Table of contents
Preamble
Always On Availability Groups or AG for short is a database level protection feature that ship every transaction to the remote (or secondary) database. This support the multi datacenter architecture and work synchronously or asynchronously. This is similar to Oracle Data Guard except that replicas can be read only with no additional Active Data Guard cost. The cluster is a kind of shared nothing cluster and the storage is exclusive to each node. No shared storage required for this feature.
Always On is an umbrella term for the availability features in SQL Server and covers both availability groups and Failover Cluster Instances. Always On is not the name of the availability group feature.
So Always On is made of:
- Always On Failover Cluster Instance (FCI) or FCI for short
- Always On Availability Group or AG for short
There is a third legacy method to duplicate for Ha databases called log shipping…
In SQL Server 2017 and 2019 due to Linux clustering software (Pacemaker) the recommended configuration for AG is made of a minimum of three replicas. The Linux clustering software is only required in the case of High Availability. If your goal is only to read scale (eCommerce solution for example) then the clustering part is not required and failover will be manual…
This blog post has been written using three virtual machine running under Virtualbox with Oracle Linux Server release 8.5 (not certified by Microsoft but similar to RedHat):
- server1.domain.com with IP address 192.168.56.101
- server2.domain.com with IP address 192.168.56.102
- server3.domain.com with IP address 192.168.56.103
Cluster nodes preparation
Configure all the SQL Server repositories as we have already seen in a previous post and install all SQL Server packages as well as Pacemaker packages on all nodes:
[root@server1 ~]# dnf install -y mssql-server [root@server1 ~]# dnf install -y mssql-tools unixODBC-devel [root@server1 ~]# dnf config-manager --enable ol8_appstream ol8_baseos_latest ol8_addons [root@server1 ~]# dnf install pacemaker pcs fence-agents-all resource-agents [root@server1 ~]# echo secure_password | passwd --stdin hacluster Changing password for user hacluster. passwd: all authentication tokens updated successfully. [root@server1 ~]# systemctl start pcsd [root@server1 ~]# systemctl enable pcsd Created symlink /etc/systemd/system/multi-user.target.wants/pcsd.service → /usr/lib/systemd/system/pcsd.service. [root@server1 ~]# systemctl enable pacemaker Created symlink /etc/systemd/system/multi-user.target.wants/pacemaker.service → /usr/lib/systemd/system/pacemaker.service. [root@server1 ~]# dnf -y install mssql-server-ha |
No more shared storage and on all nodes, as requested, I have the same local mount point for my SQL Server databases files:
[root@server1 ~]# lvcreate -n lvol01 -L 1G vg00 Logical volume "lvol01" created. [root@server1 ~]# mkfs -t xfs /dev/vg00/lvol01 meta-data=/dev/vg00/lvol01 isize=512 agcount=4, agsize=65536 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 data = bsize=4096 blocks=262144, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 [root@server1 ~]# mkdir /mssql [root@server1 ~]# mount -t xfs /dev/vg00/lvol01 /mssql [root@server1 ~]# chown -R mssql:mssql /mssql [root@server1 ~]# vi /etc/fstab [root@server1 ~]# grep mssql /etc/fstab /dev/mapper/vg00-lvol01 /mssql xfs defaults 0 0 |
As mssql user create all the required sub-directories:
[mssql@server1 ~]$ mkdir -p /mssql/data /mssql/log /mssql/dump /mssql/backup/ /mssql/masterdatabasedir/ |
As my virtual machine are using non routable IP address I pt all IP and FQDN names in /etc/hosts file on all servers:
[root@server1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.56.101 server1 server1.domain.com 192.168.56.102 server2 server2.domain.com 192.168.56.103 server3 server3.domain.com 192.168.56.99 mssqlha mssqlha.domain.com |
I have manually copied parameters setting to reach below configuration parameter (you can also use mssql-conf set on all nodes but a bit boring):
[root@server1 ~]# cat ~mssql/mssql.conf [sqlagent] enabled = false [network] tcpport = 1443 [memory] memorylimitmb = 1024 [filelocation] defaultdatadir = /mssql/data defaultlogdir = /mssql/log defaultbackupdir = /mssql/backup/ masterdatafile = /mssql/masterdatabasedir/master.mdf masterlogfile = /mssql/masterdatabasedir/mastlog.ldf defaultdumpdir = /mssql/dump [EULA] accepteula = Y |
Finally on all node I execute mssql-conf setup to configure sa account password, this command will also start the SQL Server instance::
[root@server1 ~]# /opt/mssql/bin/mssql-conf setup |
At this point you have three SQL Server distinct instance running on your three nodes !
Complete Pacemaker configuration with cluster creation and activation (as suggested either you use –force option while creating or the bullet proof pcs cluster destroy –all before creation to clean all previous trials):
[root@server1 ~]# pcs host auth server1.domain.com server2.domain.com server3.domain.com Username: hacluster Password: server1.domain.com: Authorized server3.domain.com: Authorized server2.domain.com: Authorized [root@server1 ~]# pcs cluster setup cluster01 server1.domain.com server2.domain.com server3.domain.com No addresses specified for host 'server1.domain.com', using 'server1.domain.com' No addresses specified for host 'server2.domain.com', using 'server2.domain.com' No addresses specified for host 'server3.domain.com', using 'server3.domain.com' Destroying cluster on hosts: 'server1.domain.com', 'server2.domain.com', 'server3.domain.com'... server1.domain.com: Successfully destroyed cluster server2.domain.com: Successfully destroyed cluster server3.domain.com: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'server1.domain.com', 'server2.domain.com', 'server3.domain.com' server2.domain.com: successful removal of the file 'pcsd settings' server1.domain.com: successful removal of the file 'pcsd settings' server3.domain.com: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'server1.domain.com', 'server2.domain.com', 'server3.domain.com' server1.domain.com: successful distribution of the file 'corosync authkey' server1.domain.com: successful distribution of the file 'pacemaker authkey' server2.domain.com: successful distribution of the file 'corosync authkey' server2.domain.com: successful distribution of the file 'pacemaker authkey' server3.domain.com: successful distribution of the file 'corosync authkey' server3.domain.com: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'server1.domain.com', 'server2.domain.com', 'server3.domain.com' server2.domain.com: successful distribution of the file 'corosync.conf' server1.domain.com: successful distribution of the file 'corosync.conf' server3.domain.com: successful distribution of the file 'corosync.conf' Cluster has been successfully set up. [root@server1 ~]# pcs cluster start --all server1.domain.com: Starting Cluster... server2.domain.com: Starting Cluster... server3.domain.com: Starting Cluster... [root@server1 ~]# pcs cluster enable --all server1.domain.com: Cluster Enabled server2.domain.com: Cluster Enabled server3.domain.com: Cluster Enabled [root@server1 ~]# pcs property set stonith-enabled=false [root@server1 ~]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server2.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Thu Dec 2 16:32:07 2021 * Last change: Thu Dec 2 16:32:02 2021 by root via cibadmin on server1.domain.com * 3 nodes configured * 0 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com server3.domain.com ] Full List of Resources: * No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
On all instance create a SQL Server Pacemaker login:
[mssql@server1 ~]$ cat pacemaker_login.sql create login pacemaker with password=N'Passw0rd!*'; alter server role [sysadmin] add member [pacemaker]; [mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -i pacemaker_login.sql Password: |
And store this accopunt in a secert file:
[root@server1 ~]# touch /var/opt/mssql/secrets/passwd [root@server1 ~]# echo pacemaker | sudo tee -a /var/opt/mssql/secrets/passwd pacemaker [root@server1 ~]# echo 'Passw0rd!*' | sudo tee -a /var/opt/mssql/secrets/passwd Passw0rd!* [root@server1 ~]# chown root:root /var/opt/mssql/secrets/passwd [root@server1 ~]# chmod 600 /var/opt/mssql/secrets/passwd [root@server1 ~]# cat /var/opt/mssql/secrets/passwd pacemaker Passw0rd!* |
Availability Group for High Availability (CLUSTER_TYPE = EXTERNAL)
Availability Group creation for SQL Server
On all node activate Always On Availability Groups:
[root@server1 ~]# /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1 && systemctl restart mssql-server SQL Server needs to be restarted in order to apply this setting. Please run 'systemctl restart mssql-server.service'. |
On all nodes I also activated AG extended events in case I have to debug errors:
[mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -Q 'ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);' Password: |
On my primary server, let say server1.domain.com, I create the master key and the certificate:
[mssql@server1 ~]$ cat keys.sql CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'MasterKey001!*'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = '/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = 'CertificateKey001!*' ); [mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -i keys.sql Password: [mssql@server1 ~]$ ll /mssql/data/ total 8 -rw-rw---- 1 mssql mssql 667 Dec 2 15:11 dbm_certificate.cer -rw-rw---- 1 mssql mssql 1212 Dec 2 15:11 dbm_certificate.pvk |
I then remote copy those two generated file to other server (server2.domain.com and server3.domain.com for me). Be careful of the rights if you do not use mssql account to remote copy them:
[mssql@server1 ~]$ scp /mssql/data/dbm_certificate.cer /mssql/data/dbm_certificate.pvk server2:/mssql/data/ mssql@server2's password: dbm_certificate.cer 100% 667 390.8KB/s 00:00 dbm_certificate.pvk 100% 1212 840.2KB/s 00:00 [mssql@server1 ~]$ scp /mssql/data/dbm_certificate.cer /mssql/data/dbm_certificate.pvk server3:/mssql/data/ mssql@server3's password: dbm_certificate.cer 100% 667 265.5KB/s 00:00 dbm_certificate.pvk 100% 1212 569.5KB/s 00:00 |
On secondary servers, so server2.domain.com and server3.domain.com for me, I create the master key and the certificate with:
[mssql@server2 ~]$ cat keys.sql CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'MasterKey001!*'; CREATE CERTIFICATE dbm_certificate FROM FILE = '/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'CertificateKey001!*' ); [mssql@server2 ~]$ sqlcmd -S localhost,1443 -U sa -i keys.sql Password: |
Create the database mirroring endpoint on all instances, 4022 being the default port I have chosen same as official documentation. For the encryption algorithm no particular expertise t say if another one should be chosen:
[mssql@server1 ~]$ cat endpoint.sql CREATE ENDPOINT endpoint01 AS TCP (LISTENER_PORT = 5022) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT endpoint01 STATE = STARTED; [mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -i endpoint.sql Password: |
I did not take too much attention to this warning in Microsoft documentation saying that Each SQL Server name must be 15 characters or less and unique within the network.
So when I executed below script with FQDN of server name I had below error. Specifying server name without their domain name is a bit annoying and I hope it will be enhanced in further releases:
[mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -i ag01.sql Password: Msg 35237, Level 16, State 1, Server server1, Line 1 None of the specified replicas for availability group ag01 maps to the instance of SQL Server to which you are connected. Reenter the command, specifying this server instance to host one of the replicas. This replica will be the initial primary replica. Msg 15151, Level 16, State 1, Server server1, Line 26 Cannot alter the availability group 'ag01', because it does not exist or you do not have permission. |
So finally, I have chosen to create the AG in synchronous mode but you can obviously create it in asynchronous mode. For an High Available AG you muts create it with CLUSTER_TYPE = EXTERNAL:
[mssql@server1 ~]$ cat ag01.sql CREATE AVAILABILITY GROUP ag01 WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL) FOR REPLICA ON N'server1' WITH ( ENDPOINT_URL = N'tcp://server1.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'server2' WITH ( ENDPOINT_URL = N'tcp://server2.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'server3' WITH( ENDPOINT_URL = N'tcp://server3.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ); ALTER AVAILABILITY GROUP ag01 GRANT CREATE ANY DATABASE; [mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -i ag01.sql Password: |
If you have followed the official documentation you can activate the read replica with something like:
alter availability group ag01 modify replica on N'server2' WITH (SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)); |
Once the AG is create provide additional grants to your Pacemaker database account on primary instances (server1.domain.com for me):
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag01 TO pacemaker; GRANT VIEW SERVER STATE TO pacemaker; go |
On all secondary replicas join the AG and when done also grant Pacemaker account with those additional rights:
ALTER AVAILABILITY GROUP ag01 JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP ag01 GRANT CREATE ANY DATABASE; GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag01 TO pacemaker; GRANT VIEW SERVER STATE TO pacemaker; go |
On your master instance (server1.domain.com) create a test database, change recovery mode to full, backup it:
CREATE DATABASE testdb; ALTER DATABASE testdb SET RECOVERY FULL; BACKUP DATABASE testdb TO DISK = N'/mssql/backup/testdb.bak'; |
Add it to your AG with:
ALTER AVAILABILITY GROUP ag01 ADD DATABASE testdb; go |
You can control with SSMS that all looks good:
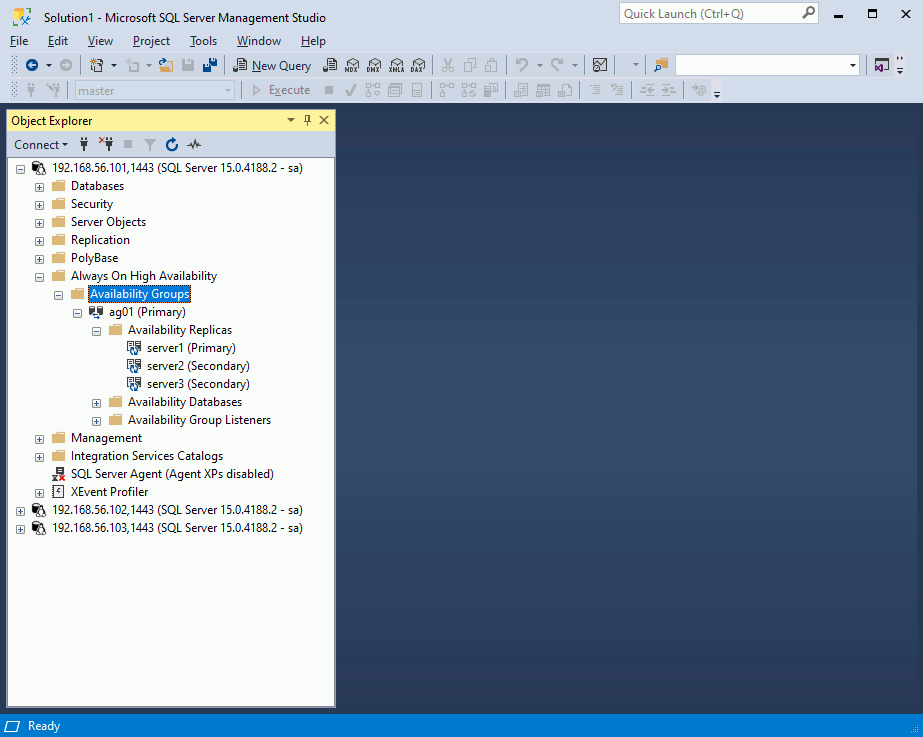
On my two replicas I can now see:
1> SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states; 2> go database synchronization_state_desc -------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------ testdb SYNCHRONIZED (1 rows affected) |

Other useful SQLs:
select * from sys.availability_replicas; select * from sys.availability_groups; select DB_NAME(database_id) AS 'database', synchronization_state_desc,a.* from sys.dm_hadr_database_replica_states a; |
To test you can access replicas in read mode you can create this test database and table on primary instance:
use testdb; create table test01(id int, descr varchar(50)); insert into test01 values(1,'One'); |
Availability Group creation for Pacemaker Linux
Having a cluster manager (so Pacemaker in case of Linux) to manage automatic failure and automatic failover is mandatory to have an High Available cluster. So you availability group must be of type CLUSTER_TYPE=EXTERNAL.
As suggested in official documentation I have set those default parameters:
[root@server1 ~]# pcs property set cluster-recheck-interval=2min [root@server1 ~]# pcs property set start-failure-is-fatal=true |
Creation of the AG:
[root@server1 ~]# pcs resource create ag01 ocf:mssql:ag ag_name=ag01 meta failure-timeout=60s promotable notify=true port=1443 [root@server1 ~]# pcs resource update ag01 meta failure-timeout=60s |
Creation of the virtual IP:
[root@server1 ~]# pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=192.168.56.99 |
Collocation of the resources (your virtual IP must follow the read/write database:):
[root@server1 ~]# pcs constraint colocation add virtualip with master ag01-clone INFINITY with-rsc-role=Master [root@server1 ~]# pcs constraint order promote ag01-clone then start virtualip Adding ag01-clone virtualip (kind: Mandatory) (Options: first-action=promote then-action=start) |
I had the (usual) issue with non default port so, when creating the AG, you must specify the non default port or you update it afterwards. Error can be seen in Pacemaker log file (/var/log/pacemaker/pacemaker.log). Even if I had specify it when creating the Ag resource it has not been taken into account so had to overwrite with below command:
[root@server1 ~]# pcs resource describe ocf:mssql:ag . . . [root@server1 ~]# pcs resource update ag01 port=1443 |
To create the moving Virtual IP you would use (but I have not been able to go to this step):
pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=192.168.56.99 cidr_netmask=32 nic=enp0s3 op monitor interval=30s |
My Pacemaker clsuter has always been in this error state:
[root@server1 mssql]# pcs status Cluster name: cluster01 Cluster Summary: * Stack: corosync * Current DC: server3.domain.com (version 2.1.0-8.0.1.el8-7c3f660707) - partition with quorum * Last updated: Tue Dec 14 17:16:34 2021 * Last change: Tue Dec 14 12:29:14 2021 by root via cibadmin on server1.domain.com * 3 nodes configured * 3 resource instances configured Node List: * Online: [ server1.domain.com server2.domain.com server3.domain.com ] Full List of Resources: * Clone Set: ag01-clone [ag01] (promotable): * ag01 (ocf::mssql:ag): FAILED server3.domain.com (Monitoring) * ag01 (ocf::mssql:ag): FAILED server1.domain.com (Monitoring) * ag01 (ocf::mssql:ag): FAILED server2.domain.com (Monitoring) Failed Resource Actions: * ag01_monitor_11000 on server3.domain.com 'not running' (7): call=6164, status='complete', exitreason='', last-rc-change='2021-12-14 17:16:27 +01:00', queued=0ms, exec=5613ms * ag01_monitor_10000 on server1.domain.com 'not running' (7): call=6163, status='complete', exitreason='', last-rc-change='2021-12-14 17:16:32 +01:00', queued=5362ms, exec=5379ms * ag01_monitor_10000 on server2.domain.com 'not running' (7): call=6160, status='complete', exitreason='', last-rc-change='2021-12-14 17:16:32 +01:00', queued=5354ms, exec=5422ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled |
I have solved one error when checking in /var/log/messages (grep ‘A connection timeout’ /var/log/messages if you want to know if you also hit it):
Dec 3 14:24:23 server1 sqlservr[67331]: #0152021-12-03 13:24:23.24 spid29s A connection timeout has occurred while attempting to establish a connection to availability replica 'server2' with id [29DF8EBA-359E-4601-9D5E-41BFC4A85C99]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance. |
If you check running processes to monitor your SQL Server instance you should see (this is rotating quite fast):
[root@server1 ~]# ps -ef | grep sql mssql 991 1 0 10:16 ? 00:00:03 /opt/mssql/bin/sqlservr mssql 4251 991 3 10:18 ? 00:08:37 /opt/mssql/bin/sqlservr root 210862 204375 0 14:35 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/ag monitor root 210905 210862 0 14:35 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/ag monitor root 210906 210905 0 14:35 ? 00:00:00 /usr/lib/ocf/lib/mssql/ag-helper --hostname --port 1443 --credentials-file /var/opt/mssql/secrets/passwd --ag-name ag01 --application-name monitor-ag01-monitor --connection-timeout 30 --health-threshold 3 --action monitor --required-synchronized-secondaries-to-commit -1 --current-master server2.domain.com --disable-primary-on-quorum-timeout-after 60 --primary-write-lease-duration 72 --monitor-interval-timeout 60 root 210907 210905 0 14:35 ? 00:00:00 /bin/bash /usr/lib/ocf/resource.d/mssql/ag monitor root 210947 12866 0 14:35 pts/0 00:00:00 grep --color=auto sql |
Notice the –hostname –port 1443 where the hostname is missing. If you try it you see that parameter value is clearly missing::
[root@server1 ~]# /usr/lib/ocf/lib/mssql/ag-helper --hostname --port 1443 --credentials-file /var/opt/mssql/secrets/passwd --ag-name ag01 --application-name monitor-ag01-monitor --connection-timeout 30 --health-threshold 3 --action monitor --required-synchronized-secondaries-to-commit -1 --current-master server2.domain.com --disable-primary-on-quorum-timeout-after 60 --primary-write-lease-duration 74 --monitor-interval-timeout 60 2021/12/06 15:01:30 ag-helper invoked with hostname [--port]; port [0]; ag-name []; credentials-file []; application-name []; connection-timeout [30]; health-threshold [3]; action [] ERROR: 2021/12/06 15:01:30 Unexpected error: a valid port number must be specified using --port |
If you check in /usr/lib/ocf/resource.d/mssql/ag you will see that the part to get hostname is:
mssql_conf="/var/opt/mssql/mssql.conf" if [ -f $mssql_conf ]; then hostname=$(sed -n -e '/^\s*\[network]\s*/I,/\s*ipaddress\s*=./I {s/^\s*ipaddress\s*=\s*\(.*\)/\1/I p}' $mssql_conf) fi |
To solve it set server IP adress to crrect vlue on all your cluster nodes with:
[root@server1 ~]# /opt/mssql/bin/mssql-conf set network.ipaddress 192.168.56.101 SQL Server needs to be restarted in order to apply this setting. Please run 'systemctl restart mssql-server.service'. |
Process should have after the correct hostname parameter value:
root 318702 318701 0 15:33 ? 00:00:00 /usr/lib/ocf/lib/mssql/ag-helper --hostname 192.168.56.101 --port 1443 --credentials-file /var/opt/mssql/secrets/passwd --ag-name ag01 --application-name monitor-ag01-monitor --connection-timeout 30 --health-threshold 3 --action monitor --required-synchronized-secondaries-to-commit -1 --current-master server2.domain.com --disable-primary-on-quorum-timeout-after 60 --primary-write-lease-duration 74 --monitor-interval-timeout 60 |
To try to go further I have tried to manually execute the ag monitor command:
[root@server1 ~]# /bin/bash /usr/lib/ocf/resource.d/mssql/ag monitor /usr/lib/ocf/resource.d/mssql/ag: line 46: /resource.d/heartbeat/.ocf-shellfuncs: No such file or directory /usr/lib/ocf/resource.d/mssql/ag: line 672: ocf_log: command not found /usr/lib/ocf/resource.d/mssql/ag: line 681: ocf_log: command not found /usr/lib/ocf/resource.d/mssql/ag: line 682: ocf_log: command not found /usr/lib/ocf/resource.d/mssql/ag: line 700: check_binary: command not found /usr/lib/ocf/resource.d/mssql/ag: line 711: ocf_exit_reason: command not found /usr/lib/ocf/resource.d/mssql/ag: line 712: return: : numeric argument required /usr/lib/ocf/resource.d/mssql/ag: line 770: ocf_log: command not found [root@server1 ~]# export OCF_ROOT=/usr/lib/ocf/ [root@server1 ~]# /bin/bash /usr/lib/ocf/resource.d/mssql/ag monitor INFO: mssql_validate INFO: OCF_RESKEY_CRM_meta_interval value: 0 INFO: OCF_RESKEY_CRM_meta_timeout value: ocf-exit-reason:Resource must be configured with notify=true INFO: Resource agent invoked with: monitor |
But I did specify notify=true when create the AG pacemaker resource…
And I have not been able to go further… I have tried to debug the AG with pcs resource debug-start ag01, not of good help. I have also tried to move back my instances to default 1433 listening port but again failing. Might be because I’m on Oracle Linux and not RedHat/Ubuntu so any feedback in comment section is appreciated…
For reference my config:
[root@server2 ~]# pcs config Cluster Name: cluster01 Corosync Nodes: server1.domain.com server2.domain.com server3.domain.com Pacemaker Nodes: server1.domain.com server2.domain.com server3.domain.com Resources: Clone: ag01-clone Meta Attrs: notify=true port=1443 promotable=true Resource: ag01 (class=ocf provider=mssql type=ag) Attributes: ag_name=ag01 port=1443 Meta Attrs: failure-timeout=60s notify=true Operations: demote interval=0s timeout=10 (ag01-demote-interval-0s) monitor interval=10 timeout=60 (ag01-monitor-interval-10) monitor interval=11 role=Master timeout=60 (ag01-monitor-interval-11) monitor interval=12 role=Slave timeout=60 (ag01-monitor-interval-12) notify interval=0s timeout=60 (ag01-notify-interval-0s) promote interval=0s timeout=60 (ag01-promote-interval-0s) start interval=0s timeout=60 (ag01-start-interval-0s) stop interval=0s timeout=10 (ag01-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Ordering Constraints: Colocation Constraints: Ticket Constraints: Alerts: No alerts defined Resources Defaults: No defaults set Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: cluster01 cluster-recheck-interval: 2min dc-version: 2.1.0-8.0.1.el8-7c3f660707 have-watchdog: false last-lrm-refresh: 1638801533 start-failure-is-fatal: true stonith-enabled: false Tags: No tags defined Quorum: Options: |
And the failed status of the AG:
[root@server1 ~]# pcs resource status ag01 * Clone Set: ag01-clone [ag01] (promotable): * ag01 (ocf::mssql:ag): Master server1.domain.com (Monitoring) * ag01 (ocf::mssql:ag): FAILED server2.domain.com (Monitoring) * ag01 (ocf::mssql:ag): FAILED server3.domain.com (Monitoring) |
Availability Group for Read Scale (CLUSTER_TYPE = NONE)
Availability Group creation for SQL Server
As said, this type of AG does not support High Availability but you will be able to scale your read queries to those replica(s). The AG will be of type CLUSTER_TYPE=NONE and you will be able to failover without and with data loss manually, from SQL Server, onto one of your read replica.
I have already my three nodes cluster. Destroy the Pacemaker part with pcs cluster destroy –all and clean the AG and your test database (that is most probably in a strange state) from SQL Server with, for example, SSMS. All the other parts of the configuration like endpoint, certificates and AlwaysOn_health event session remain the same !
One bonus of this type of AG is that you can mix Linux and Windows nodes so could be a very nice option to migrate from Windows to Linux or vice versa…
My AG creation script is (execute it on your primary server):
CREATE AVAILABILITY GROUP ag01 WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'server1' WITH ( ENDPOINT_URL = N'tcp://server1.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'server2' WITH ( ENDPOINT_URL = N'tcp://server2.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'server3' WITH( ENDPOINT_URL = N'tcp://server3.domain.com:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ); ALTER AVAILABILITY GROUP ag01 GRANT CREATE ANY DATABASE; |
On all replicas execute the AG join command:
ALTER AVAILABILITY GROUP ag01 JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP ag01 GRANT CREATE ANY DATABASE; |
On primary instance create a test database and table:
CREATE DATABASE testdb; ALTER DATABASE testdb SET RECOVERY FULL; BACKUP DATABASE testdb TO DISK = N'/mssql/backup/testdb.bak'; |
On the primary, add the database to the AG (alter availability group ag01 remove database testdb; to remove it):
ALTER AVAILABILITY GROUP ag01 ADD DATABASE testdb; |
Create a test table on the pirmary and check you can access it, in read only mode on any of your replicas:
USE testdb; CREATE TABLE test01(id INT, descr VARCHAR(50)); INSERT INTO test01 VALUES(1,'One'); |
Manual failover without data loss
As I have created my AG in synchronous mode I should have no issue but check it with below query:
[mssql@server1 ~]$ cat sync_state.sql SELECT ag.name, dbs.name, drs.group_id, ar.replica_server_name, ars.role_desc, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag, sys.databases dbs, sys.availability_replicas ar, sys.dm_hadr_availability_replica_states ars WHERE drs.group_id = ag.group_id AND dbs.database_id = drs.database_id AND ar.replica_id = drs.replica_id AND ars.replica_id = drs.replica_id; [mssql@server1 ~]$ sqlcmd -S localhost,1443 -U sa -P 'secure_password' -i sync_state.sql -y 30 -Y 30 name name group_id replica_server_name role_desc synchronization_state_desc sequence_number ------------------------------ ------------------------------ ------------------------------------ ------------------------------ ------------------------------ ------------------------------ -------------------- ag01 testdb F6EC8225-BFFB-BB34-4FC4-09CBFB531DED server1 PRIMARY SYNCHRONIZED 17179869203 ag01 testdb F6EC8225-BFFB-BB34-4FC4-09CBFB531DED server2 SECONDARY SYNCHRONIZED 17179869203 ag01 testdb F6EC8225-BFFB-BB34-4FC4-09CBFB531DED server3 SECONDARY SYNCHRONIZED 17179869203 (3 rows affected) |
On primary server ensure at least one replica is in synchronized state and put the AG in offline mode:
ALTER AVAILABILITY GROUP ag01 SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1); ALTER AVAILABILITY GROUP ag01 OFFLINE; |
On the secondary you’d like to promote:
ALTER AVAILABILITY GROUP ag01 FORCE_FAILOVER_ALLOW_DATA_LOSS; |
Remark:
I initially thought there was an error as I would have used FAILOVER but it is not yet support:
Msg 47122, Level 16, State 1, Server server1, Line 1 Cannot failover an availability replica for availability group 'ag01' since it has CLUSTER_TYPE = NONE. Only force failover is supported in this version of SQL Server. |
On the old primary set state to secondary, despite what is depicting the official documentation I also had to execute it on replicas that remained with secondary role:
ALTER AVAILABILITY GROUP ag01 SET (ROLE = SECONDARY); |
They say that on new primary you need to resume replication but my replicas remained in NOT SYNCHRONIZING so I had to issue this command on all secondary replicas:
ALTER DATABASE testdb SET HADR RESUME; |
References
- Business continuity and database recovery – SQL Server on Linux
- SQL Server 2019 : Always On Availability Group
- Choose an Encryption Algorithm
- Configure extended events for Always On availability groups






geek says:
“Wow, I was struggling with setting up Always On Availability Groups for SQL Server on Linux, and this guide was exactly what I needed! The steps are clear, and it was so helpful to have the detailed explanations of the cluster setup and SQL Server configurations. I also appreciate how the blog walks through the process in an easy-to-understand way, even for someone like me who’s not super experienced with clustering. Big thanks for this post! It saved me a ton of time. If you’re working on server management, you should also check out [Install Cockpit on Debian 12](https://docs.vultr.com/how-to-install-cockpit-on-debian-12) for more helpful tips!”
sai sumanth says:
pcs resource create ag_cluster ocf:mssql:ag ag_name=sqlavail meta failure-timeout=60s promotable notify=true –future
pcs constraint colocation add virtual_ip with Promoted ag_cluster-clone INFINITY with-rsc-role=Promoted
pcs constraint order promote ag_cluster-clone then start virtual_ip
first above 2 cmds are changed little compared to microsoft docs or any public blogger docs are provided cmds due to new pcs version has depricated those options like master .
thank for article learned more on pcs then sql server.
jason says:
Hi Again
I have a question , in creating the pcs resource how can we specify a dns address . (like cluster.example.com)
I tried this and it does not work.
#pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=web-sqldb.masarfinance.com
Yannick Jaquier says:
Hi,
I do not have my test environment anymore but here I guess if the parameter is ip=xx then you have to specify an IP address. This IP address can obviously be a virtual one resolving a virtual generic name in your DNS…
Jason says:
Hi
I followed your article , I believe the failover is the issue only. From microsoft article “https://learn.microsoft.com/en-us/sql/linux/sql-server-linux-availability-group-configure-ha?view=sql-server-ver16” ,
>>>>
After you configure the cluster and add the AG as a cluster resource, you can’t use Transact-SQL to fail over the AG resources. SQL Server cluster resources on Linux aren’t coupled as tightly with the operating system as they are on a Windows Server Failover Cluster (WSFC). SQL Server service isn’t aware of the presence of the cluster. All orchestration is done through the cluster management tools. In RHEL or Ubuntu use pcs. In SLES use crm.
<<<
Lincoln says:
Hi Yannick , how are you?
Did you have success in Pacemaker cluster configuration? I’am facing exactly the same problema while configuring Always On Availability Group on RedHat 9.
Thanks.
Yannick Jaquier says:
Hi Lincoln,
Fine, hope you are also well !
I have not been further in testing beyond those academic posts.
Thanks for your return of experience on RedHat ! Is it with SQL Server 2019 or SQL Server 2022 ? If SQL Server 20222 it seems that Microsoft has not yet corrected their bug… If not worth trying latest release, there is an hope they have made it working in latest release…
Lincoln says:
Hello Yannick,
Thank you for your reply!
Just to give you some feedback, I provisioned another environment built with 3 nodes Ubuntu 22.04 + SQL Server 2022 + PaceMaker, and it worked great.
I give up on the older environment with RedHat9 + SQL Server 2022.
Thank you so much!
Yannick Jaquier says:
Hello Lincoln,
Thanks for sharing your experience !
So the problem was RedHat related and not SQL Server related as you were already using SQL Server 2022… 🙁
One problem I see with Ubuntu is that it is not a Linux often used in datacenter…
sai sumanth says:
pcs resource create ag_cluster ocf:mssql:ag ag_name=sqlavail meta failure-timeout=60s promotable notify=true –future
pcs constraint colocation add virtual_ip with Promoted ag_cluster-clone INFINITY with-rsc-role=Promoted
pcs constraint order promote ag_cluster-clone then start virtual_ip
first above 2 cmds are changed little compared to microsoft docs or any public blogger docs are provided cmds due to new pcs version has depricated those options like master .
Execute in Primary node:ag_cluster is pacemaker cluster resource name, sqlavail = ag group in SQL, virtual_ip is resource created for DNS IP,
DNS name was created using ALTER AVAILABILITY GROUP ag ADD LISTENER tsql cmd.
thank for article learned more on pcs then sql server.
this worked for me in rhel 9