and we have set it to zlib:
orc_vs_parquet01
While the default Parquet compression is (apparently) uncompressed that is obviously not really good from compression perspective.
Digging in multiple (contradictory) blog posts and official documentation and personal testing I have been able to draw below table:
Hive SQL property
Default
Values
orc.compress
ZLIB
NONE, ZLIB or SNAPPY
parquet.compression
UNCOMPRESSED
UNCOMPRESSED, GZIP or SNAPPY
Remark: I have seen many blog posts suggesting to use parquet.compress for Parquet compression algorithm but in my opinion this one does not work…
To change compression algorithm when creating a table use TBLPROPERTIES keyword like:
STORED AS PARQUET TBLPROPERTIES("parquet.compression"="GZIP");
STORED AS ORC TBLPROPERTIES("orc.compress"="SNAPPY")
STORED AS PARQUET TBLPROPERTIES("parquet.compression"="GZIP");
STORED AS ORC TBLPROPERTIES("orc.compress"="SNAPPY")
So, as an example, the test table I have built for my testing is something like:
drop table default.test purge;CREATE TABLE default.test(
column01 string,
column02 string,
column03 int,
column04 array<string>)
PARTITIONED BY (column01 string, column02 string, column03 int)
STORED AS PARQUET
TBLPROPERTIES("parquet.compression"="SNAPPY");
To get the size of your test table (replace database_name and table_name by real values) just use something like (check the value of hive.metastore.warehouse.dir for /apps/hive/warehouse):
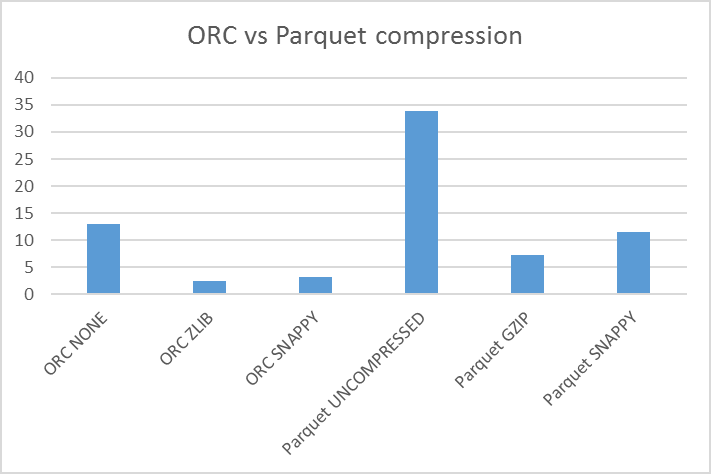
Then I have copied my source Parquet table to this test table using the six combination of storage engine and compression algorithms and the result is:
ORC
Parquet
orc.compress
parquet.compression
NONE
ZLIB
SNAPPY
UNCOMPRESSED
GZIP
SNAPPY
12.9 G
2.4 G
3.2 G
33.9 G
7.3 G
11.5 G
Or graphically:
orc_vs_parquet02
To do the copy I have written a shell script that is dynamically copying each partition of the source table to its destination table that has the same layout:
#!/bin/bash## Y.JAQUIER 06/02/2019 Creation## -----------------------------------------------------------------------------## This job copy one table on another one# Useful when migrating from Parquet to ORC for example## Destination table must have been created before using this script## -----------------------------------------------------------------------------################################################################################# Function to execute a query on hive# Param 1 : Query string###############################################################################function execute_query
{#echo "Execute query: $1"MYSTART=$(date)
beeline -u"jdbc:hive2://${HIVE_CONNEXION}?tez.queue.name=${HIVE_QUEUE}"-n${HIVE_USER}--incremental=true--silent=true--fastConnect=true-e"$1"status=$?MYEND=$(date)MYDURATION=$(expr $(date-d"$MYEND" +%s) - $(date-d"$MYSTART" +%s))echo"Executed in $MYDURATION second(s)"#echo "MEASURE|$FAB|${INGESTION_DATE}|$1|$(date -d "$MYSTART" +%Y%m%d%H%M%S)|$(date -d "$MYEND" +%Y%m%d%H%M%S)|$MYDURATION"if[[$status!= "0"]]thenecho" !!!!!!!! Error Execution Query $1 !!!!!!!! "exit-1fi}################################################################################ Function to execute a query on hive in CSV output file# Param 1 : Query string# Param 2 : output file###############################################################################function execute_query_to_csv
{#echo "Execute query to csv: $1 => $2"MYSTART=$(date)
beeline -u"jdbc:hive2://${HIVE_CONNEXION}?tez.queue.name=${HIVE_QUEUE}"-n${HIVE_USER}--outputformat=csv2 --silent=true--verbose=false \
--showHeader=false--fastConnect=true-e"$1">$2status=$?MYEND=$(date)MYDURATION=$(expr $(date-d"$MYEND" +%s) - $(date-d"$MYSTART" +%s))#echo "MEASURE|$FAB|${INGESTION_DATE}|$1|$(date -d "$MYSTART" +%Y%m%d%H%M%S)|$(date -d "$MYEND" +%Y%m%d%H%M%S)|$MYDURATION"if[[$status!= "0"]]thenecho" !!!!!!!! Error Execution Query to csv : $1 => $2 !!!!!!!! "exit-1fi}################################################################################ Print the help###############################################################################function print_help
{echo"syntax:"echo"$0 source_database.source_table destination_database.destination_table partition_filter_pattern_and_option (not mandatory)"echo"Source and destination table must exists"echo"Destination table data will be overwritten !!"}################################################################################ Main###############################################################################HIVE_CONNEXION="..."HIVE_QUEUE=...
HIVE_USER=...
TABLE_SOURCE=$1TABLE_DESTINATON=$2PARTITION_FILTER=$3if[[$#<"2"]]then
print_help
exit0fiecho"This will overwrite $TABLE_DESTINATON table by $TABLE_SOURCE table data !"echo"The destination table MUST be created first !"read-p"Do you wish to continue [Y | N] ? " answer
case$answerin[Yy]*);;[Nn]*)exit0;;*)echo"Please answer yes or no."; exit0;;esac# Generate partitions list
execute_query_to_csv "show partitions $1;" partition_list.$$.csv
# Filter partiion list base on regular expression givenif[[$PARTITION_FILTER!= ""]]thengrep$PARTITION_FILTER partition_list.$$.csv > partition_list1.$$.csv
mv partition_list1.$$.csv partition_list.$$.csv
fipartition_number=$(cat partition_list.$$.csv |wc -l)# Generate column list (with partition columns which must be removed)
execute_query_to_csv "show columns from $1;" column_list.$$.csv
# First partition columnwhileread line
dofirst_partition_column=$(echo$line|awk-F"="'{print $1}')breakdone< partition_list.$$.csv
# Columns list without partition columnscolumns_list_without_partitions=""whileread line
doif[[$line = $first_partition_column]]thenbreakfi
columns_list_without_partitions+="$line,"done< column_list.$$.csv
# Remove trailing commacolumns_length=${#columns_list_without_partitions}columns_list_without_partitions=${columns_list_without_partitions:0:$(($columns_length-1))}echo"The source table has $partition_number partition(s)"# Generate list of all insert partition by partitioni=1whileread line
do#echo $lineecho"Partition ${i}:"j=1query1="insert overwrite table $TABLE_DESTINATON partition ("query2=""query3=""IFS="/"read-r-a partition_list <<<"$line"# We fetch all partition columnsfor partition_column_list in"${partition_list[@]}"doIFS="="read-r-a partition_columns <<<"$partition_column_list"# First insert is with WHERE and we must enclosed columns value with double quoteif[[$j-eq1]]then
query3+="where ${partition_columns[0]}=\"${partition_columns[1]}\" "else
query3+="and ${partition_columns[0]}=\"${partition_columns[1]}\" "fi
query2+="${partition_columns[0]}=\"${partition_columns[1]}\","j=$((j+1))doneIFS=""i=$((i+1))query2_length=${#query2}query2_length=$((query2_length-1))query2=${query2:0:$query2_length}final_query=$query1$query2") select "$columns_list_without_partitions" from $TABLE_SOURCE "$query3#Executing the query comment out the execute query to test it before runningecho$final_query
execute_query $final_querydone< partition_list.$$.csv
rm partition_list.$$.csv
rm column_list.$$.csv
#!/bin/bash
#
# Y.JAQUIER 06/02/2019 Creation
#
# -----------------------------------------------------------------------------
#
# This job copy one table on another one
# Useful when migrating from Parquet to ORC for example
#
# Destination table must have been created before using this script
#
# -----------------------------------------------------------------------------
################################################################################
# Function to execute a query on hive
# Param 1 : Query string
###############################################################################
function execute_query
{
#echo "Execute query: $1"
MYSTART=$(date)
beeline -u "jdbc:hive2://${HIVE_CONNEXION}?tez.queue.name=${HIVE_QUEUE}" -n ${HIVE_USER} --incremental=true --silent=true --fastConnect=true -e "$1"
status=$?
MYEND=$(date)
MYDURATION=$(expr $(date -d "$MYEND" +%s) - $(date -d "$MYSTART" +%s))
echo "Executed in $MYDURATION second(s)"
#echo "MEASURE|$FAB|${INGESTION_DATE}|$1|$(date -d "$MYSTART" +%Y%m%d%H%M%S)|$(date -d "$MYEND" +%Y%m%d%H%M%S)|$MYDURATION"
if [[ $status != "0" ]]
then
echo " !!!!!!!! Error Execution Query $1 !!!!!!!! "
exit -1
fi
}###############################################################################
# Function to execute a query on hive in CSV output file
# Param 1 : Query string
# Param 2 : output file
###############################################################################
function execute_query_to_csv
{
#echo "Execute query to csv: $1 => $2"
MYSTART=$(date)
beeline -u "jdbc:hive2://${HIVE_CONNEXION}?tez.queue.name=${HIVE_QUEUE}" -n ${HIVE_USER} --outputformat=csv2 --silent=true --verbose=false \
--showHeader=false --fastConnect=true -e "$1" > $2
status=$?
MYEND=$(date)
MYDURATION=$(expr $(date -d "$MYEND" +%s) - $(date -d "$MYSTART" +%s))
#echo "MEASURE|$FAB|${INGESTION_DATE}|$1|$(date -d "$MYSTART" +%Y%m%d%H%M%S)|$(date -d "$MYEND" +%Y%m%d%H%M%S)|$MYDURATION"
if [[ $status != "0" ]]
then
echo " !!!!!!!! Error Execution Query to csv : $1 => $2 !!!!!!!! "
exit -1
fi
}###############################################################################
# Print the help
###############################################################################
function print_help
{
echo "syntax:"
echo "$0 source_database.source_table destination_database.destination_table partition_filter_pattern_and_option (not mandatory)"
echo "Source and destination table must exists"
echo "Destination table data will be overwritten !!"
}###############################################################################
# Main
###############################################################################
HIVE_CONNEXION="..."
HIVE_QUEUE=...
HIVE_USER=...TABLE_SOURCE=$1
TABLE_DESTINATON=$2
PARTITION_FILTER=$3if [[ $# < "2" ]]
then
print_help
exit 0
fiecho "This will overwrite $TABLE_DESTINATON table by $TABLE_SOURCE table data !"
echo "The destination table MUST be created first !"
read -p "Do you wish to continue [Y | N] ? " answer
case $answer in
[Yy]* ) ;;
[Nn]* ) exit 0;;
* ) echo "Please answer yes or no."; exit 0;;
esac# Generate partitions list
execute_query_to_csv "show partitions $1;" partition_list.$$.csv# Filter partiion list base on regular expression given
if [[ $PARTITION_FILTER != "" ]]
then
grep $PARTITION_FILTER partition_list.$$.csv > partition_list1.$$.csv
mv partition_list1.$$.csv partition_list.$$.csv
fipartition_number=$(cat partition_list.$$.csv | wc -l)# Generate column list (with partition columns which must be removed)
execute_query_to_csv "show columns from $1;" column_list.$$.csv# First partition column
while read line
do
first_partition_column=$(echo $line | awk -F "=" '{print $1}')
break
done < partition_list.$$.csv# Columns list without partition columns
columns_list_without_partitions=""
while read line
do
if [[ $line = $first_partition_column ]]
then
break
fi
columns_list_without_partitions+="$line,"
done < column_list.$$.csv# Remove trailing comma
columns_length=${#columns_list_without_partitions}
columns_list_without_partitions=${columns_list_without_partitions:0:$(($columns_length-1))}echo "The source table has $partition_number partition(s)"# Generate list of all insert partition by partition
i=1
while read line
do
#echo $line
echo "Partition ${i}:"
j=1
query1="insert overwrite table $TABLE_DESTINATON partition ("
query2=""
query3=""
IFS="/"
read -r -a partition_list <<< "$line"# We fetch all partition columns
for partition_column_list in "${partition_list[@]}"
do
IFS="="
read -r -a partition_columns <<< "$partition_column_list"
# First insert is with WHERE and we must enclosed columns value with double quote
if [[ $j -eq 1 ]]
then
query3+="where ${partition_columns[0]}=\"${partition_columns[1]}\" "
else
query3+="and ${partition_columns[0]}=\"${partition_columns[1]}\" "
fi
query2+="${partition_columns[0]}=\"${partition_columns[1]}\","
j=$((j+1))
done
IFS=""
i=$((i+1))
query2_length=${#query2}
query2_length=$((query2_length-1))
query2=${query2:0:$query2_length}
final_query=$query1$query2") select "$columns_list_without_partitions" from $TABLE_SOURCE "$query3
#Executing the query comment out the execute query to test it before running
echo $final_query
execute_query $final_query
done < partition_list.$$.csv
rm partition_list.$$.csv
rm column_list.$$.csv
So clearly for our data nature the ORC storage engine cannot be beaten when it comes to disk usage…
I have taken additional figures when we have migrated our live tables of our Spotfire data model:
[hdfs@server01 ~]$ hdfs dfs -du-s-h/apps/hive/warehouse/database.db/table01*564.2 G /apps/hive/warehouse/database.db/table01_orc
3.6 T /apps/hive/warehouse/database.db/table01_pqt
[hdfs@server01 ~]$ hdfs dfs -du -s -h /apps/hive/warehouse/database.db/table01*
564.2 G /apps/hive/warehouse/database.db/table01_orc
3.6 T /apps/hive/warehouse/database.db/table01_pqt
[hdfs@server01 ~]$ hdfs dfs -du-s-h/apps/hive/warehouse/database.db/table02*121.3 M /apps/hive/warehouse/database.db/table02_pqt
5.6 M /apps/hive/warehouse/database.db/table02_orc
[hdfs@server01 ~]$ hdfs dfs -du -s -h /apps/hive/warehouse/database.db/table02*
121.3 M /apps/hive/warehouse/database.db/table02_pqt
5.6 M /apps/hive/warehouse/database.db/table02_orc
ORC versus Parquet response time
But what about response time ? To do this I have extracted a typical query used by Spotfire and executed it on Parquet (UNCOMPRESSED) and on ORC (ZLIB) tables:
Iteration
Parquet (s)
ORC (s)
Run 1
6.553
0.077
Run 2
5.291
0.066
Run 3
1.915
0.065
Run 4
2.987
0.074
Run 5
1.825
0.070
Run 6
2.720
0.092
Run 7
3.989
0.062
Run 8
4.526
0.079
Run 9
3.385
0.082
Run 10
3.588
0.176
Average
3.6779
0.0843
So on average over my ten runs we have a factor of 43-44 time faster for ORC…
I would explain this that I have much less data to read on disk for the ORC tables and, again, this is linked to our data nodes hardware where we have much more CPU than disk axis (ratio of one thread per physical disk is not at all followed). If you are low on CPU and have plenty of disks (which is also not a good practice for an Hadoop cluster) you might experience different results…