Table of contents
Preamble
Starting with Oracle database 21c Oracle has introduced a new datatype called JSON.
As written in the official documentation Oracle recommends that you use JSON data type, which stores JSON data in a native binary format. In case the JSON datatype is not available in your edition or if you upgraded a legacy application the official Oracle recommzndation is the following:
- VARCHAR2(4000) if you are sure that your largest JSON documents do not exceed 4000 bytes (or characters).
- VARCHAR2(32767) if you know that some of your JSON documents are larger than 4000 bytes (or characters) and you are sure than none of the documents exceeds 32767 bytes (or characters). With VARCHAR2(32767), the first roughly 3.5K bytes (or characters) of a document is stored in line, as part of the table row. This means that the added cost of using VARCHAR2(32767) instead of VARCHAR2(4000) applies only to those documents that are larger than about 3.5K. If most of your documents are smaller than this then you will likely notice little performance difference from using VARCHAR2(4000).
- Use BLOB (binary large object) or CLOB (character large object) storage if you know that you have some JSON documents that are larger than 32767 bytes (or characters).
Then, in fact, between BLOB and CLOB there is also no debate and BLOB must be your choice:
If you use LOB storage for JSON data, Oracle recommends that you use BLOB, not CLOB storage.
This is particularly relevant if the database character set is the Oracle-recommended value of AL32UTF8. In AL32UTF8 databases CLOB instances are stored using the UCS2 character set, which means that each character requires two bytes. This doubles the storage needed for a document if most of its content consists of characters that are represented using a single byte in character set AL32UTF8.
Even in cases where the database character set is not AL32UTF8, choosing BLOB over CLOB storage has the advantage that it avoids the need for character-set conversion when storing the JSON document (see Character Sets and Character Encoding for JSON Data).
Oracle is also claiming that JSON performance is better than other datatypes, without giving exact figures:
JSON is a new SQL and PL/SQL data type for JSON data. It provides a substantial increase in query and update performance.
In this blog post I’m exactly planning to test how much gain the JSON datatype is giving over BLOB. My testing has been done on Oracle Database 21c Enterprise Edition Release 21.15.0.0.0. My test server is running Red Hat Enterprise Linux release 8.7 (Ootpa) with 64GB of memory and 12 cores.
Loading JSON into Oracle with Python
I have created the typical table to store my JSON data:
SQL> CREATE TABLE test01 ( id NUMBER generated always AS identity (START WITH 0 minvalue 0) NOT NULL PRIMARY KEY, json_data json, CONSTRAINT test01_ensure_json CHECK (json_data IS json) ); TABLE created. |
I was looking for a big JSON file tobe able to make some performance comparison between JSON and BLOB datatypes. I have found one with 1.7 millions users on jsoneditoronline. This web is mainly a web site to edit JSON files…
As suggested in the JSON Developer’s Guide I have tried to load this big file (500 MB) with an external table so doing something like:
SQL> CREATE OR REPLACE DIRECTORY tmp AS '/tmp'; DIRECTORY created. CREATE TABLE json_dump_file_contents (json_document blob) ORGANIZATION external ( TYPE oracle_loader DEFAULT DIRECTORY tmp ACCESS parameters ( records delimited BY '},{' fields (json_document CHAR(5000)) ) location (tmp:'users_1.7m.json') ) parallel reject limit unlimited; |
But after many trials I have never been able to load the file successfully. Mainly because the file is on one single line most probably:
SQL> SET pages 1000 lines 200 SQL> SELECT TO_CHAR(json_document) FROM json_dump_file_contents FETCH FIRST 10 ROWS only; TO_CHAR(JSON_DOCUMENT) -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- "id":725900,"name":"Chloe","city":"San Antonio","age":69,"friends":[{"name":"Sarah","hobbies":["Playing Cards","Traveling"] "name":"Mia","hobbies":["Yoga","Board Games","Traveling"] "name":"Zoey","hobbies":["Watching Sports","Running"] "name":"Michael","hobbies":["Movie Watching","Walking","Fishing"]}] "id":725901,"name":"Liam","city":"Branson","age":92,"friends":[{"name":"Elijah","hobbies":["Calligraphy","Jewelry Making"] "name":"Noah","hobbies":["Tennis","Church Activities"] "name":"Leo","hobbies":["Fishing","Volunteer Work","Team Sports"]}] "id":725902,"name":"Michelle","city":"San Antonio","age":66,"friends":[{"name":"Lucas","hobbies":["Dancing","Painting","Yoga"] "name":"Daniel","hobbies":["Movie Watching","Playing Cards","Yoga"] "name":"Victoria","hobbies":["Traveling","Gardening","Podcasts"] 10 ROWS selected. |
Even playing with the fields terminated by “,” optionally enclosed by ‘{}’ loading options did not help that much… Apparently 23ai will bring some improvement around this…
So finally same I have done for MariaDB I have decided to use the Python driver for Oracle database and created this small script to load the 1.7 millions rows JSON file into my table. I have used intermediate commit with batch variable to avoid to fill my UNDO tablespace:
import json, oracledb file = "d:/Download/users_1.7m.json" json_data = open(file).read() json_obj = json.loads(json_data) # Connect to Oracle database try: connection = oracledb.connect( user = "yjaquier", password = "secure_password", dsn = "euls20092.sgp.st.com:1531/pdb1") except oracledb.Error as e: print(f"Error connecting to Oracle database: {e}") exit(1) else: print("Successfully connected to Oracle Database") # Get Cursor cursor = connection.cursor() data=[] sql="INSERT INTO test01 (json_data) VALUES (:1)" i = 0 batch = 100000 for json_item in json_obj: data.append((json.dumps(json_item),)) i += 1 if (i == batch): try: cursor.executemany(sql, data) connection.commit() except oracledb.Error as e: print(f"Error inserting in Oracle database: {e}") else: print(f"Sucessfully insert {batch} rows in Oracle database") data.clear() i = 0 # Commit connection.commit() # Close cursor and connection cursor.close() connection.close() |
Remark:
To clean the table and reset the id generated column do something like:
TRUNCATE TABLE test01; ALTER TABLE test01 MODIFY(id generated AS identity (START WITH 0)); |
The execution:
$ time python oracle_json01.py Successfully connected to Oracle Database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database Sucessfully insert 100000 rows in Oracle database real 3m26.605s user 0m0.265s sys 0m0.358s |
We can control that whole JSON file has been successfully loaded:
SQL> SELECT COUNT(*) FROM test01; COUNT(*) ---------- 1700000 |
To compare the performance I create a second table with a BLOB column to store the JSON information, I kept the constraint to check that I’m inserting valid JSON information:
SQL> CREATE TABLE test02 ( id NUMBER generated always AS identity (START WITH 0 minvalue 0) NOT NULL PRIMARY KEY, json_data blob, CONSTRAINT test02_ensure_json CHECK (json_data IS json) ); TABLE created. |
To load I have used the exact same script, with the same exact number of rows loaded. The only difference of the two datatypes is the difference of display and the BLOB datatype makes the display more hidden:
SQL> SET lines 200 pages 1000 SQL> SELECT * FROM test01 ORDER BY id FETCH FIRST 5 ROWS only; ID JSON_DATA ---------- -------------------------------------------------------------------------------- 0 {"id":0,"name":"Elijah","city":"Austin","age":78,"friends":[{"name":"Michelle"," 1 {"id":1,"name":"Noah","city":"Boston","age":97,"friends":[{"name":"Oliver","hobb 2 {"id":2,"name":"Evy","city":"San Diego","age":48,"friends":[{"name":"Joe","hobbi 3 {"id":3,"name":"Oliver","city":"St. Louis","age":39,"friends":[{"name":"Mateo"," 4 {"id":4,"name":"Michael","city":"St. Louis","age":95,"friends":[{"name":"Mateo", SQL> SELECT * FROM test02 ORDER BY id FETCH FIRST 5 ROWS only; ID JSON_DATA ---------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------- 0 7B226964223A20302C20226E616D65223A2022456C696A6168222C202263697479223A202241757374696E222C2022616765223A2037382C2022667269656E6473223A205B7B226E616D65223A20224D 1 7B226964223A20312C20226E616D65223A20224E6F6168222C202263697479223A2022426F73746F6E222C2022616765223A2039372C2022667269656E6473223A205B7B226E616D65223A20224F6C69 2 7B226964223A20322C20226E616D65223A2022457679222C202263697479223A202253616E20446965676F222C2022616765223A2034382C2022667269656E6473223A205B7B226E616D65223A20224A 3 7B226964223A20332C20226E616D65223A20224F6C69766572222C202263697479223A202253742E204C6F756973222C2022616765223A2033392C2022667269656E6473223A205B7B226E616D65223A 4 7B226964223A20342C20226E616D65223A20224D69636861656C222C202263697479223A202253742E204C6F756973222C2022616765223A2039352C2022667269656E6473223A205B7B226E616D6522 |
To calculate the size of the two table I gather statistics on them and used the create_table_cost.sql function I have written in another blog post:
SQL> EXEC dbms_stats.gather_table_stats(ownname=>'yjaquier', tabname=>'test01', estimate_percent=>NULL, method_opt=>'for all indexed columns size auto', degree=>dbms_stats.default_degree, CASCADE=>TRUE); PL/SQL PROCEDURE successfully completed. SQL> EXEC dbms_stats.gather_table_stats(ownname=>'yjaquier', tabname=>'test02', estimate_percent=>NULL, method_opt=>'for all indexed columns size auto', degree=>dbms_stats.default_degree, CASCADE=>TRUE); PL/SQL PROCEDURE successfully completed. SQL> @create_table_cost yjaquier test01 ---------------------------------------------------------------- ------------ DBMS_SPACE.CREATE_TABLE_COST version 1 ------------ ---------------------------------------------------------------- Used: 632.445MB Allocated: 640.000MB ---------------------------------------------------------------- ------------ DBMS_SPACE.CREATE_TABLE_COST version 2 ------------ ---------------------------------------------------------------- Used: 25.940GB Allocated: 26.000GB SQL> @create_table_cost yjaquier test02 ---------------------------------------------------------------- ------------ DBMS_SPACE.CREATE_TABLE_COST version 1 ------------ ---------------------------------------------------------------- Used: 699.016MB Allocated: 704.000MB ---------------------------------------------------------------- ------------ DBMS_SPACE.CREATE_TABLE_COST version 2 ------------ ---------------------------------------------------------------- Used: 12.970GB Allocated: 13.000GB |
JSON queries and performance comparison
JSON basic queries
For me the coolest way to query JSON column is the dot-notation, prefix the columns with a table alias to avoid a weird ORA-00904 error:
SQL> SET lines 200 pages 1000 SQL> SELECT json_data.city FROM test01 ORDER BY id FETCH FIRST 5 ROWS only; SELECT json_data.city FROM test01 ORDER BY id FETCH FIRST 5 ROWS only * ERROR AT line 1: ORA-00904: "JSON_DATA"."CITY": invalid identifier SQL> SELECT t.json_data.city FROM test01 t ORDER BY id FETCH FIRST 5 ROWS only; CITY -------------------------------------------------------------------------------- "Austin" "Boston" "San Diego" "St. Louis" "St. Louis" |
As suggested in the official documentation you can apply a bunch of item method to the targeted data to make some more advanced computation. Ordered list of all distinct cities:
SQL> col city FOR a20 SQL> SELECT DISTINCT t.json_data.city.string() AS city FROM test01 t ORDER BY city; CITY -------------------- Austin Boston Branson Charleston Chicago Honolulu Lahaina Las Vegas Los Angeles Miami Beach Nashville NEW Orleans NEW York City Orlando Palm Springs Portland Saint Augustine San Antonio San Diego San Francisco Savannah Seattle Sedona St. Louis Washington 25 ROWS selected. |
Average number of all users:
SQL> SELECT AVG(t.json_data.age.NUMBER()) AS avg_age FROM test01 t; AVG_AGE ---------- 58.49432 |
If I want the hobbies of all friends of a user, you need to use the * wildcard character to avoid returning an array of arrays:
SQL> SELECT t.json_data.friends.hobbies[*] AS hobbies FROM test01 t WHERE id = 0; HOBBIES -------------------------------------------------------------------------------- ["Watching Sports","Reading","Skiing & Snowboarding","Traveling","Video Games"] |
If you want to explode al the array element in multiple row use the JSON_TABLE function:
SQL> SELECT jt.* FROM test01 t, json_table(t.json_data, '$.friends.hobbies[*]' columns (hobbies VARCHAR2(25) PATH '$[0]')) jt WHERE id=0; HOBBIES ------------------------- Watching Sports Reading Skiing & Snowboarding Traveling Video Games |
This query extracting the distinct list of hobbies will be my performance comparison query…
JSON performance comparison
To have good explain plan display, good formatting, execution time and to start fresh with the shared pool I execute and export:
SQL> ALTER SESSION SET statistics_level=ALL; SESSION altered. SQL> ALTER SYSTEM flush shared_pool; SYSTEM altered. SQL> SET lines 200 pages 1000 TIMING ON |
The two queries will be (the comment is, as usual to find myself in V$SQL):
SELECT /* Yannick01 */ DISTINCT jt.* FROM test01 t, json_table(t.json_data, '$.friends.hobbies[*]' columns (hobbies VARCHAR2(25) PATH '$[0]')) jt ORDER BY 1; SELECT /* Yannick02 */ DISTINCT jt.* FROM test02 t, json_table(t.json_data, '$.friends.hobbies[*]' columns (hobbies VARCHAR2(25) PATH '$[0]')) jt ORDER BY 1; |
Find the cursor in library cache with something like:
SELECT * FROM v$sql WHERE parsing_schema_name='YJAQUIER' AND sql_text LIKE 'select /* Yannick01 */%'; |
And display the explain plan with:
SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id => 'fd8st27gpu8vk', cursor_child_no => 0, format => 'all allstats')); SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id => 'dhga6dwjn407g', cursor_child_no => 0, format => 'all allstats')); |
They are identical:
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id => 'fd8st27gpu8vk', cursor_child_no => 0, format => 'all allstats')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID fd8st27gpu8vk, child NUMBER 0 ------------------------------------- SELECT /* Yannick01 */ DISTINCT jt.* FROM test01 t, json_table(t.json_data, '$.friends.hobbies[*]' columns (hobbies VARCHAR2(25) PATH '$[0]')) jt ORDER BY 1 PLAN hash VALUE: 3841167846 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-ROWS |E-Bytes|E-Temp | COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | Reads | OMem | 1Mem | O/1/M | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 10 | | | | 2742M(100)| | 370 |00:06:53.94 | 830K| 830K| | | | | 1 | SORT UNIQUE | | 10 | 13G| 4345G| 4606G| 1394M (1)| 15:07:55 | 370 |00:06:53.94 | 830K| 830K| 2048 | 2048 | 10/0/0| | 2 | NESTED LOOPS | | 10 | 13G| 4345G| | 46M (1)| 00:30:07 | 166M|00:05:29.84 | 830K| 830K| | | | | 3 | TABLE ACCESS FULL | TEST01 | 10 | 1700K| 541M| | 22675 (1)| 00:00:01 | 17M|00:01:55.84 | 830K| 830K| | | | | 4 | JSONTABLE EVALUATION | | 17M| | | | | | 166M|00:02:56.17 | 0 | 0 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (IDENTIFIED BY operation id): ------------------------------------------------------------- 1 - SEL$9E2ADECD 3 - SEL$9E2ADECD / "T"@"SEL$1" COLUMN Projection Information (IDENTIFIED BY operation id): ----------------------------------------------------------- 1 - (#keys=1) <NOT feasible>[25] 2 - VALUE(A0)[25] 3 - "T"."JSON_DATA" /*+ LOB_BY_VALUE */ [JSON,8200] 4 - VALUE(A0)[25] |
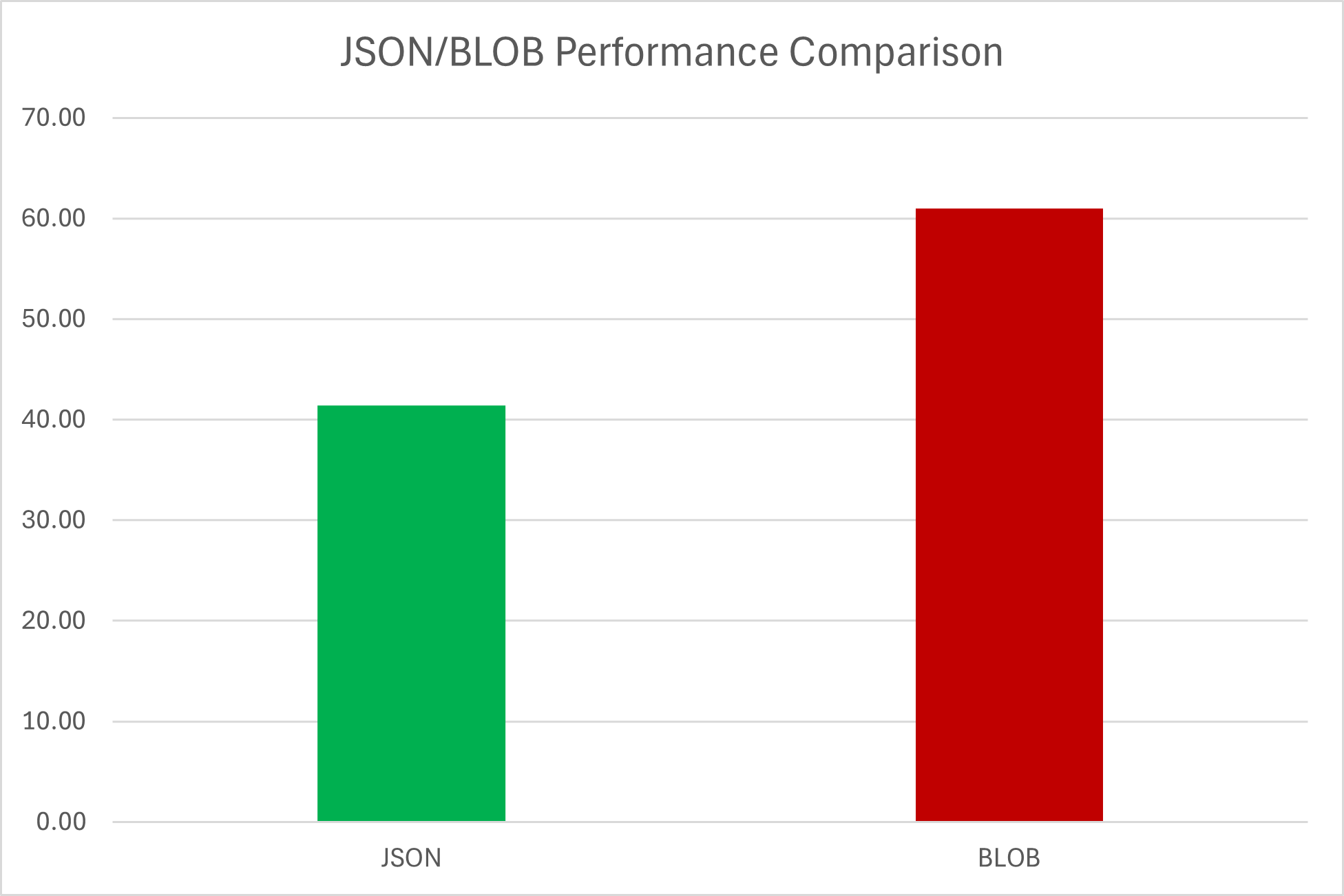
I got below performance, in no way this is a performance benchmark. Here the idea is just to compare the performance between JSON and BLOB:
| JSON | BLOB |
|---|---|
| 41.79 | 60.84 |
| 39.50 | 62.37 |
| 41.62 | 59.81 |
| 41.70 | 61.71 |
| 40.37 | 67.00 |
| 43.21 | 59.41 |
| 41.80 | 59.57 |
| 41.37 | 58.87 |
| 41.11 | 60.17 |
| 41.51 | 60.08 |
With averages of 41.40 seconds for the JSON datatype and 60.98 seconds for the BLOB datatype. So a nice improvement of 32% !
To go further with JSON performance
We see in the above explain plan that my table access is a full table scan access. Is there a way to improve that by creating an index on/in the JSON data like I would do on a traditional column ?
Imagine this query counting the number of users having a particular age:
SQL> SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)'); COUNT(*) ---------- 20897 1 ROW selected. Elapsed: 00:00:10.97 |
This query execute on average at around 11 seconds on the JSON datatype and in 25 seconds on the BLOB datatype.
This query is obviosuly doing a FTS:
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id => '71s2zff4cch0u', cursor_child_no => 0, format => 'all allstats')); PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------------------------------------------------- SQL_ID 71s2zff4cch0u, child NUMBER 0 ------------------------------------- SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)') PLAN hash VALUE: 1460474239 -------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-ROWS |E-Bytes| COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | Reads | -------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 22833 (100)| | 1 |00:00:11.39 | 83041 | 83029 | | 1 | SORT AGGREGATE | | 1 | 1 | 334 | | | 1 |00:00:11.39 | 83041 | 83029 | |* 2 | TABLE ACCESS FULL| TEST01 | 1 | 17000 | 5544K| 22833 (1)| 00:00:01 | 20897 |00:00:11.39 | 83041 | 83029 | -------------------------------------------------------------------------------------------------------------------------------- Query Block Name / Object Alias (IDENTIFIED BY operation id): ------------------------------------------------------------- 1 - SEL$1 2 - SEL$1 / "TEST01"@"SEL$1" Predicate Information (IDENTIFIED BY operation id): --------------------------------------------------- 2 - filter(JSON_EXISTS2("JSON_DATA" /*+ LOB_BY_VALUE */ FORMAT OSON , '$.age?(@ == 50)' FALSE ON ERROR)=1) COLUMN Projection Information (IDENTIFIED BY operation id): ----------------------------------------------------------- 1 - (#keys=0) COUNT(*)[22] 31 ROWS selected. |
Let create an index on the age JSON field. I have initially used the, for me, most elegant way of doing it. And gathered few statistics right after:
SQL> CREATE INDEX test01_idx_json_data_age ON test01 t (t.json_data.age.NUMBER()); INDEX created. SQL> EXEC dbms_stats.gather_table_stats(ownname => 'yjaquier', tabname => 'test01', method_opt => 'for all indexed columns size auto', CASCADE => TRUE); PL/SQL PROCEDURE successfully completed. |
But I have never ever been able to make Oracle Optimizer using this index !! I have tried all possible below queries and even with the INDEX hint. Result is that index has never been used !!:
SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@.number() == $age)' passing 50 AS "age"); SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@.number() == 50)'); SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)'); SELECT /* Yannick01 */ /*+ index(test01 test01_idx_json_data_age) */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)'); |
Then, taken from the official documentation, I have used the other method to create the index:
SQL> CREATE INDEX test01_idx_json_data_age ON test01(json_value(json_data, '$.age.number()' error ON error NULL ON empty)); INDEX created. SQL> EXEC dbms_stats.gather_table_stats(ownname => 'yjaquier', tabname => 'test01', method_opt => 'for all indexed columns size auto', CASCADE => TRUE); PL/SQL PROCEDURE successfully completed. |
And immediately the index has been taken into account as we can see with the query execution time (as expected I would say):
SQL> SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)'); COUNT(*) ---------- 20897 Elapsed: 00:00:00.01 |
I don’t know if I have hit a bug or what for the first index creation but I have not understood why the index has not been used in the former creation. I have seen multiple bugs (like Bug 34195583) but my release (21.15) is far beyond the ones impacted. Any comment is welcome if someone has found something around this…
The explain plan is doing the expected index range scan:
SQL> SELECT * FROM TABLE(dbms_xplan.display_cursor(sql_id => '71s2zff4cch0u', cursor_child_no => 0, format => 'all allstats')); PLAN_TABLE_OUTPUT ------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID 71s2zff4cch0u, child NUMBER 0 ------------------------------------- SELECT /* Yannick01 */ COUNT(*) FROM test01 WHERE json_exists(json_data, '$.age?(@ == 50)') PLAN hash VALUE: 2847744817 ---------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-ROWS |E-Bytes| COST (%CPU)| E-TIME | A-ROWS | A-TIME | Buffers | ---------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 43 (100)| | 1 |00:00:00.01 | 44 | | 1 | SORT AGGREGATE | | 1 | 1 | 3 | | | 1 |00:00:00.01 | 44 | |* 2 | INDEX RANGE SCAN| TEST01_IDX_JSON_DATA_AGE | 1 | 20897 | 62691 | 43 (0)| 00:00:01 | 20897 |00:00:00.01 | 44 | ---------------------------------------------------------------------------------------------------------------------------------------- Query Block Name / Object Alias (IDENTIFIED BY operation id): ------------------------------------------------------------- 1 - SEL$1 2 - SEL$1 / "TEST01"@"SEL$1" Predicate Information (IDENTIFIED BY operation id): --------------------------------------------------- 2 - ACCESS("TEST01"."SYS_NC00004$"=50) COLUMN Projection Information (IDENTIFIED BY operation id): ----------------------------------------------------------- 1 - (#keys=0) COUNT(*)[22] 31 ROWS selected. |
References
- JSON Developer’s Guide
- Quick Start: Developing Python Applications for Oracle Database
- How to Store, Query, and Create JSON Documents in Oracle Database
- JSON Data Type in Oracle Database 21c



 hands-on")

