Table of contents
Preamble
PostgreSQL logical replication replicate data objects and their changes between two instances of PostgreSQL. PostgreSQL logical replication is the equivalent of MySQL replication and what you would achieve with GoldenGate in Oracle.
Opposite to PostgreSQL physical replication which replicate byte to byte PostgreSQL logical replication allow you to fine grained choose which objects you aim to replicate. This would target few below objectives (see official documentation for a more verbose list):
- Replicate only a subset of a database, few schemas or few objects, and allow to manage read-write other objects in parallel in another schema.
- Implement upgrade scenario between different major releases (physical replication in only between same major releases).
- Making a subset of the source database available for reporting with additional indexes for performance.
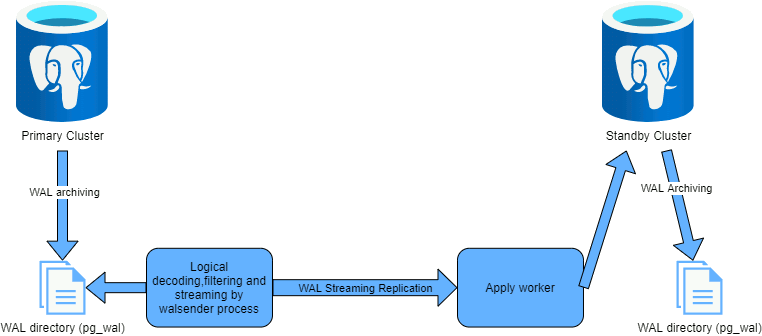
In PostgreSQL logical replication wording it works by publication on source database and subscription, to those publications, on target database:
In all logical replication technologies there is something inherent that is the presence of a primary key in the objects you plan to replicate this to easily find the corresponding rows on the target database. Not having a primary key is possible but you must understand the performance impact that could it implies…
My test environment will be made of two virtual machines:
- server3.domain.com (192.168.56.103) will be my primary server
- server4.domain.com (192.168.56.104) will be my standby server
There are both running Oracle Enterprise Linux OEL 8.4 and PostgreSQL 14.
PostgreSQL configuration
I have created two distinct PostgreSQL instance on my two servers with the below default postgresql.conf configuration file (that is initially created from the non commented out variables from default file):
listen_addresses = 'server3.domain.com' # Match server name port = 5433 archive_mode = on archive_command = 'test ! -f /postgres/arch/%f && cp %p /postgres/arch/%f' wal_level = logical # Not required on target instance max_connections = 100 # (change requires restart) shared_buffers = 128MB # min 128kB dynamic_shared_memory_type = posix # the default is the first option max_wal_size = 1GB min_wal_size = 80MB log_destination = 'stderr' # Valid values are combinations of logging_collector = on # Enable capturing of stderr and csvlog log_directory = 'log' # directory where log files are written, log_filename = 'postgresql-%a.log' # log file name pattern, log_rotation_age = 1d # Automatic rotation of logfiles will log_rotation_size = 0 # Automatic rotation of logfiles will log_truncate_on_rotation = on # If on, an existing log file with the log_line_prefix = '%m [%p] ' # special values: log_timezone = 'CET' datestyle = 'iso, mdy' timezone = 'CET' lc_messages = 'en_US.UTF-8' # locale for system error message lc_monetary = 'en_US.UTF-8' # locale for monetary formatting lc_numeric = 'en_US.UTF-8' # locale for number formatting lc_time = 'en_US.UTF-8' # locale for time formatting default_text_search_config = 'pg_catalog.english' |
One important parameter is wal_level that must be set to logical:
postgres=# show wal_level; wal_level ----------- logical (1 row) |
And depending of what you plan to implement check the value of those other parameters on published and subscriber side:
postgres=# select name,setting from pg_settings where name in ('max_replication_slots','max_wal_senders','max_worker_processes','max_logical_replication_workers');
name | setting
---------------------------------+---------
max_logical_replication_workers | 4
max_replication_slots | 10
max_wal_senders | 10
max_worker_processes | 8
(4 rows) |
I create a dedicated superuser for me as well as a replication dedicated account. I always try to avoid superuser privilege for this replication account even if it is more complex to handle:
postgres=# create role yjaquier with superuser login password 'secure_password'; CREATE ROLE postgres=# create role repuser with replication login password 'secure_password'; CREATE ROLE |
And I modify accordingly the pg_hba.conf file by adding (I coud have further restricted from where to connect with repuser by specifying exact IP address):
host all yjaquier 0.0.0.0/0 md5 host testdb repuser 192.168.56.0/24 md5 |
PostgreSQL logical replication configuration and testing
For my testing on my primary server (server3.domain.com) I create a test database and a test table with a primary key and a row inside to test the initial snapshot:
postgres=# create database testdb; CREATE DATABASE postgres=# \c testdb You are now connected to database "testdb" as user "postgres". testdb=# create table test01(id int primary key, descr varchar(20)); CREATE TABLE testdb=# insert into test01 values(1,'One'); INSERT 0 1 |
I create a publication for my test01 table (all DML, by default, will be taken into account but you can easily restrict not to duplicate delete for example):
testdb=# create publication publication01 for table test01; CREATE PUBLICATION |
There is a complete chapter in official documentation on minimum security you must apply for your dedicated PostgreSQL logical replication user and if like me your account has not superuser privilege you must give a select privilege or you get this error:
2021-11-11 12:49:26.454 CET [11474] ERROR: could not start initial contents copy for table "public.test01": ERROR: permission denied for table test01 2021-11-11 12:49:26.458 CET [9922] LOG: background worker "logical replication worker" (PID 11474) exited with exit code 1 |
So:
testdb=# grant select on test01 to repuser; GRANT |
If you plan to add more tables time to time (or if you have created the publication with FOR ALL TABLES option) you can also grant the more permissive below rights:
testdb=# grant select on all tables in schema public to repuser; GRANT |
On the target instance I initialize the test database and the definition of my test table because the schema definitions are not replicated:
postgres=# create database testdb; CREATE DATABASE postgres=# \c testdb You are now connected to database "testdb" as user "postgres". testdb=# create table test01(id int primary key, descr varchar(20)); CREATE TABLE |
On target instance create a subscription (that can also be synchronous) with:
testdb=# create subscription subscription01 testdb-# connection 'host=server3.domain.com port=5433 user=repuser dbname=testdb password=secure_password' testdb-# publication publication01; NOTICE: created replication slot "subscription01" on publisher CREATE SUBSCRIPTION |
Magically the initial loading of my first row is done:
2021-11-11 12:51:55.585 CET [11575] LOG: logical replication table synchronization worker for subscription "subscription01", table "test01" has started 2021-11-11 12:51:55.672 CET [11575] LOG: logical replication table synchronization worker for subscription "subscription01", table "test01" has finished |
Well not magically but expected:
The initial data in existing subscribed tables are snapshotted and copied in a parallel instance of a special kind of apply process. This process will create its own replication slot and copy the existing data. As soon as the copy is finished the table contents will become visible to other backends. Once existing data is copied, the worker enters synchronization mode, which ensures that the table is brought up to a synchronized state with the main apply process by streaming any changes that happened during the initial data copy using standard logical replication. During this synchronization phase, the changes are applied and committed in the same order as they happened on the publisher. Once synchronization is done, control of the replication of the table is given back to the main apply process where replication continues as normal.
And when I start to insert, update and delete rows in my source table they are obviously replicated !
PostgreSQL logical replication monitoring
Official documentation says logical replication monitoring is the same as physical replication monitoring so:
On source (publisher) instance:
postgres=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase
----------------+----------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------+-----------
subscription01 | pgoutput | logical | 16386 | testdb | f | t | 9705 | | 743 | 0/3001D10 | 0/3001D48 | reserved | | f
(1 row)
postgres=# select * from pg_publication;
oid | pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate | pubviaroot
-------+---------------+----------+--------------+-----------+-----------+-----------+-------------+------------
16394 | publication01 | 10 | f | t | t | t | t | f
(1 row)
postgres=# select * from pg_publication_tables;
pubname | schemaname | tablename
---------------+------------+-----------
publication01 | public | test01
(1 row) |
On target (subscriber) instance:
postgres=# select * from pg_stat_subscription;
subid | subname | pid | relid | received_lsn | last_msg_send_time | last_msg_receipt_time | latest_end_lsn | latest_end_time
-------+----------------+-------+-------+--------------+-------------------------------+-------------------------------+----------------+-------------------------------
16395 | subscription01 | 11262 | | 0/3001D48 | 2021-11-11 13:06:09.304963+01 | 2021-11-11 13:06:10.650019+01 | 0/3001D48 | 2021-11-11 13:06:09.304963+01
(1 row)
postgres=# select * from pg_subscription;
oid | subdbid | subname | subowner | subenabled | subbinary | substream | subconninfo | subslotname | subsynccommit | subpublications
-------+---------+----------------+----------+------------+-----------+-----------+---------------------------------------------------------------------------------------+----------------+---------------+-----------------
16395 | 16389 | subscription01 | 10 | t | f | f | host=server3.domain.com port=5433 user=repuser dbname=testdb password=secure_password | subscription01 | off | {publication01}
(1 row) |
Remark:
A bit amazed to see the password in clear in pg_subscription table. For sure the ~/.pgpass file is a must !

