Table of contents
Preamble
In previous post we have seen how to configure a Couchbase server in cluster mode and configure it to act as a Memcached global pool.
I keep what we have done in first post and now I add a MySQL server: server1.domain.com using non routable IP 192.168.56.101. The Java application will run on my desktop that is also the host for all virtual machines.
Couchbase server as Memcached drop-in replacement
I have used the exact same code and I have to say that marketing slides were true: no change at all and the code is working exactly the same.
Well to be honest I have changed one line to tell my Java application how many nodes I have in my cluster:
MemcachedClient c=new MemcachedClient(new BinaryConnectionFactory(), AddrUtil.getAddresses("192.168.56.102:11211 192.168.56.103:11211")); |
The funny thing is that even if you do not do it, means specify only the first node, the load is balanced over all nodes of your cluster…
I am not much entering into small details as behavior is exactly the same as with Memcached. The MySQL server is less and less loaded and application response time is increasing (1000 gets on customers table per run) along Memcached hit ratio…
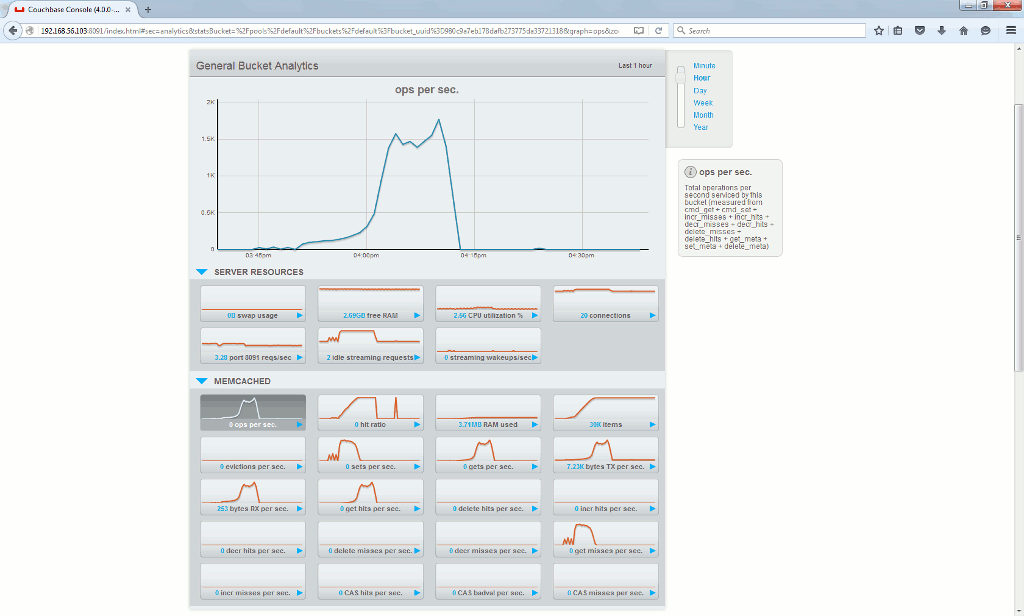
The couchbase server graphical interface provide quite a lot of useful graphics, default (Memcached) bucket in Data Buckets tab:
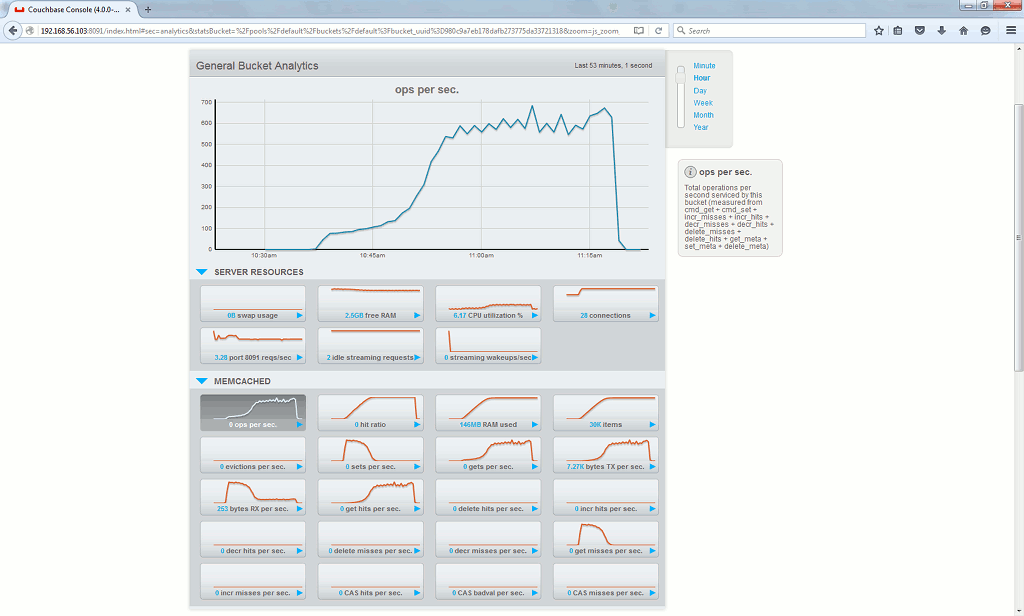
The interesting ones in particular are ops per second, hit ratio, RAM usage…
Couchbase server high availability testing
One of the most interesting feature that could trigger a move from Memcached to Couchbase server is the high availability feature.
If I stop server2.domain.com:
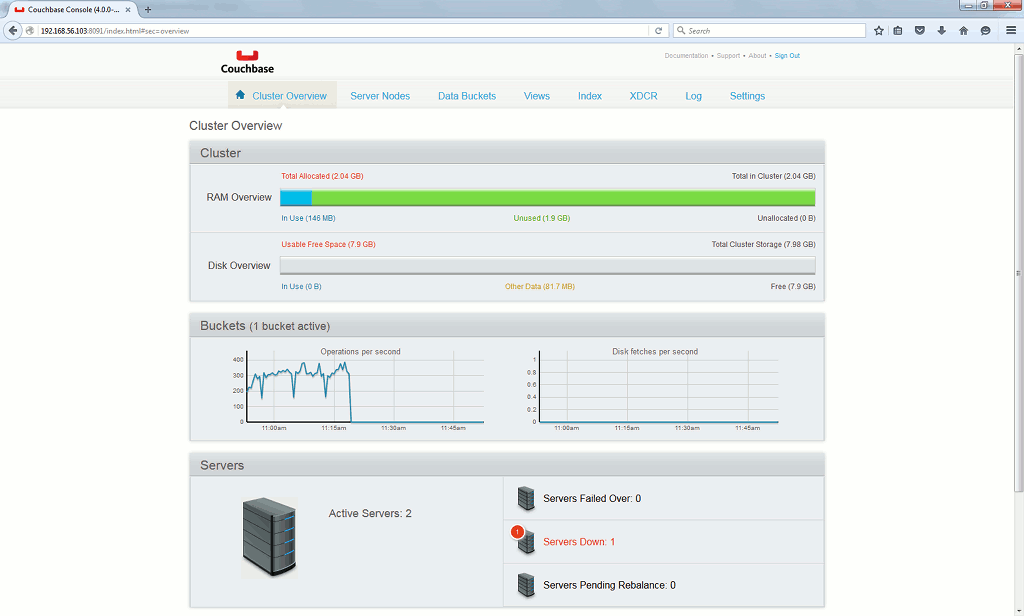
The application is not working anymore, I have to failover the server that is down. On Server Nodes tab I click on Fail Over button for down server:
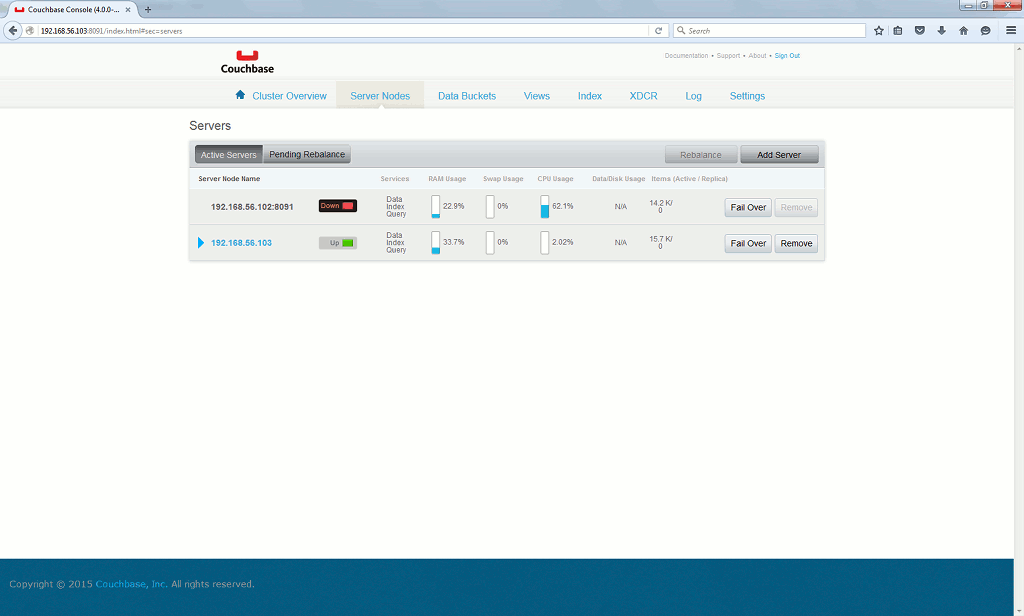
Then the application is again working, even if I loose half of my cache so performance impact is expected…
When the down server is back to life I click on Full Recovery:
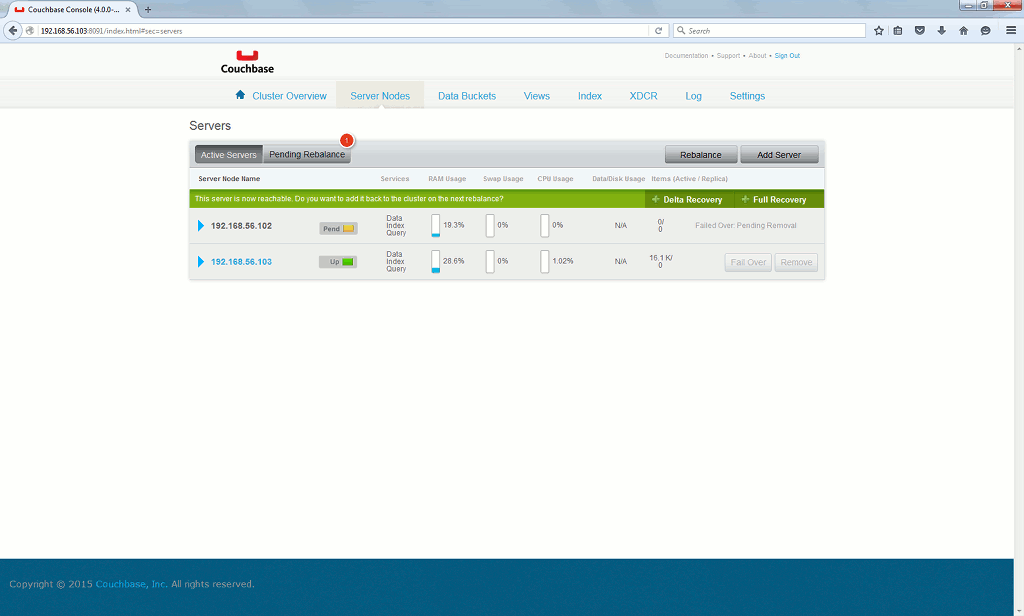
Then you just need to rebalance your Memcached bucket:

An everything is back to normal situation:
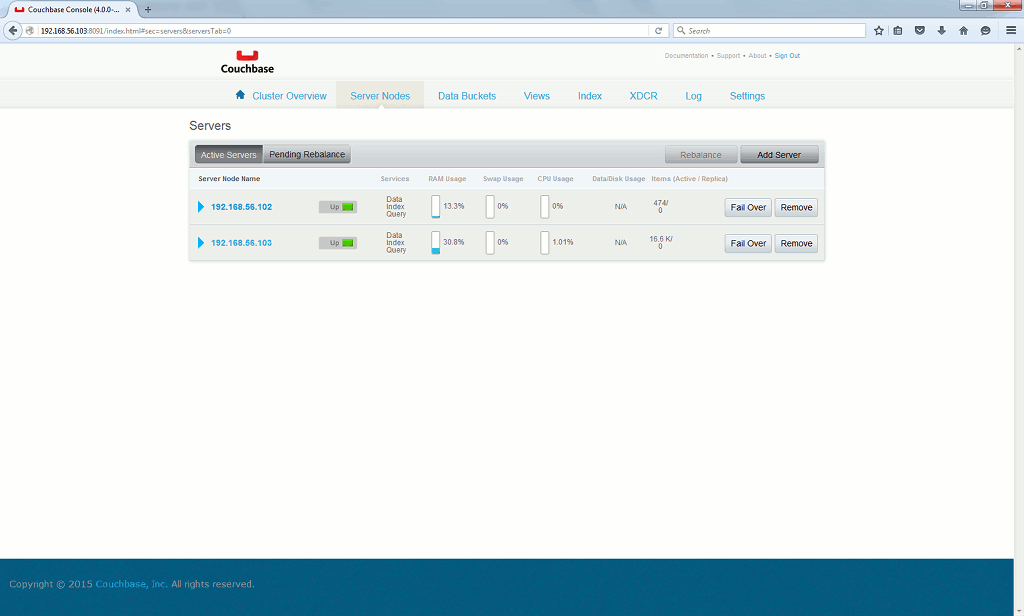
Of course in real life you will not be there in the middle of the night to do this, that’s why the auto-failover option is quite interesting. 30 seconds is the minimum:
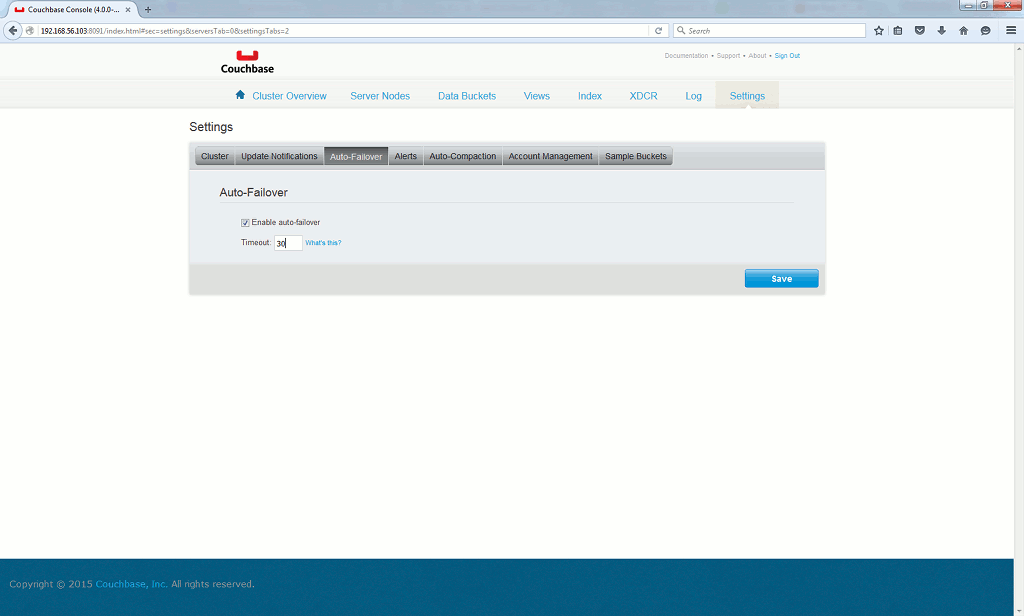
Due to deliberate limitations a minimum of three servers is required to have auto-failover working (and this for only one node). As it is really easy to setup a new Couchbase server I have created a fouth virtual machine (server4.domain.com using non routable IP address 192.168.56.104). Once a node is down you have this normal screen:
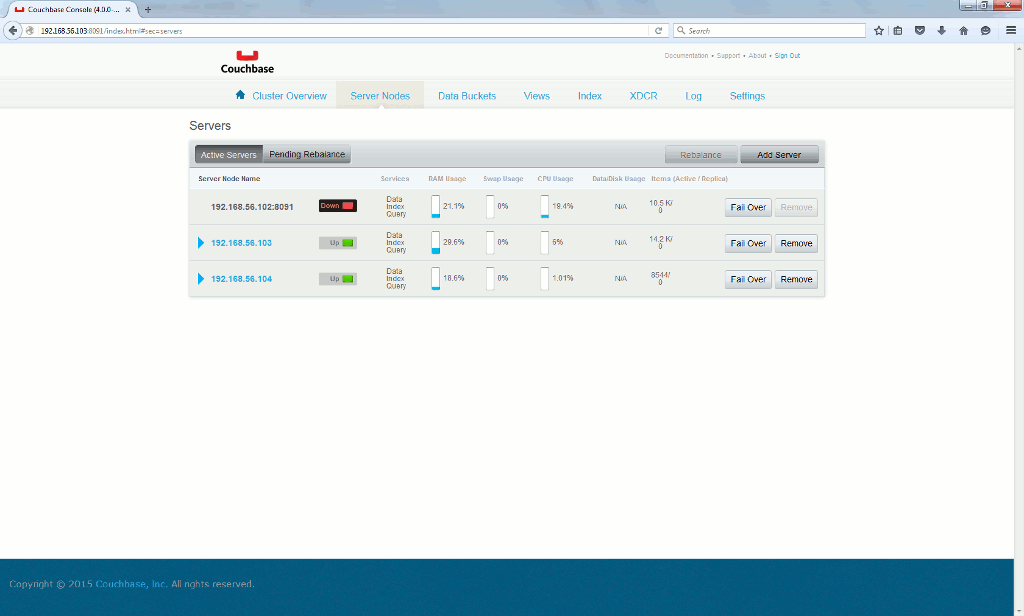
And after 30 seconds the node is automatically failed over:
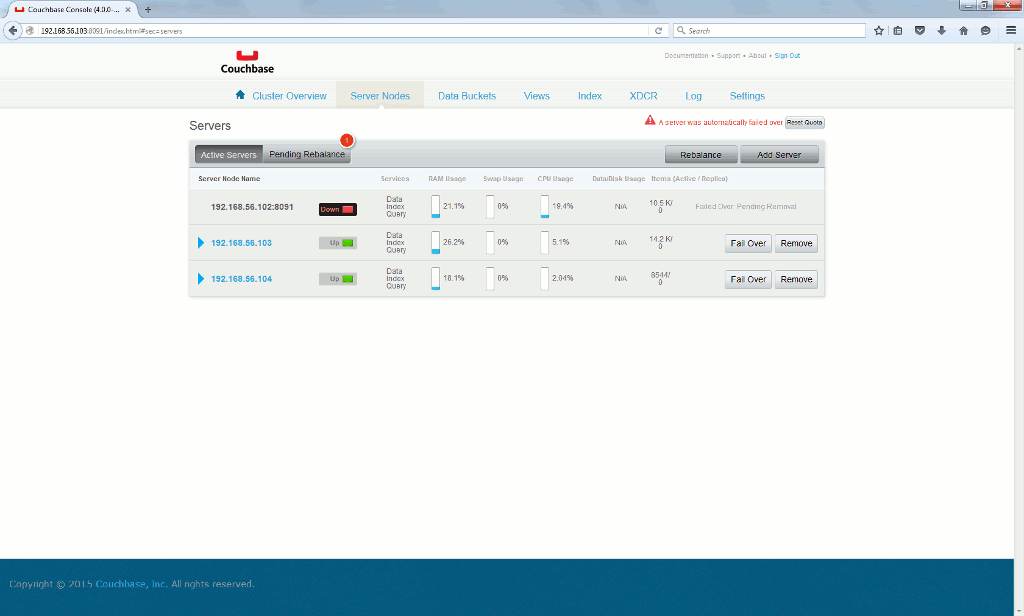
Means that after the automatic failover your application is behaving normally, but still I rate this is not satisfactory as you might have 30 long seconds where your application is not working… So wondering if the Couchbase Java SDK 2.2 is not better handling this node failure. But this would mean rewriting the application…
Couchbase Server Java SDK 2.2
The idea is to see if when a node is down your application can continue working. I have re-written using Couchbase Server Java SDK 2.2 the small application written for Memcached testing and this is transparently working with Couchbase Server acting as a cluster Memcached:
package jdbcdemo6; // MD5 import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; //MySQL client import com.mysql.jdbc.Driver; import java.util.Properties; import java.sql.ResultSet; import java.sql.Connection; import java.sql.SQLException; import java.util.Random; import java.util.concurrent.TimeUnit; //Couchbase client import com.couchbase.client.java.*; import com.couchbase.client.java.document.JsonDocument; import com.couchbase.client.java.document.json.JsonObject; public class jdbcdemo6 { private static String MD5encode(String string1) { String md5=null; if (string1 == null) return null; try { MessageDigest digest1 = MessageDigest.getInstance("MD5"); byte[] hash = digest1.digest(string1.getBytes()); StringBuilder sb = new StringBuilder(2*hash.length); digest1.update(string1.getBytes()); for(byte b : hash) { sb.append(String.format("%02x", b&0xff)); } md5=sb.toString(); } catch (NoSuchAlgorithmException e) { e.printStackTrace(); } return md5; } public static void main(String[] args) throws Exception { Driver driver = new Driver(); Properties props = new Properties(); ResultSet rs; Connection conn = null; String JDBC_URL = "jdbc:mysql://192.168.56.101:3322", query1, query1_md5; Random generator = new Random(); JsonDocument document1=null; JsonObject object1=null; int in_couchbase=0, not_in_couchbase=0, id; // Connect to a Couchbase cluster Cluster cluster = CouchbaseCluster.create("192.168.56.102", "192.168.56.103", "192.168.56.104"); Bucket bucket=cluster.openBucket("default"); long start_time = System.currentTimeMillis(); props.put("user","yjaquier"); props.put("password","secure_password"); System.out.println("------------ MySQL Connector/J JDBC connection testing ------------\n"); System.out.println("Trying connection...\n"); // Get JDBC connection try { conn = driver.connect(JDBC_URL, props); } catch (SQLException e) { e.printStackTrace(); System.exit(1); } // Looping and executing queries and try to get first the result from Couchbase server for(int i=1; i <= 1000; i++) { id=generator.nextInt(30000) + 1; System.out.print("\nQuery "+i+" for id="+id+", "); query1="SELECT firstname,lastname FROM test.customers where id="+id; query1_md5=MD5encode(query1); try { document1=bucket.get(query1_md5, 5, TimeUnit.SECONDS); } catch (RuntimeException e) { System.out.println("Couchbase server timeout..."); } if (document1==null) { System.out.print("Query result not in Couchbase, "); not_in_couchbase++; rs = conn.createStatement().executeQuery(query1); while (rs.next()) { System.out.print("customer : " + rs.getString("firstname")+", "+rs.getString("lastname")); object1=JsonObject.empty().put("firstname", rs.getString("firstname")).put("lastname", rs.getString("lastname")); bucket.upsert(JsonDocument.create(query1_md5, object1)); } rs.close(); } else { System.out.print("Query result in Couchbase, "); in_couchbase++; System.out.print("customer : " + document1.content().getString("firstname")+", "+document1.content().getString("lastname")); } } System.out.println("\nExiting..."); if (conn != null) { conn.close(); } long end_time = System.currentTimeMillis(); System.out.println("Executed in " + (end_time - start_time) + " milliseconds"); System.out.println("Percentage in Couchbase "+Math.round(in_couchbase*100/(in_couchbase+not_in_couchbase))+"% ("+in_couchbase+"), not in Couchbase "+ Math.round(not_in_couchbase*100/(in_couchbase+not_in_couchbase))+"% ("+not_in_couchbase+")"); } } |
All is working fine and I would even say even faster, number of IOPS has been multiplied by 3 and JSON storage I have used is consuming much less memory:
But the failover action of the failed node is still required to have the application continue working… So a bit disappointed on this point… I had a look on Internet and many people are complaining about this. One of the advise is to manage that at application level but as stated by many application code is not the place to deal with cluster management commands…