Table of contents
Preamble
Our DataWareHouse databases running on HPUX Itanium boxes have historically always suffer from ORA-04031: unable to allocate string bytes of shared memory (“string”,”string”,”string”,”string”) error message. This despite more than 10GB allocated to SGA with Automatic Shared Memory Management (ASMM). Those databases are running, in fact, on Itanium nPar servers. We have also noticed that even if SHMMAX is greater than physical memory the SGA allocated is split in multiple parts.
The Oracle release used is Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 – 64bit Production with very few one off patches, so the base is more or less common to all. Oracle support replied the issue is shared pool memory fragmentation. To try to correct it we have tried to pin big objects in memory using DBMS_SHARED_POOL.KEEP function with a pretty good result (one of these database is not suffering anymore).
Then one of my teammate observed how server is behaving from CPU/memory perspective. But first a bit of hardware information:
server1{root}# /usr/contrib/bin/machinfo CPU info: Number of CPUs = 10 Clock speed = 1598 MHz Bus speed = 533 MT/s CPUID registers vendor information = "GenuineIntel" processor serial number = 0x0000000000000000 processor version info = 0x0000000020010104 architecture revision: 0 processor family: 32 Intel(R) Itanium 2 9100 series processor model: 1 Intel(R) Itanium 2 9100 series processor revision: 1 Stepping A1 largest CPUID reg: 4 processor capabilities = 0x0000000000000005 implements long branch: 1 implements 16-byte atomic operations: 1 Bus features implemented = 0xbdf0000020000000 selected = 0x0020000000000000 Exclusive Bus Cache Line Replacement Enabled Cache info (per core): L1 Instruction: size = 16 KB, associativity = 4 L1 Data: size = 16 KB, associativity = 4 L2 Instruction: size = 1024 KB, associativity = 8 L2 Data: size = 256 KB, associativity = 8 L3 Unified: size = 9216 KB, associativity = 9 Memory = 32073 MB (31.321289 GB) Firmware info: Firmware revision = 9.048 FP SWA driver revision: 1.18 IPMI is supported on this system. BMC version: 4.01 Platform info: model string = "ia64 hp server rx8640" machine id number = 735d99ba-b89c-11dd-8dc7-7bbf11c4d9ad machine serial number = DEH4842HBW OS info: sysname = HP-UX nodename = server1 release = B.11.23 version = U (unlimited-user license) machine = ia64 idnumber = 1935514042 vmunix _release_version: @(#) $Revision: vmunix: B11.23_LR FLAVOR=perf Fri Aug 29 22:35:38 PDT 2003 $ |
Server does not really have 10 CPUs but “only” 4, which can be easily seen using top command and 32GB of memory.
What he saw, one morning, is quite strange:
System: server1 Thu Aug 2 15:02:01 2012 Load averages: 3.54, 2.49, 1.83 406 processes: 344 sleeping, 62 running Cpu states: CPU LOAD USER NICE SYS IDLE BLOCK SWAIT INTR SSYS 0 12.84 83.4% 0.0% 16.6% 0.0% 0.0% 0.0% 0.0% 0.0% 7 0.52 14.3% 0.0% 10.5% 75.2% 0.0% 0.0% 0.0% 0.0% 8 0.34 15.0% 0.0% 8.9% 76.1% 0.0% 0.0% 0.0% 0.0% 9 0.45 14.0% 0.0% 13.4% 72.5% 0.0% 0.0% 0.0% 0.0% --- ---- ----- ----- ----- ----- ----- ----- ----- ----- avg 3.54 31.7% 0.0% 12.3% 56.0% 0.0% 0.0% 0.0% 0.0% Memory: 12343944K (10027052K) real, 16128612K (13147636K) virtual, 13925216K free Page# 1/10 CPU TTY PID USERNAME PRI NI SIZE RES STATE TIME %WCPU %CPU COMMAND 9 ? 1158 oracle 154 20 10768M 7320K sleep 0:21 5.71 5.70 oracledb1 0 ? 2247 oracle 209 20 10767M 7404K run 0:27 4.89 4.88 ora_p039_db1 0 ? 2243 oracle 209 20 10767M 7404K run 0:23 4.86 4.85 ora_p037_db1 0 ? 2235 oracle 210 20 10767M 7404K run 0:27 4.82 4.81 ora_p033_db1 0 ? 2233 oracle 209 20 10767M 7404K run 0:19 4.81 4.80 ora_p032_db1 0 ? 2237 oracle 210 20 10767M 7404K run 0:21 4.76 4.75 ora_p034_db1 0 ? 2245 oracle 209 20 10767M 7404K run 0:18 4.74 4.73 ora_p038_db1 0 ? 2241 oracle 209 20 10767M 7404K run 0:25 4.60 4.59 ora_p036_db1 0 ? 2239 oracle 209 20 10767M 7404K run 0:29 4.58 4.57 ora_p035_db1 0 ? 18651 oracle 154 20 10774M 13756K sleep 144:07 4.25 4.25 ora_p000_db1 0 ? 18659 oracle 154 20 10774M 13756K sleep 152:52 4.06 4.05 ora_p004_db1 0 ? 4680 oracle 154 20 10769M 9452K sleep 0:02 4.18 4.02 ora_p040_db1 9 ? 26979 jboss 152 20 1408M 339M run 947:40 3.86 3.85 java 0 ? 4683 oracle 154 20 10769M 9452K sleep 0:02 3.71 3.55 ora_p041_db1 0 ? 4687 oracle 154 20 10769M 9452K sleep 0:02 3.62 3.47 ora_p043_db1 0 ? 4691 oracle 154 20 10927M 154M sleep 0:02 3.48 3.34 ora_p045_db1 0 ? 18655 oracle 154 20 10774M 13692K sleep 180:55 3.32 3.31 ora_p002_db1 0 ? 4693 oracle 154 20 10911M 142M sleep 0:02 3.35 3.21 ora_p046_db1 0 ? 4685 oracle 154 20 10769M 9452K sleep 0:02 3.28 3.14 ora_p042_db1 0 ? 4689 oracle 154 20 10911M 138M sleep 0:02 3.23 3.10 ora_p044_db1 0 ? 4695 oracle 154 20 10911M 138M sleep 0:02 3.17 3.04 ora_p047_db1 7 ? 26372 cimsrvr 152 20 69572K 16312K run 798:27 2.90 2.90 cimservermain 0 ? 18665 oracle 154 20 10776M 15612K sleep 156:17 2.85 2.84 ora_p007_db1 0 ? 18663 oracle 154 20 10776M 15676K sleep 167:17 2.82 2.81 ora_p006_db1 0 ? 18661 oracle 148 20 10776M 15504K sleep 160:01 2.73 2.73 ora_p005_db1 0 ? 18657 oracle 154 20 10775M 13756K sleep 168:40 2.72 2.71 ora_p003_db1 0 ? 18653 oracle 154 20 10774M 13820K sleep 142:55 2.69 2.69 ora_p001_db1
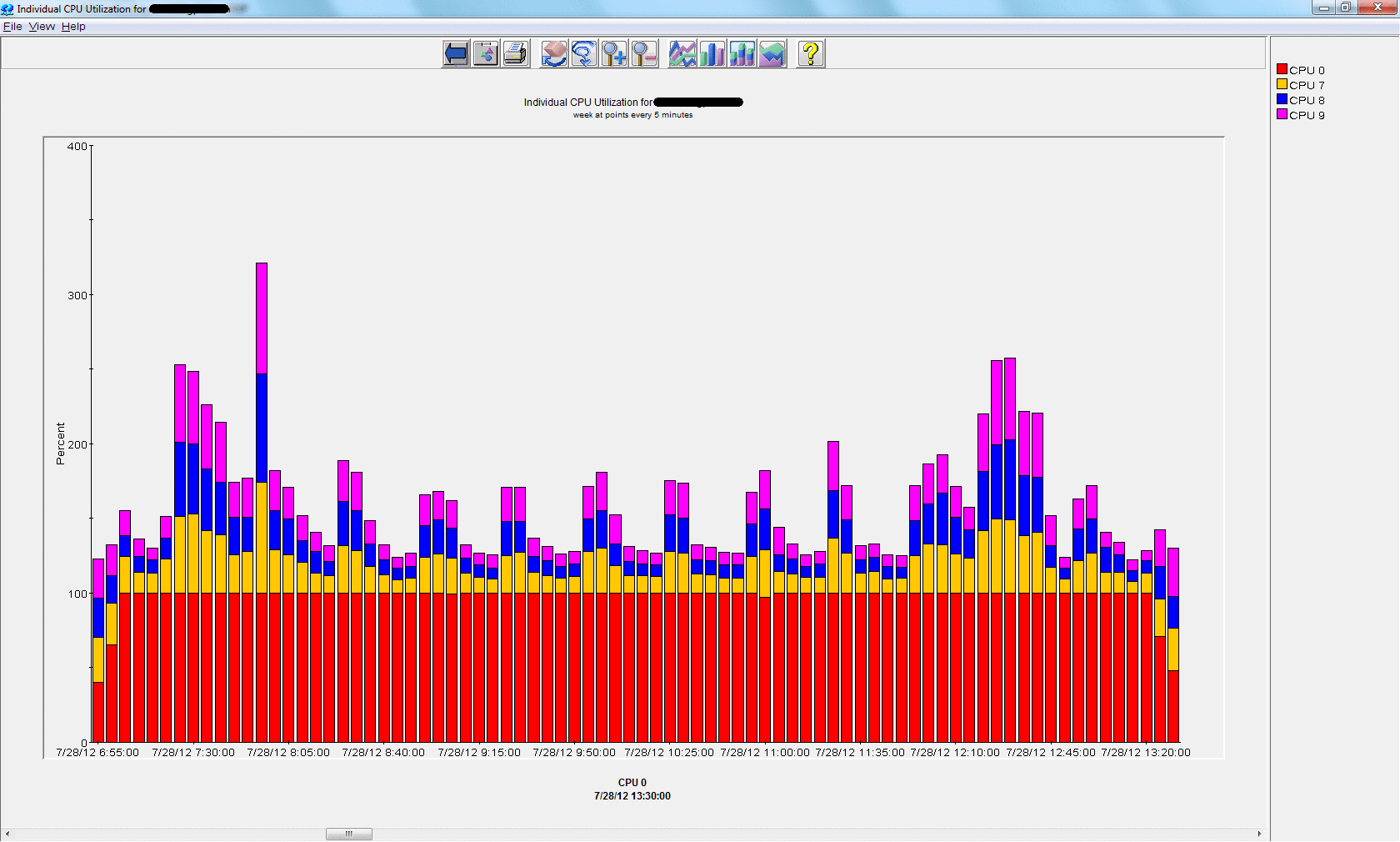
First processor is completely overloaded while other are not doing anything. I have confirmed this using HP OpenView Performance Manager (OVPM). First graph is individual CPU usage:
Second graph is global run queue:

We have set SGA_MAX_SIZE parameter to 10GB, and shmmax kernel parameter is high:
server1{root}# kctune shmmax Tunable Value Expression Changes shmmax 33631510528 0X7D4982000 Immed |
But shared memory segment are split in multiple parts which is supposed to be inefficient:
server1{root}# ipcs -ma IPC status from /dev/kmem as of Fri Aug 3 10:46:42 2012 T ID KEY MODE OWNER GROUP CREATOR CGROUP NATTCH SEGSZ CPID LPID ATIME DTIME CTIME Shared Memory: . . . m 688151 0x00000000 --rw-r----- oracle dba oracle dba 89 2745335808 18540 1904 10:46:28 10:46:29 17:29:40 m 65560 0x00000000 --rw-r----- oracle dba oracle dba 89 2734686208 18540 1904 10:46:28 10:46:29 17:29:40 m 65561 0x00000000 --rw-r----- oracle dba oracle dba 89 5303775232 18540 1904 10:46:28 10:46:29 17:29:40 m 65562 0x7a149f40 --rw-r----- oracle dba oracle dba 89 24576 18540 1904 10:46:28 10:46:29 17:29:40 . . . |
In top command, first column is CPUID and gives on which processor process is running. We notice that all parallel slave processes are running on CPU 0 so the issue. Then he went a bit further and found many interesting references about Non Uniform Memory Access (NUMA) Architecture, see references section.
Remark:
If your process is lost in multiple process list pages it could be difficult to get its CPUID. I have tried with ps command to get CPU id information but, unless I’m wrong, it is simply not possible as the output is not available, I tried pset but is is more related to PRM:
server1{root}# UNIX95= ps -o pset,pid,user,cpu,time,comm |
So I used the tips to put top command output in a file and then fetch from it:
server1{root}# top -f /tmp/top_output -n 2000 |
This first blog post is more from Oracle side, in a second part I will try to go a big deeper in OS configuration…
NUMA on HPUX Itanium
We can get how server (HPUX 11iv2) is configured using:
server1{root}# mpsched -s System Configuration ===================== Locality Domain Count: 2 Processor Count : 4 Domain Processors ------ ---------- 0 0 1 7 8 9 |
We see that our server is split in 2 cells but CPU are not equally balanced between the cells. NUMA also explain why SGA is split in multiple pieces.
The MOS notes list an incredible number of bugs (ORA-04031, high CPU usage, …) related to NUMA architecture. In HP documentation they claim that parallel processes, as well as other background processes, should be split into locality domains but this is not what I see…
Apparently release 10.2.0.4 is quite buggy versus NUMA and Oracle strongly advice to apply, at least, patch 8199533 which, in fact, deactivate Oracle NUMA support !!
It is not recommended to change _enable_NUMA_optimization and _db_block_numa hidden initialization parameters value (_enable_NUMA_support replace _enable_NUMA_optimization in 11gR2):
SQL> SET lines 150 pages 100 SQL> col description FOR a70 SQL> col PARAMETER FOR a30 SQL> col VALUE FOR a15 SQL> SELECT a.ksppinm AS parameter, c.ksppstvl AS VALUE, a.ksppdesc AS description, b.ksppstdf AS "Default?" FROM x$ksppi a, x$ksppcv b, x$ksppsv c WHERE a.indx = b.indx AND a.indx = c.indx AND LOWER(a.ksppinm) LIKE '%numa%' ORDER BY a.ksppinm; PARAMETER VALUE DESCRIPTION DEFAULT? ------------------------------ --------------- ---------------------------------------------------------------------- --------- _NUMA_instance_mapping NOT specified SET OF nodes that this instance should run ON TRUE _NUMA_pool_size NOT specified aggregate SIZE IN bytes OF NUMA pool TRUE _db_block_numa 2 NUMBER OF NUMA nodes TRUE _enable_NUMA_optimization TRUE Enable NUMA specific optimizations TRUE _rm_numa_sched_enable FALSE IS RESOURCE Manager (RM) related NUMA scheduled policy enabled TRUE _rm_numa_simulation_cpus 0 NUMBER OF cpus per PG FOR numa simulation IN RESOURCE manager TRUE _rm_numa_simulation_pgs 0 NUMBER OF PGs FOR numa simulation IN RESOURCE manager TRUE 7 ROWS selected. |
What is even pushing in NUMA deactivation is 11gR2 default behavior: NUMA is not activated by default !!:
SQL> SET lines 150 pages 100 SQL> col description FOR a70 SQL> col PARAMETER FOR a30 SQL> col VALUE FOR a15 SQL> SELECT a.ksppinm AS parameter, c.ksppstvl AS VALUE, a.ksppdesc AS description, b.ksppstdf AS "Default?" FROM x$ksppi a, x$ksppcv b, x$ksppsv c WHERE a.indx = b.indx AND a.indx = c.indx AND LOWER(a.ksppinm) LIKE '%numa%' ORDER BY a.ksppinm; PARAMETER VALUE DESCRIPTION DEFAULT? ------------------------------ --------------- ---------------------------------------------------------------------- --------- _NUMA_instance_mapping NOT specified SET OF nodes that this instance should run ON TRUE _NUMA_pool_size NOT specified aggregate SIZE IN bytes OF NUMA pool TRUE _db_block_numa 1 NUMBER OF NUMA nodes TRUE _enable_NUMA_optimization FALSE Enable NUMA specific optimizations TRUE _enable_NUMA_support FALSE Enable NUMA support AND optimizations TRUE _numa_trace_level 0 numa trace event TRUE _rm_numa_sched_enable TRUE IS RESOURCE Manager (RM) related NUMA scheduled policy enabled TRUE _rm_numa_simulation_cpus 0 NUMBER OF cpus FOR each pg FOR numa simulation IN RESOURCE manager TRUE _rm_numa_simulation_pgs 0 NUMBER OF PGs FOR numa simulation IN RESOURCE manager TRUE 9 ROWS selected. |
So potential solution for this Itanium box is either to deactivate Oracle NUMA and/or review the hardware configuration of the server and understand why cells have been configured like this…
NUMA on Linux
On my Linux box (2 eight core Xeon X7560 with 64GB of memory):
[root@server1 ~]# numactl --hardware available: 2 nodes (0-1) node 0 size: 32289 MB node 0 free: 741 MB node 1 size: 32320 MB node 1 free: 151 MB node distances: node 0 1 0: 10 20 1: 20 10 |
Looking at my hardware configuration, one motherboard and 2 sockets and 4 DDR2 memory modules I do not understand how NUMA can be in loop… This is fortunately very well explained in RedHat Performance Tuning guide.
Referring to RH442 (RedHat Tuning Training) and what we have seen on HPUX Itanium it sounds also more logic to deactivate NUMA support on Linux (In BIOS: set node interleaving or when booting set kernel option numa=off) and work with interleaved memory… There is a performance drawback but globally I rate too complex the NUMA tuning to benefit the most from this architecture.
References
- Oracle NUMA Usage Recommendation [ID 759565.1]
- High CPU Usage when NUMA enabled [ID 953733.1]
- Shared Memory Segment Is Split Up In Different Pieces With NUMA Setting [ID 429872.1]
- Enable Oracle NUMA support with Oracle Server Version 11.2.0.1 [ID 864633.1]
- Oracle Background Processes (Including Parallel Processes) Using Only First 8 CPUs (Half) on 16-CPU Server Under NUMA [ID 760705.1]
- Performance Tuning Guide (Chapter 4. CPU)
 architecture with Oracle - part 2")


 12c installation and configuration")